


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注

在深度学习领域,有两种任务听起来很平常却又很难,一种是把普通的模型做的非常小,使其用到简单的树莓派甚至单片机里,比如CV领域中,从大型的RCNN到小型的YOLO v1-v4,模型越来越小,检测效率越来越高;另一种是把普通的模型做到非常大,比如神经语言模型领域,从Word2Vec,Glove,ELMO到BERT系列,GPT系列,从几十万参数,到上千亿的参数量,模型越来越大,工程实现和算力成为了门槛。
我们在使用图神经网络做漏洞识别任务的时候,也需要在模型的复杂度和识别效率上做出取舍,小的模型需要极其精巧的结构设计,以及各种复杂的蒸馏,剪枝量化方法,大的模型需要强大的算力和好的工程实现能力,今天我们就来介绍一篇最新的“大力出奇迹”的成果 —— 谷歌出品的史上最大的神经网络,参数规模达到了万亿级别。
在自然语言处理(NLP)任务中,神经网络的参数数量与复杂度之间的相关性保持的非常好。不仅如此,大规模训练已经成为通向灵活而强大的神经语言模型的有效途径。在拥有强大计算资源预算,大数据集的情况下,一些经典的神经语言模型取得的性能成果甚至可以超越一些更加复杂的算法。
例如前不久OpenAI发布的GPT-3语言模型[1],是有史以来训练过的最大的语言模型之一,其拥有1750亿参数。GPT-3能够进行原始类比,生成食谱,自动生成代码等多种不同的工作。但其核心算法依然为Transformer框架。最近这一纪录被谷歌大脑所打破,谷歌大脑在其最新论文-Switch Transformers: Scaling to Trillion Parammeter Models with Simple ad Efficient Sparsity [2] 提出了最新的语言模型Switch Transformer。研究人员介绍,Switch Transformer拥有超过1.6万亿的参数,是迄今为止规模最大的NLP模型。
在深度学习中,模型通常对所有的输入重复使用相同的参数。不同于寻常神经网络,Switch Transformer采用了稀疏激活模型-此模型可以保证计算成本基本保持不变的同时允许网络拥有巨量的参数。为了实现稀疏激活,谷歌大脑的研究者们改进了专家混合范式(MoE), 该范式在2017年被引入NLP领域[3]:通过在自然语言模型中设置所谓的“MoE(Mixture-of-Experts)”层: 将输入token路由到该层中最佳的前k位专家上,之后由这个k位专家对token进行计算之后加权求和决定输出。
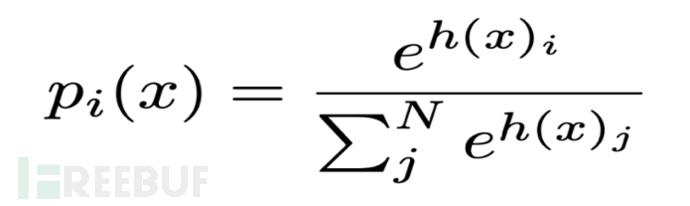
(top-k中专家i的权值由softmax计算得出)
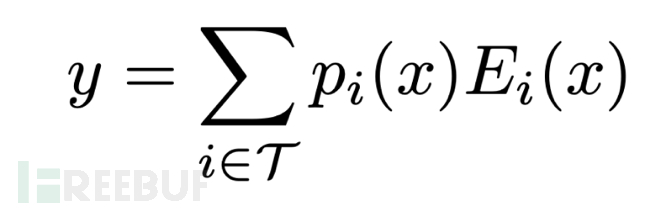
(每个token的输出由top-k的专家对其计算结果以及相应的专家权值给出)
为了实现在超大规模参数上的稀疏激活,便需要缩减k的大小。以降低路由计算以及跨设备通讯成本,Switch Transformers直接使用k=1,即每个token只路由发送给一个相应的专家(由相应计算的最高概率决定)。如下图Switch Transformer编码器所示,每个token都会经由路由算法决定其进入哪个专家。该专家层称为switch层。
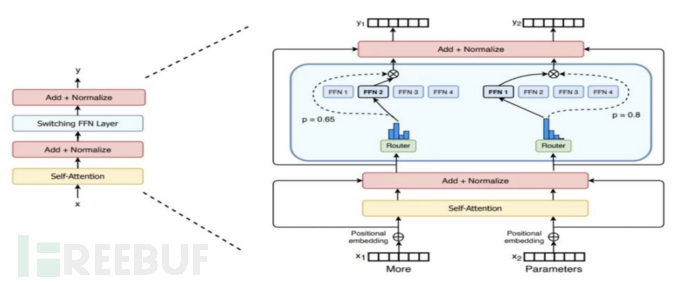
(Switch Transformer中编码器的构造)
为了防止出现过多的token被路由到同一个专家上导致容量溢出的情况,每个专家会分配一个容量因子,用于动态决定专家容量。同时为了鼓励专家之间的负载均衡,Switch Transformer中还增加了辅助损失,对于每一个Switch层,此辅助损失将被添加到训练过程中的总损失中:给定N个专家以及拥有T个token的batch B中,辅助损失将视作为向量f与概率p的缩放点积:
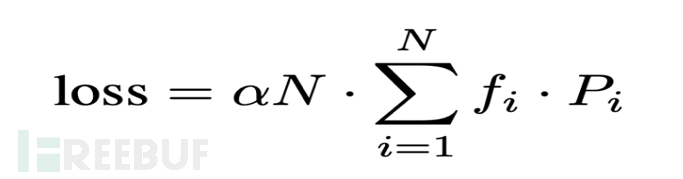
其中fi为token被分配给专家i的分数:
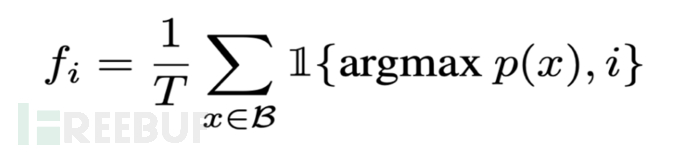
Pi为token被路由到专家i的分数:

由上面式子可以看出,当路由为均匀路由时,该loss达到最小化。
预训练表现
研究者首先在 Colossal Clean Crawled Corpus 数据集上对 Switch Transformer 进行了预训练测试,使用了掩蔽语言建模任务。在预训练设置中,他们遵循 Raffel 等人(2019)[4] 确定的最优方案,去掉了 15% 的 token,然后使用单个 sentinel token 来替代掩蔽序列。为了比较模型性能,研究者提供了负对数困惑度的结果。
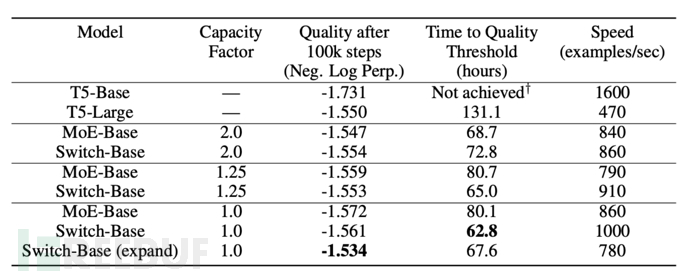
由上表可以看出·Switch Transformer的性能在速度-质量基础上均胜过密集Transformer以及MoE Transformer,并且在固定计算量和挂钟时间的情况下取得了最佳的成绩。实验表明,Switch Transformer在取较低的容量因子(1.0,1.25)情况下表现更好。
下游任务表现
研究者同时也对Switch Transformer与一系列不同的下游任务对接进行了测试:对Switch Transformer在不同的NLP任务上进行微调,之后与经过精调的T5-base和T5-Large模型进行对比:首先使Swtich Transformer在FLOPS层面上与T5对齐,之后对接下游任务测试。结果表明在多项下游任务中Switch Transformer的提升是显而易见。
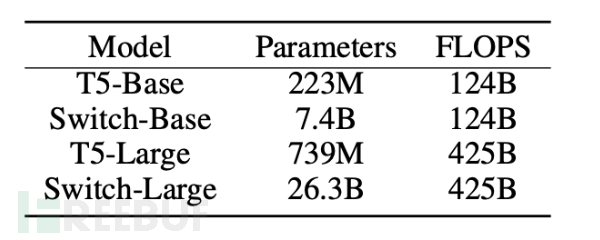
(首先将Switch Transformer与相应的T5在FLOPS层面对齐)
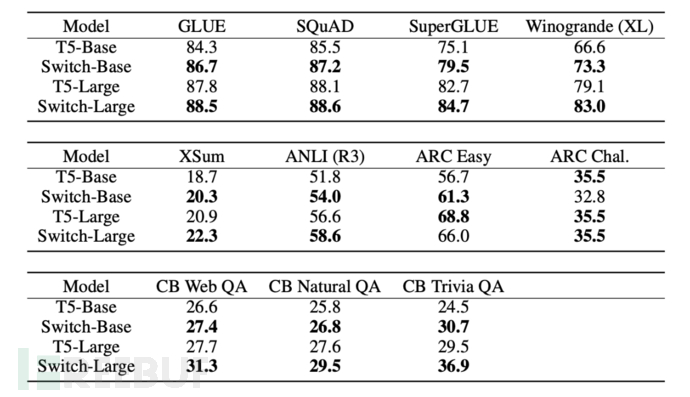
(下游任务对比结果)
网络蒸馏
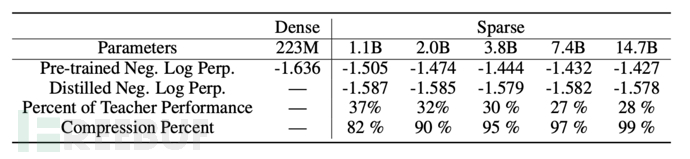
由于Switch Transformer的体积过于庞大,有必要研究将这种大型稀疏网络蒸馏为小型密集网络的影响。研究者通过使用各种蒸馏方法研究了不同压缩率下Switch Transformer的表现,实验证明了将具有11亿参数量的Switch Transformer压缩至原来的18%可同时保留37%的性能提升,而具有147亿参数的Switch Transformer压缩至1%的情况下也可保留28%的性能提升。
引用文献
- Brown, Tom B., et al. "Language models are few-shot learners." arXiv preprint arXiv:2005.14165(2020).
- Fedus, William, Barret Zoph, and Noam Shazeer. "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity." arXiv preprint arXiv:2101.03961(2021).
- Shazeer, Noam, et al. "Outrageously large neural networks: The sparsely-gated mixture-of-experts layer." arXiv preprint arXiv:1701.06538(2017).
- Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." arXiv preprint arXiv:1910.10683(2019).
- 0 文章数
- 0 关注者