


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

W13SCAN-漏扫插件分析篇~backup_file
- 关注
W13SCAN-漏扫插件分析篇~backup_file
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言:
插件位于.\W13SCAN\scanners\PerFile\backup_file.py 每个插件类的内部最多有两个方法: def _check(self, content): #对内,可能有 def audit(self): #对外,一定有 重点关注audit()
1. 将断点设置在audit()内部
本次实例化对象的指针self中包含的内容
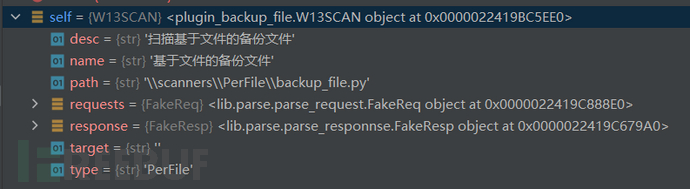
其中requests参数
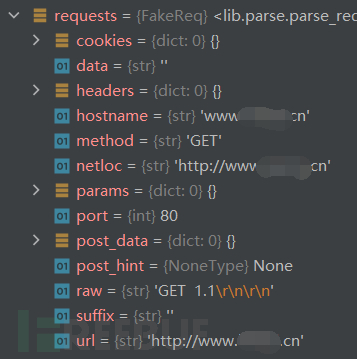
其中response参数
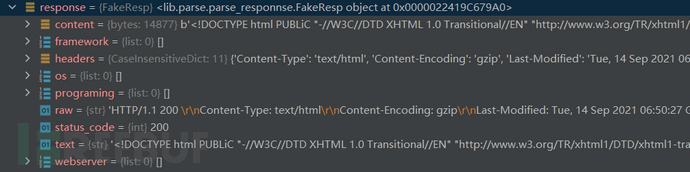
推测:请求包和响应包都已存储起来了,在本地进行分析
2. 取出headers
headers = self.requests.headers
3. 取出url
url = self.requests.url
4. 将url分割
a, b = os.path.splitext(url) 如url=”http://www.aaa.com” ,则a=’http://www.aaa’, b=’.com’
5. 生成payload
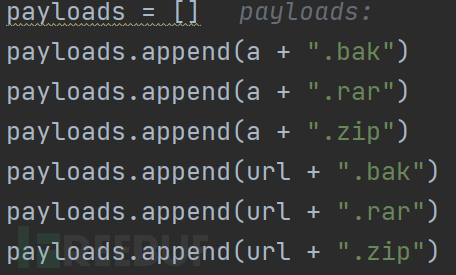
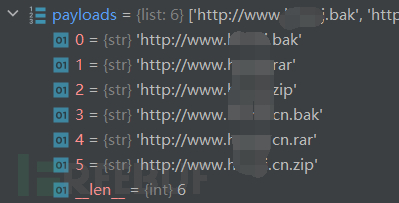
6. 遍历payload
GET方式进行请求拼接后的网址
r = requests.get(payload, headers=headers, allow_redirects=False) 其中allow_redirects=False 是禁止跟随重定向。河里
7. 判断状态码
if r.status_code == 200:
8. 读取原始响应体的一部分
也就是 urllib 的 response 对象
content = r.raw.read(10)
9. 对结果继续进行检查
if self._check(content) or "application/octet-stream" in r.headers.get("Content-Type", ''):其中self._check也就是本文件中的第一个方法,
其中application/octet-stream是什么?
它是content-type的一种类型,是二进制流,在不知道下载文件类型时使用。
10. 得到压缩包的大小
rarsize = int(r.headers.get('Content-Length', 0))11. 实例化另一个ResultObject类
result = self.new_result() 其中new_result()函数作用 def new_result(self) -> ResultObject: return ResultObject(self)
ResultObject类的作用就是生成json文件初始化格式,该文件存储着漏洞详情 类定义如下: class ResultObject(object):
12. 开始对实例化完成的result对象进行赋值
1)result.init_info(self.requests.url, "备份文件下载", VulType.BRUTE_FORCE)
其中init_info方法实现 def init_info(self, url, result, vultype): self.url = url self.result = result self.type = vultype
2)result.add_detail("payload请求", r.reqinfo, content.decode(errors='ignores'),"备份文件大小:{}M".format(rarsize), "", "", PLCE.GET)
其中add_detail方法实现
def add_detail(self, name: str, request: str, response: str, msg: str, param: str, value: str, position: str):
if name not in self.detail:
self.detail[name] = []
self.detail[name].append({
"request": request,
"response": response,
"msg": msg,
"basic": {
"param": param,
"value": value,
"position": position
}
})
13. 将结果写入文件中
self.success(result)
14. 结束
已在FreeBuf发表 0 篇文章
本文为 独立观点,未经允许不得转载,授权请联系FreeBuf客服小蜜蜂,微信:freebee2022
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐
- 0 文章数
- 0 关注者
文章目录