


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
随着大数据技术的广泛应用,越来越多的公司与个人参与到技术与数据的共享中。大数据时代下的数据共享既是驱动力,也造就了数据安全隐患。如何在数据共享的前提下,保证数据安全与资产保值,是目前众多企业重点关注的课题之一。
现阶段很多公司都需要训练一些行业通用模型,但主要问题是缺少行业数据。针对这种情况,迁移学习与联邦学习方法应势而生。
一、迁移学习应用介绍
迁移学习最初主要应用于一些公共数据的特征提取,作为一些新提出的算法模型的预训练模型出现。研究者与开发者发现,使用迁移学习进行一些其他相关的工作建模时,对原任务的精度会有显著提升,因此在训练模型时,网络的权重拟合不再仅限于本任务的数据与内容,而是会聚焦于本任务所遭遇的问题与阻碍的解决。
BERT是最典型的迁移学习的应用,目前已应用到很多需要语言模型的领域。由于BERT的网络极其庞大,其网络权重的拟合变得极其困难,主要体现在算力要求和数据要求上。而BERT在被提出时其论文作者就考虑到了这个问题,甚至于其论文就主要聚焦于迁移学习本身。
BERT采用庞大的语料数据库进行两种任务的训练:
1、Masked Language Modeling
BERT是一个深度双向模型,此模型有效地从标记处的上下文中获取捕获信息。BERT的第一个任务是预测被遮挡的单词。面对随机遮挡一个或者多个单词的场景,神经网络判断被遮挡的单词是什么,例如:

2、Next Sentence Prediction
Masked Language Model是为了理解词与词之间的关系。另外,BERT还接受了Next Sentence Prediction训练,用于理解句与句之间的关系。给定两个句子,句A和句B,判断句B在语料库中是否为句A之后的下一个句子,例如:
 以上两个训练任务分别从不同的两个角度入手,前者侧重于文本特征双向的提取,获取基础的文本词向量特征,后者聚焦于句向量之间的相关性,两者相互结合,便可有效地提取文本特征。例如:
以上两个训练任务分别从不同的两个角度入手,前者侧重于文本特征双向的提取,获取基础的文本词向量特征,后者聚焦于句向量之间的相关性,两者相互结合,便可有效地提取文本特征。例如:
 BERT的训练任务简单易懂,但训练成本很高,因此预训练模型被提出。预训练模型即使不进行这两种高开销的预训练任务,也可以得到一定精度的效果。企业根据应用场景再使用自己的数据进行finetune微调训练,便可得到业务上可用的数据模型。不同领域,不同行业,不同训练角度的数据集训练出来的权重,却可以实现高精度的特征提取,这就是迁移学习的魅力。
BERT的训练任务简单易懂,但训练成本很高,因此预训练模型被提出。预训练模型即使不进行这两种高开销的预训练任务,也可以得到一定精度的效果。企业根据应用场景再使用自己的数据进行finetune微调训练,便可得到业务上可用的数据模型。不同领域,不同行业,不同训练角度的数据集训练出来的权重,却可以实现高精度的特征提取,这就是迁移学习的魅力。
二、联邦学习应用介绍
迁移学习的主要发起方是资金雄厚的大厂或者专注研发的团队,对于注重业务的大部分厂商,无法作为这种任务的主导者,只能被动选择。联邦学习的提出,让一些中小企业也能够参与到模型的建立中,并形成自己的数据资产与模型资产。
联邦学习本身主要有三种类型:横向学习,纵向学习与迁移学习。
1、横向学习
当用户a与用户b的数据特征类似,但用户群体多有不同时,可以选择相同特征部分的两方用户数据进行加密,然后进行联邦学习。
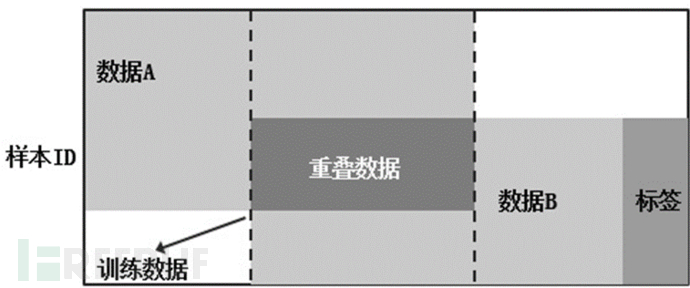
2、纵向学习
当用户a与用户b的用户群体类似,但数据特征多有不同时,可以选择相同用户部分的两方特征数据进行加密,然后进行联邦学习。
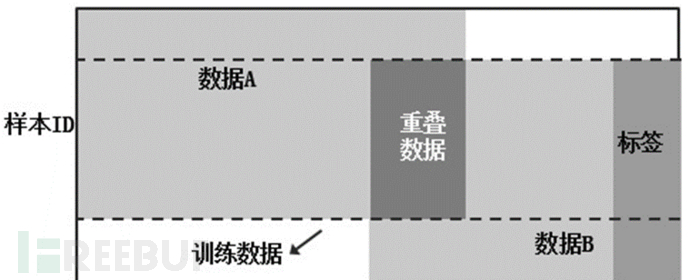
3、迁移学习
当用户a与用户b的用户群体与数据特征均多有不同时,可以选择分别进行建模,并进行迁移学习来训练共同的网络权重。
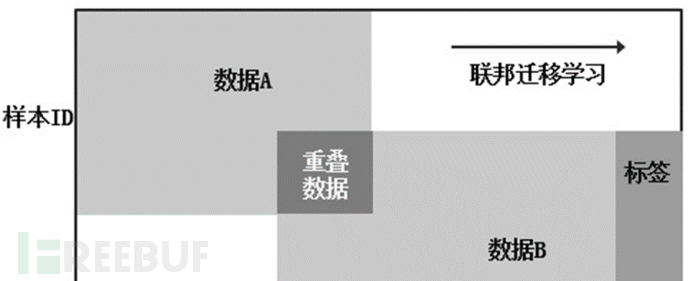
三、发展趋势
迁移学习的引入加快了算法有效落地的速度,提高了整体行业的基准水平,降低了参与者的门槛,未来也必将成为学术论文的主流方法。而联邦学习是一种在多参与方或多计算结点之间开展的一种高效率的机器学习方法,它能够保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规。其中,联邦学习使用的机器学习算法不局限于神经网络,还包括随机森林等重要算法。联邦学习正在逐步成为下一代人工智能协同算法和协作网络的基础,并作为新的驱动力促进大数据共享时代的发展。
更多精彩可关注:【鹏信科技】微信公众号

- 0 文章数
- 0 关注者