


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
文章介绍
原文地址:https://www.shockwave.cloud/blog/shockwave-works-with-openai-to-fix-critical-chatgpt-vulnerability
原文作者:Gal Nagli
翻译作者:a1batr0ss(信天翁)
注:文章非机翻,均为作者凭借其 网络安全的专业功底 和 托福90+的英语功底 认真翻译。如在阅读时发现翻译错误或不通顺,欢迎私信提出问题,不胜感激
翻译正文
漏洞背景
我公司的同事们已经和OpenAI团队合作修复了一个有关ChatGPT的漏洞,该漏洞通过Web缓存欺骗实现了对ChatGPT账号的接管。这似乎是第一个影响了世界上最具创新产品(ChatGPT)这么多版本的基于Web的漏洞。
OpenAI 团队几个小时前刚刚修复了一个我上报的影响ChatGPT的严重账号接管漏洞。这个漏洞可能会让攻击者在受害者不知情的情况下接管他们的账号、查看他们与ChatGPT的聊天记录、并且访问他们的账单信息。
这个漏洞是“Web缓存欺骗”,我将详细解释我是如何绕过https://chat.openai.com上的保护措施的。需要注意的是,这个漏洞已经得到修复,我也因我的负责任的披露收到了@OpenAI团队的“赞扬”邮件。

攻击分析
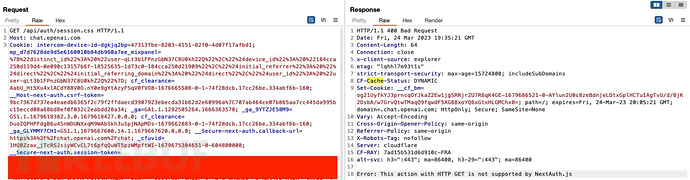
当探索ChatGPT身份验证流程的请求时,我寻找了可能暴露用户信息的任何异常。以下的GET请求引起了我的注意:https://chat.openai.com/api/auth/session。
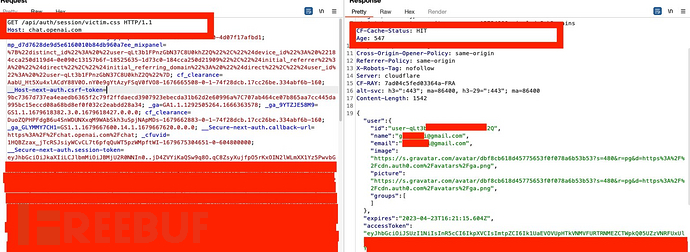
基本上每当我们登录到自己的ChatGPT实例时,应用程序将从服务器获取我们的账号背景,如我们的电子邮件、姓名、图片和访问令牌,其获取的信息如下图所示:

泄露此类信息的一个常见用例是在服务器上利用“Web缓存欺骗”,我已经多次在实时黑客事件中发现了它,并且在各种博客中也对它进行了详细的记录,例如:https://omergil.blogspot.com/2017/02/web-cache-deception-attack.html
以上帝视角来看,这个漏洞相当简单,如果我们能够强迫负载均衡器去缓存我们在特定的构造路径上的请求,我们就能够从缓存的响应中读取我们受害者的敏感数据。但在ChatGPT中,这并不容易。
为了成功进行漏洞利用,我们需要使响应包中的CF-Cache-Status字段值为“HIT”,这个值意味着它缓存了数据,并且将为同一区域的下一个请求提供服务。如下图,我们正常收到的CF-Cache-Status字段值为“DYNAMIC”,这代表它不会缓存数据。

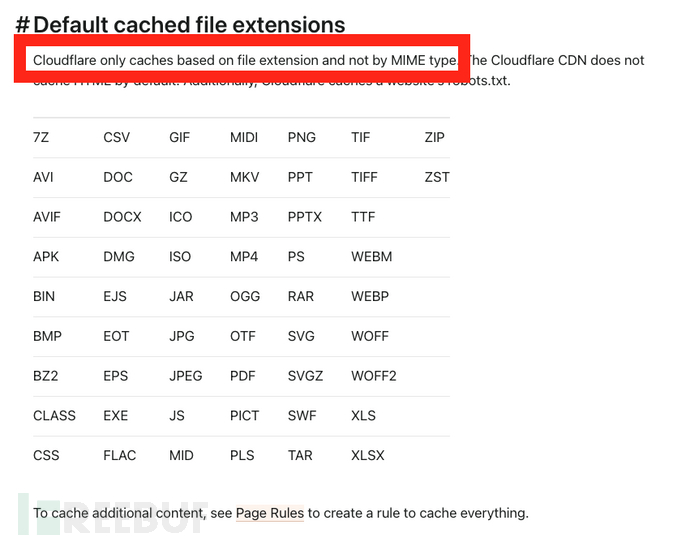
从现在开始,我们进入了有趣的部分。当我们部署Web服务器时,“缓存”的主要目标是能够更快地向终端用户提供我们的重资源,主要是JS / CSS / 静态文件,CloudFlare有一个默认扩展名列表,这些扩展名在其负载均衡器的后端被缓存。
加粗这句话的意思是:
CloudFlare(一种常用的内容分发网络和安全服务提供商)在其负载均衡器的后端自动缓存了具有特定扩展名的文件。
负载均衡器是一种网络设备,用于分配从客户端发来的请求流量到多个服务器上,以提高网站的总体性能和可靠性。
CloudFlare的系统会自动识别这些特定扩展名的文件(如.js、.css和其他静态文件),并将它们存储在缓存中。这样,当用户请求这些文件时,CloudFlare可以直接从缓存中提供文件,而不是每次都从原始服务器上检索它们,从而加快了文件的加载时间并减少了服务器的负载。
详情见https://developers.cloudflare.com/cache/about/default-cache-behavior/
Cloudflare仅基于文件扩展名而不是MIME类型进行缓存
基本上,如果我们能找到一种方法,使用下图指定的其中一个文件扩展名来加载相同的端点,同时强制端点保存敏感的JSON数据,我们将能够让它被缓存。
因此,我首先尝试在端点后加一个文件扩展名来获取资源,并查看它是否会抛出错误或显示原始响应。结果发现:
chat.openai[.]com/api/auth/session.css -> 400 - 没有成功
chat.openai[.]com/api/auth/session/test.css - 200 - 成功

这个结果让我感觉即将成功,OpenAI 仍然会在css文件扩展名下返回敏感的JSON数据,这可能是因为正则表达式失败或者他们没有将这种攻击向量考虑在内。只剩下一件事要检查,那就是我们是否能从LB缓存服务器中得到CF-Cache-Status返回字段为“HIT”。
完美(幸运)的是,我们构造的整个攻击链条都按计划工作了。
攻击流程:
攻击者在 /api/auth/session 端点处构造一个恶意的.css路径。
攻击者将这个恶意链接分配出去(直接发送给受害者或者公开发表)。
受害者访问了这个恶意链接。
受害者访问得到的JWT身份信息被缓存了。
攻击者拿到了JWT身份信息,对受害者账号的访问被成功授权。
防御修复
手动指示缓存服务器不通过正则表达式缓存端点。(这是OpenAI选择的修复方法)
除非直接请求所需的端点,否则不返回敏感的JSON响应。(我【这个我不是原作者,是翻译者哈】觉得这种修复方法可能对业务影响更小)
翻译者总结
a1batr0ss(信天翁):
我想用自己的语言和理解 解释一遍这个攻击流程:
攻击者一开始在 /api/auth/session 端点处构造一个恶意的.css路径,这个链接之所以能成功,原因有两个:
一是OpenAI没有对访问URL进行严格的过滤,以至于本来只能通过访问https://chat.openai.com/api/auth/session获取的用户敏感信息,现在攻击者构造任意https://chat.openai.com/api/auth/session/xxxxx.css也可以访问到这些敏感信息;
二是OpenAI使用CloudFlare进行负载均衡,而CloudFlare会对所有的.css文件在缓存服务器进行缓存,以便用户更快速地访问到网站。
第二点本身没有什么问题,但如果与第一个问题相结合,就出现了问题:比如,攻击者构造了一个 https://chat.openai.com/api/auth/session/hack.css的恶意链接,受害者如果点击了该链接,那么 https://chat.openai.com/api/auth/session/hack.css就会被CloudFlare缓存到分配的缓存服务器中,而hack.css的内容就是受害者的敏感信息。此时,如果攻击者选用与受害者同一缓存服务器的节点去访问 https://chat.openai.com/api/auth/session/hack.css,就可以获取到受害者的敏感信息。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者