


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
前言
给定一个数组my_list[-1],一眼过去好像没什么问题,在python中负索引会从末尾访问元素,但是在二进制中,数组是不允许产生负数,如果用上述描述则会产生数组越界,尝试使用负数索引访问数组元素将导致未定义行为,这意味着程序可能会崩溃、产生错误的结果或表现出意外的行为,严重可用来产生溢出,甚至权限被获取。
数组越界
数据越界访问是指程序试图访问数组或指针指向的内存位置超出其边界的情况。这可能导致程序读取或写入未分配给它的内存。
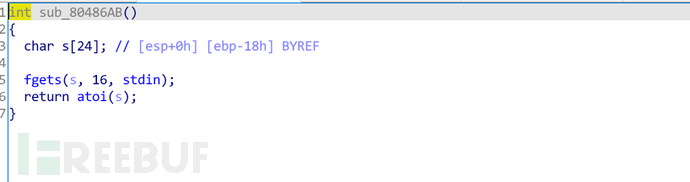
sub_80486AB是一个用户输入的函数,他将用户输入的数据赋值给V3,首先判断了如果v3大于2则会输出错误,然后将v3作为下标赋值给funcs_804BB5,这段代码就产生了问题,首先,他只判断了数组的大小,如果为我们输入的参数为-1则就会产生数组越界。通过数组越界我们就可以读取funcs_804BB5前的数据。
缓冲区进行数据同步
前边我们已经说明了数组越界,但我们没办法构造参数,并且只能以sub_80486AB本身来传递参数,我们就要寻找符合这个函数可控参数的got,我们目光接触到setbuf函数。setbuf函数是一个标准C库函数,用于将一个流(文件流)与一个用户提供的缓冲区进行关联,从而实现IO流的数据同步。
当流与缓冲区关联后,IO函数在读取数据时,会将数据从文件读取到缓冲区中,而不是直接从文件读取。类似地,在写入数据时,数据会先写入到缓冲区,然后由缓冲区再将数据写入文件。这样做的好处是,通过使用缓冲区,可以减少IO操作的频率,从而提高IO效率。
缓冲区的大小由用户提供,可以根据需要来选择合适的大小。较大的缓冲区可以减少IO操作的次数,从而提高效率,但会占用更多的内存。较小的缓冲区则可能导致频繁的IO操作,效率较低。
举一个简单的例子:
#include <stdio.h>
int main() {
// 创建一个文件流并关联缓冲区
FILE *fp = fopen("example.txt", "w");
char buffer[1024];
setbuf(fp, buffer);
// 使用关联的缓冲区写入数据到文件
fprintf(fp, "Hello, World!\n");
fclose(fp);
return 0;
}
但如果程序员偷懒没有对缓冲区buffer赋值就可以将栈上的buffer与fp绑定;造成缓冲区溢出。然后修改栈帧
通过数组越界泄露了程序自身数据,可以通过偏移计算出got函数的偏移位置。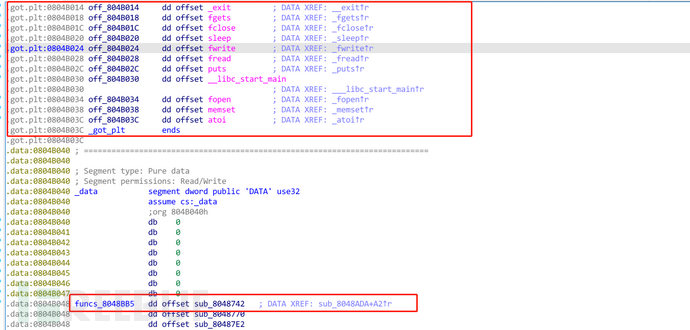
总结:
·数组下标限制不严格可导致数组越界访问;
·setbuf()可对缓冲区进行多次累加写入,绕过长度限制,造成溢出攻击;
·两个漏洞单独起来危害不大,但如果结合起来造成的攻击就是毁灭性的;
- 0 文章数
- 0 关注者