


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
最近get到了⼀个爬⾍利器crawlergo,于是就忽然想到与被动扫描利器xray和W13scan联动。
准备
本⼈系统:mac
⼯具准备:w13scan、crawlargo、xray、chromium
W13scan 是基于Python3的⼀款开源的Web漏洞发现⼯具,它⽀持主动扫描模式
和被动扫描模式,⽬前可以发现sql注⼊、xss、jsonp泄露、命令执⾏等常⻅漏
洞。
https://github.com/w-digital-scanner/w13scan
pip3 install -r requirements.txt
cd W13SCAN # 进⼊源码⽬录
python3 w13scan.py -h
参数详解:
optional arguments:
-h, --help 显示此帮助信息并退出
-v, --version 显示程序的版本号并退出
--debug 显示程序的异常
--level {1,2,3,4,5} 不同级别使⽤不同的有效负载:0-5(默认为2)
Proxy:
被动代理模式选项
-s SERVER_ADDR, --server-addr SERVER_ADDR 服务器addr格式:(ip:端⼝)
Target:
必须提供选项来定义⽬标
-u URL, --url URL ⽬标URL(例如:“http://www.site.com/vuln.php?id=1”)
-f URL_FILE, --file URL_FILE 扫描⽂本⽂件中给定的多个⽬标
Request:
Network request options
--proxy PROXY 使⽤代理连接到⽬标URL,如:http@127.0.0.1:8080 --timeout TIMEOUT 超时连接之前等待的超时秒数(默认为30)
--retry RETRY 超时检索时间。
Output:
输出
--html 当选择时,输出html⽂件到输出⽬录,或者您可以指定
--json JSON json⽂件⽬录是在输出中默认⽣成的⽬录,您可以更改路径
Optimization:
优化选项
-t THREADS, --threads THREADS
最⼤并发⽹络请求数(默认为31)
--disable DISABLE [DISABLE ...]
禁⽤⼀些插件(例如——禁⽤xss sqli_error)
--able ABLE [ABLE ...]
启⽤⼀些moudle(例如:启⽤xss webpack)
由于w13scan本身不⽀持爬⾍功能,所以想到了360 0Kee-Teem公开的使⽤
golang语⾔开发的crawlargo,crawlergo使⽤chrome headless模式进⾏URL动
态爬⾍,收集包括js⽂件内容、⻚⾯注释、robots.txt⽂件和常⻅路径Fuzz,确保
不遗漏关键的⼊⼝链接。
安装之前需要安装最新版的chromium,下载地址如下:https://download-chromium.appspot.com/
下载后是这样的:
然后下载crawlargo:https://github.com/0Kee-Team/crawlergo
我是mac下载底下圈起来的:
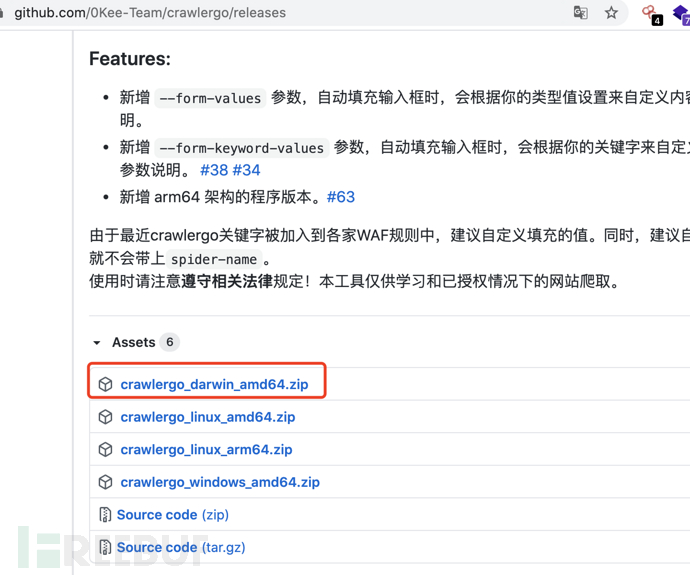
命令参数详解:
--chromium-path Path, -c Path chrome的可执⾏程序路径
--custom-headers Headers ⾃定义HTTP头,使⽤传⼊json序列化之后的数据,
这个是全局定义,将被⽤于所有请求
--post-data PostData, -d PostData 提供POST数据,⽬标使⽤POST请求⽅法
--max-crawled-count Number, -m Number 爬⾍最⼤任务数量,避免因伪静态
造成⻓时间⽆意义抓取。
--filter-mode Mode, -f Mode 过滤模式,简单:只过滤静态资源和完全重复的请
求。智能:拥有过滤伪静态的能⼒。严格:更加严格的伪静态过滤规则。
--output-mode value, -o value 结果输出模式,console:打印当前域名结果。
json:打印所有结果的json序列化字符串,可直接被反序列化解析。none:不打
印输出。
--output-json filepath 将爬⾍结果JSON序列化之后写⼊到json⽂件。
--incognito-context, -i 浏览器启动隐身模式
--max-tab-count Number, -t Number 爬⾍同时开启最⼤标签⻚,即同时爬取的
⻚⾯数量。--fuzz-path 使⽤常⻅路径Fuzz⽬标,获取更多⼊⼝。
--robots-path 从 /robots.txt ⽂件中解析路径,获取更多⼊⼝。
--request-proxy proxyAddress ⽀持socks5代理,crawlergo和chrome浏览器的
所有⽹络请求均经过代理发送。
--tab-run-timeout Timeout 单个Tab标签⻚的最⼤运⾏超时。
--wait-dom-content-loaded-timeout Timeout 爬⾍等待⻚⾯加载完毕的最⼤超
时。
--event-trigger-interval Interval 事件⾃动触发时的间隔时间,⼀般⽤于⽬标⽹
络缓慢,DOM更新冲突时导致的URL漏抓。
--event-trigger-mode Value 事件⾃动触发的模式,分为异步和同步,⽤于DOM
更新冲突时导致的URL漏抓。
--before-exit-delay 单个tab标签⻚任务结束时,延迟退出关闭chrome的时间,
⽤于等待部分DOM更新和XHR请求的发起捕获。
--ignore-url-keywords 不想访问的URL关键字,⼀般⽤于在携带Cookie访问时
排除注销链接。⽤法:-iuk logout -iuk exit。
--form-values ⾃定义表单填充的值,按照⽂本类型设置。⽀持定义类型:
default, mail, code, phone, username, password, qq, id_card, url, date,
number,⽂本类型通过输⼊框标签的id、name、class、type四个属性值关键字
进⾏识别。如,定义邮箱输⼊框⾃动填充A,密码输⼊框⾃动填充B,-fv mail=A
-fv password=B。其中default代表⽆法识别⽂本类型时的默认填充值,⽬前为
Cralwergo。
--form-keyword-values ⾃定义表单填充的值,按照关键字模糊匹配设置。关键
字匹配输⼊框标签的id、name、class、type四个属性值。如,模糊匹配pass关
键词填充123456,user关键词填充admin,-fkv user=admin -fkv
pass=123456。
--push-to-proxy 拟接收爬⾍结果的监听地址,⼀般为被动扫描器的监听地址。
--push-pool-max 发送爬⾍结果到监听地址时的最⼤并发数。
--log-level 打印⽇志等级,可选 debug, info, warn, error 和 fatal。
xray就不多说了安装对应版本即可
https://github.com/chaitin/xray/releases
过程
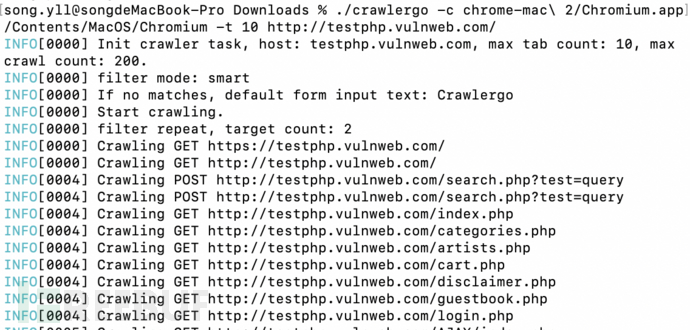
⾸先测试爬⾍,命令为crawlergo -c YourChromiumPath -t 标签⻚数 Url
./crawlergo -c chrome-mac\ 2/Chromium.app/Contents/MacOS/Chromium -t 10 http://testphp.vulnweb.com/
效果如下:
测试与xray联动:
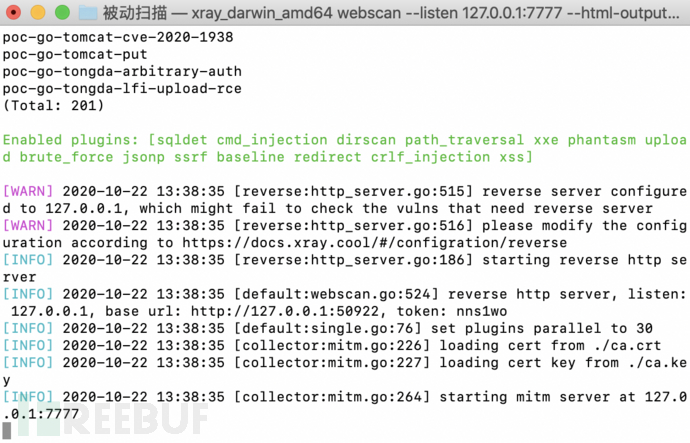
⾸先监听:
./xray_darwin_amd64 webscan --listen 127.0.0.1:7777 --html-output vulnerability.html
crawlargo开始使⽤代理爬⾍
./crawlergo -c chrome-mac/Chromium.app/Contents/MacOS/Chromium -t 10--request-proxy http://127.0.0.1:7777 http://testphp.vulnweb.com/
效果如下:
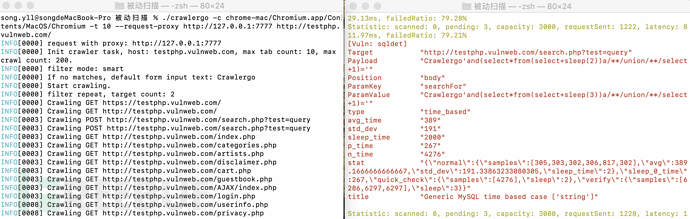
如果想半⾃动化⼀点,⽐如测试多个url可以参
考:https://github.com/timwhitez/crawlergo_x_XRAY
测试与W13scan联动:
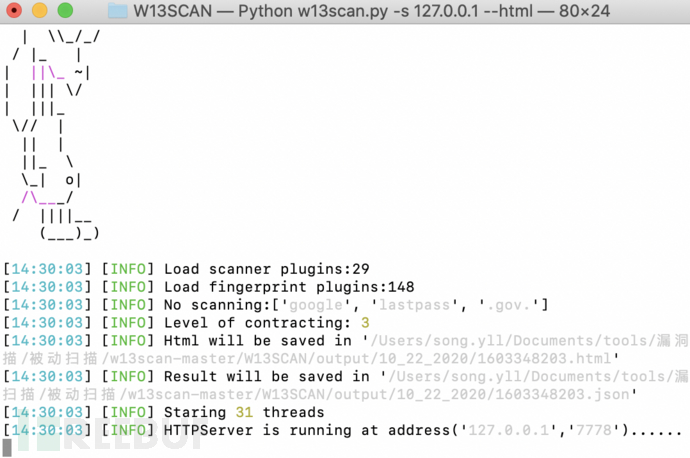
⾸先监听
python3 w13scan.py -s 127.0.0.1 --html
与前⾯爬⾍⼀样的,只是多了个代理
./crawlergo -c chrome-mac/Chromium.app/Contents/MacOS/Chromium -t 10
--request-proxy http://127.0.0.1:7778 http://testphp.vulnweb.com/
效果如下:
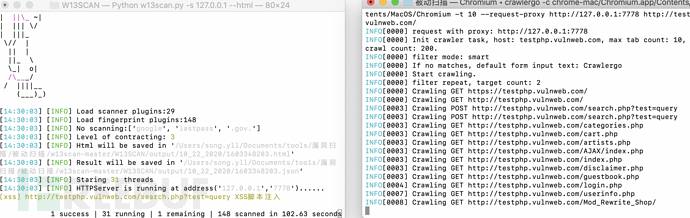
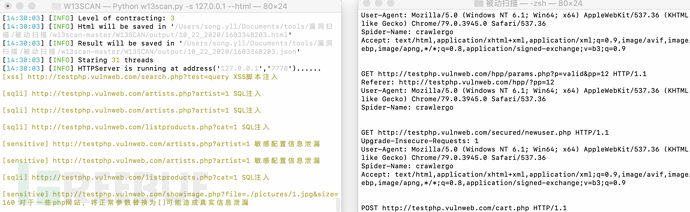
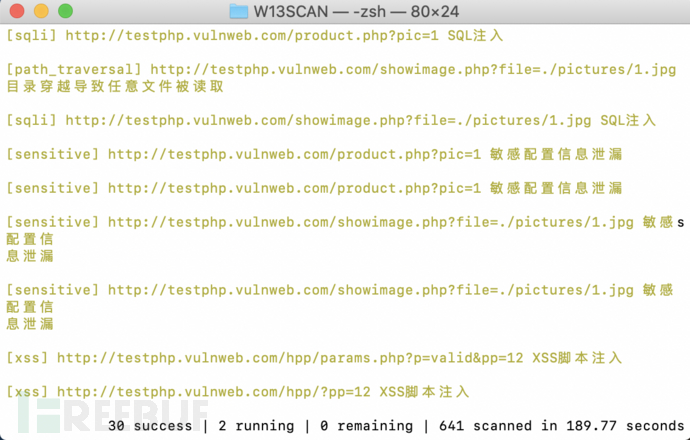
查看输出的html⽂件,⾥⾯有漏洞URL,漏洞类型,漏洞参数,漏洞利⽤的payload,还有请求信息。
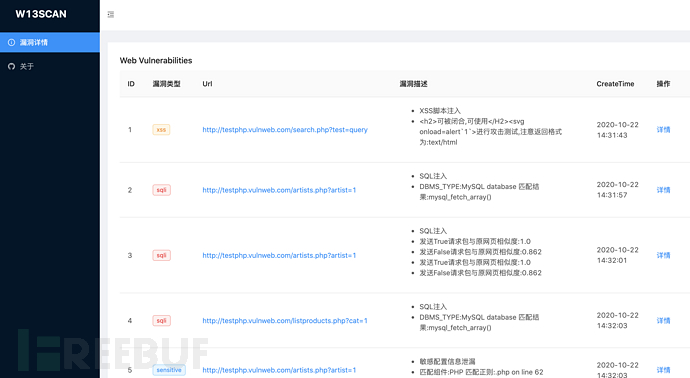
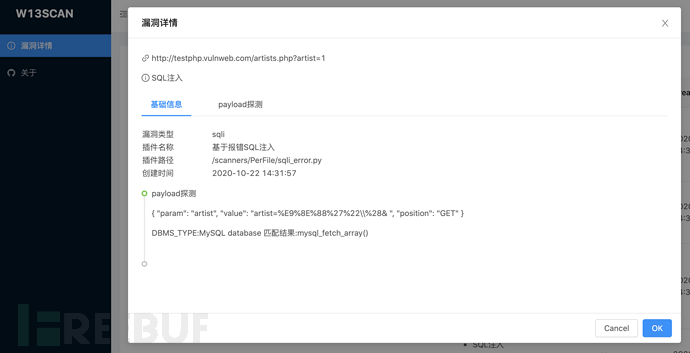
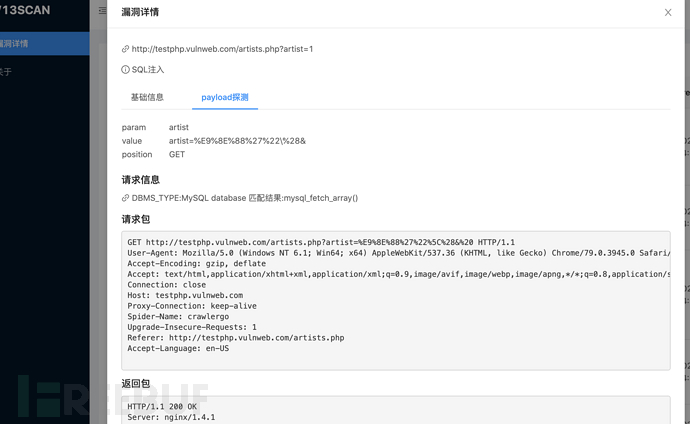
我们也可以利用w8ay师傅的自动化脚本:
import os
import sys
from urllib.parse import urlparse
import requests
import json
import subprocess
from lib.core.data import KB
root = os.path.dirname(os.path.realpath(__file__))
sys.path.append(os.path.join(root, "../"))
sys.path.append(os.path.join(root, "../", "W13SCAN"))
from api import modulePath, init, FakeReq, FakeResp, HTTPMETHOD, task_push_from_name, start, logger
# 爬虫文件路径
Excvpath = "/Users/boyhack/tools/crawlergo/crawlergo_darwin"
# Chrome 路径
Chromepath = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
def read_test():
with open("spider_testphp.vulnweb.com.json") as f:
datas = f.readlines()
for data in datas:
item = json.loads(data)
url = item["url"]
method = item["method"]
headers = item["headers"]
data = item["data"]
try:
if method.lower() == 'post':
req = requests.post(url, data=data, headers=headers)
http_model = HTTPMETHOD.POST
else:
req = requests.get(url, headers=headers)
http_model = HTTPMETHOD.GET
except Exception as e:
logger.error("request method:{} url:{} faild,{}".format(method, url, e))
continue
fake_req = FakeReq(req.url, {}, http_model, data)
fake_resp = FakeResp(req.status_code, req.content, req.headers)
task_push_from_name('loader', fake_req, fake_resp)
logger.info("爬虫结束,开始漏洞扫描")
start()
def vulscan(target):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/74.0.3945.0 Safari/537.36",
"Spider-Name": "Baidu.Inc"
}
if target == "":
return
elif "://" not in target:
target = "http://" + target
try:
req = requests.get(target, headers=headers, timeout=60)
target = req.url
except:
return
netloc = urlparse(target).netloc
logger.info("开始爬虫:{}".format(target))
cmd = [Excvpath, "-c", Chromepath, "--fuzz-path", "--robots-path", "-t", "20", "--custom-headers",
json.dumps(headers), "--max-crawled-count", "10086", "-i", "-o", "json",
target]
rsp = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, error = rsp.communicate()
try:
result = json.loads(output.decode().split("--[Mission Complete]--")[1])
except IndexError:
return
if result:
all_req_list = result["req_list"]
logger.info("获得数据:{}".format(len(all_req_list)))
for item in all_req_list:
with open("spider_{}.json".format(netloc), "a+") as f:
f.write(json.dumps(item) + '\n')
url = item["url"]
method = item["method"]
headers = item["headers"]
data = item["data"]
try:
if method.lower() == 'post':
req = requests.post(url, data=data, headers=headers)
http_model = HTTPMETHOD.POST
else:
req = requests.get(url, headers=headers)
http_model = HTTPMETHOD.GET
except Exception as e:
logger.error("request method:{} url:{} faild,{}".format(method, url, e))
continue
fake_req = FakeReq(req.url, {}, http_model, data)
fake_resp = FakeResp(req.status_code, req.content, req.headers)
task_push_from_name('loader', fake_req, fake_resp)
logger.info("加入扫描目标:{}".format(req.url))
logger.info("爬虫结束,开始漏洞扫描")
start()
logger.info("漏洞扫描结束")
logger.info("发现漏洞:{}".format(KB.output.count()))
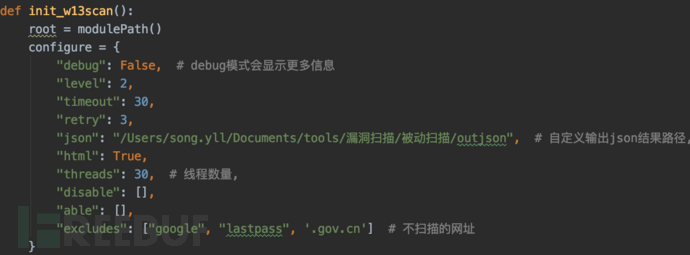
def init_w13scan():
root = modulePath()
configure = {
"debug": False, # debug模式会显示更多信息
"level": 2,
"timeout": 30,
"retry": 3,
"json": "", # 自定义输出json结果路径,
"html": True,
"threads": 30, # 线程数量,
"disable": [],
"able": [],
"excludes": ["google", "lastpass", '.gov.cn'] # 不扫描的网址
}
init(root, configure)
if __name__ == '__main__':
target = "http://testphp.vulnweb.com/"
init_w13scan()
vulscan(target)
# read_test()
可以根据自己的需求修改命令以及输出文件路径:
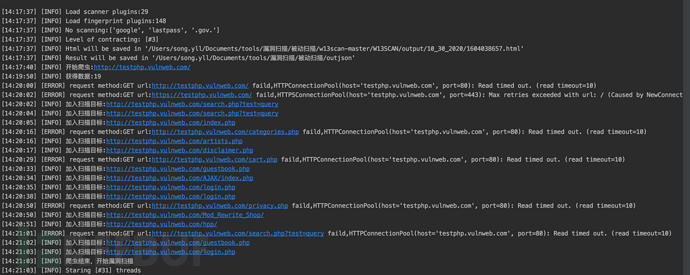
效果如下先对目标进行爬虫操作再进行漏洞扫描:
参考:
https://github.com/w-digital-scanner/w13scan
https://github.com/0Kee-Team/crawlergo
https://github.com/timwhitez/crawlergo_x_XRAY
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者