


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

为Elastalert增加参数遍历、周期性检测
- 关注
为Elastalert增加参数遍历、周期性检测
由于AWS流量镜像的特殊性,现阶段生产网的架构中只接入了HTTP与DNS流量,分别采用了Zeek与Suricata对现有流量进行分析与预警。Suricata负责基于签名的特征检测,Zeek负责定制化事件的脚本检测,也算是“各司其职”。近几日,某个业务接口出现了Pindom告警,经过分析发现部分IP尝试对该接口的参数进行遍历。由于遍历参数对应的值设置的都比较大,且后台并未对该参数进行深度的限制,导致了服务器会不断的进行计算,最终导致接口无响应。
需求
- 检测参数遍历行为;
- 访问是否存在周期性;
- unique user_agent 统计;
- threat intelligence 研判;
实现
通过扩展ElastAlert告警框架的告警模型,来实现以上需求。
规则文件
import sys
import json
import redis
import html
import datetime
from multiprocessing import Process, JoinableQueue, Lock, Manager
from elastalert.ruletypes import RuleType
from elastalert.util import elastalert_logger
try:
import pandas as pd
except:
print("Please make sure you have pandas installed. pip install pandas")
sys.exit(0)
try:
from tqdm import tqdm
except:
print("Please make sure you have tqdm module installed. pip install tqdm")
sys.exit(0)
def conn(host='localhost', port=6379, password=None, db=0):
pool = redis.ConnectionPool(host=host, port=port, password=password, db=db)
conn = redis.Redis(connection_pool=pool)
return conn
def put_data(conn, q, data):
with conn.pipeline() as pipe:
for i in data:
pipe.lpush(q, i)
pipe.execute()
class SpiderRule(RuleType):
def __init__(self, rules, args=None):
super(SpiderRule, self).__init__(rules, args=None)
self.MAX_ARGS_LENGTH = int(self.rules['beacon']['max_args_length'])
self.MIN_HITS = int(self.rules['beacon']['min_hits'])
self.MAX_UNIQUE_ARGS = int(self.rules['beacon']['max_unique_args'])
self.THRESHOLD_PERCENT = int(self.rules['beacon']['threshold_percent'])
self.NUM_PROCESSES = int(self.rules['beacon']['threads'])
self.UA_PROCESSES = int(self.rules['beacon']['user_agent'])
self.TIMESTAMP = '@timestamp'
self.FORMAT_TIMESTAMP = self.rules['timestamp'].get('format', None)
self.beacon_module = self.rules['beacon']['beacon_module']
self.WINDOW = int(self.rules['beacon']['window'])
self.MIN_INTERVAL = int(self.rules['beacon']['min_interval'])
buffer_time = str(self.rules['buffer_time'])
self.PERIOD = ':'.join(buffer_time.split(':')[:2])
self.fields = self.normalized_field(self.rules['field'])
self.src_ip = self.fields['aliases']['src_ip']
self.url = self.fields['aliases']['url']
self.url_path = self.fields['aliases']['url_path']
self.http_host = self.fields['aliases']['http_host']
self.user_agent = self.fields['aliases']['user_agent']
self.json = self.rules['output']['json'].get('enable', None)
self.redis = self.rules['output']['redis'].get('enable', None)
self.q_job = JoinableQueue()
self.l_df = Lock()
self.l_list = Lock()
def normalized_field(self, d):
fields = {'hash': [], 'output': [], 'aliases': {}}
for field, info in d.items():
alias = info['alias']
fields['aliases'][alias] = field
for i in info.get('type', []):
fields[i].append(field)
return fields
def add_data(self, data):
# Detection of spider crawlers
self.df = pd.json_normalize(data)
results = self.find_spiders()
d = results.to_dict(orient="records")
# Output to local files
if self.json:
json_path = self.rules['output']['json']['path']
with open(json_path, 'a') as out_file:
for i in d:
out_file.write(json.dumps(i) + '\n')
# Output to Redis Server
if self.redis:
try:
host = self.rules['output']['redis']['host']
port = self.rules['output']['redis']['port']
password = self.rules['output']['redis']['password']
db = self.rules['output']['redis']['db']
key = self.rules['output']['redis']['key']
ioc = self.rules['output']['redis']['field']
redis_conn = conn(host=host, port=port,
password=password, db=db)
IoC = results[ioc].unique().tolist()
put_data(redis_conn, key, IoC)
except:
elastalert_logger.error("Output Redis configuration errors.")
self.add_match(d)
# The results of get_match_str will appear in the alert text
def get_match_str(self, match):
return json.dumps(match)
def add_match(self, results):
for result in results:
super(SpiderRule, self).add_match(result)
def get_args_hash(self, args, session_id):
return hash(tuple(args + [session_id]))
def get_query_str(self, request):
query = request.split('?')[-1]
query_str = dict([i.split("=", 1) for i in query.split(
"&") if i if len(i.split("=", 1)) == 2])
query_str['args_list'] = list(query_str.keys())
query_str['max_length'] = len(query_str)
query_str['url_sample'] = request
return query_str
def percent_grouping(self, d, total):
interval = 0
# Finding the key with the largest value (interval with most events)
mx_key = int(max(iter(list(d.keys())), key=(lambda key: d[key])))
mx_percent = 0.0
for i in range(mx_key - self.WINDOW, mx_key + 1):
current = 0
# Finding center of current window
curr_interval = i + int(self.WINDOW / 2)
for j in range(i, i + self.WINDOW):
if j in d:
current += d[j]
percent = float(current) / total * 100
if percent > mx_percent:
mx_percent = percent
interval = curr_interval
return interval, mx_percent
def find_beacon(self, session_data):
beacon = {}
if not self.FORMAT_TIMESTAMP:
session_data[self.TIMESTAMP] = pd.to_datetime(
session_data[self.TIMESTAMP])
else:
session_data[self.TIMESTAMP] = pd.to_datetime(
session_data[self.TIMESTAMP], format=self.FORMAT_TIMESTAMP)
session_data[self.TIMESTAMP] = (
session_data[self.TIMESTAMP].astype(int) / 1000000000).astype(int)
session_data = session_data.sort_values([self.TIMESTAMP])
session_data['delta'] = (
session_data[self.TIMESTAMP] - session_data[self.TIMESTAMP].shift()).fillna(0)
session_data = session_data[1:]
d = dict(session_data.delta.value_counts())
for key in list(d.keys()):
if key < self.MIN_INTERVAL:
del d[key]
# Finding the total number of events
total = sum(d.values())
if d and total > self.MIN_HITS:
window, percent = self.percent_grouping(d, total)
if percent > self.THRESHOLD_PERCENT and total > self.MIN_HITS:
beacon = {
'percent': int(percent),
'interval': int(window),
}
return beacon
def find_spider(self, q_job, spider_list):
while not q_job.empty():
session_id = q_job.get()
self.l_df.acquire()
session_data = self.df[self.df['session_id']
== session_id]
self.l_df.release()
query_str = session_data[self.url].apply(
lambda req: self.get_query_str(req)).tolist()
query_data = pd.DataFrame(query_str)
# get args_hash
query_data['args_hash'] = query_data['args_list'].apply(
lambda args: self.get_args_hash(args, session_id))
for i in query_data['args_hash'].unique():
result = {
"detail": {
'percent': {},
'unique': {}
},
"tags": [],
"src_ip": session_data[self.src_ip].tolist()[0],
"url_path": session_data[self.url_path].tolist()[0],
"http_host": session_data[self.http_host].tolist()[0],
"unique_ua": session_data[self.user_agent].unique().shape[0],
"alert": False,
}
df = query_data[query_data['args_hash'] == i]
count_args_length = df['max_length'].iloc[0]
if count_args_length > self.MAX_ARGS_LENGTH:
continue
total_hits = df.shape[0]
if total_hits < self.MIN_HITS:
continue
args_list = df['args_list'].iloc[0]
for i in args_list:
unique_args = len(df[i].unique())
if unique_args == 1:
continue
# Calculate the percentage based on the number of changes in the parameters
current_percent = int((unique_args / total_hits) * 100)
if current_percent < self.THRESHOLD_PERCENT:
continue
result['detail']['percent'][i] = current_percent
result['detail']['unique'][i] = unique_args
# Number of parameters with changes
count_unique_args = len(result['detail']['unique'])
if count_unique_args <= self.MAX_UNIQUE_ARGS:
result['alert'] = True
if not result['detail']['unique']:
continue
# Beacon analysis
if self.beacon_module:
result['beacon'] = self.find_beacon(
session_data.reset_index(drop=True))
result['args_list'] = args_list
result['total_hits'] = total_hits
result['url_sample'] = df['url_sample'].iloc[0]
result['period'] = self.PERIOD
if result['alert']:
result['tags'].append('enumerate')
if result['beacon']:
result['tags'].append('beacon')
if result['unique_ua'] >= self.UA_PROCESSES:
result['tags'].append('suspicious-ua')
self.l_list.acquire()
spider_list.append(result)
self.l_list.release()
q_job.task_done()
def find_spiders(self):
if self.df.empty:
raise Exception(
"Elasticsearch did not retrieve any data. Please ensure your settings are correct inside the config file.")
tqdm.pandas(desc="Detection of Spider Crawlers.")
# get url_path
self.df[self.url_path] = self.df[self.url].str.split('?').str.get(0)
# add session_id from hash fields
self.df['session_id'] = self.df[self.fields['hash']
].progress_apply(lambda row: hash(tuple(row)), axis=1)
# split url
self.df = self.df[self.df[self.url].apply(lambda request: True if len(
request.split('?')) == 2 else False)].reset_index(drop=True)
# normalized url
self.df[self.url] = self.df[self.url].apply(
lambda request: html.unescape(request))
# unique session_id
unique_session = self.df['session_id'].unique()
for session in unique_session:
self.q_job.put(session)
mgr = Manager()
spider_list = mgr.list()
processes = [Process(target=self.find_spider, args=(
self.q_job, spider_list,)) for thread in range(self.NUM_PROCESSES)]
# Run processes
for p in processes:
p.start()
# Exit the completed processes
for p in processes:
p.join()
results = pd.DataFrame(list(spider_list))
# add timestamp
now = datetime.datetime.now().isoformat()
results['timestamp'] = now
if not results.empty:
results = results[results['alert'] == True]
match_log = "Queried rule %s matches %s crawl events" % (
self.rules['name'],
results.shape[0]
)
elastalert_logger.info(match_log)
return results
配置文件
Web.yaml
name: "Detection of Spider Crawlers"
es_host: "es_server"
es_port: 9200
type: "elastalert_modules.spider.my_rules.SpiderRule"
index: "zeek-other-%Y.%m.%d"
use_strftime_index: true
filter:
- term:
host: "canon88.github.io"
- term:
method.keyword: "GET"
include: ["true_client_ip", "host", "uri", "uri_path", "user_agent"]
timestamp:
format: false
timestamp_field: "@timestamp"
buffer_time:
hours: 12
run_every:
minutes: 10
max_query_size: 10000
scroll: true
beacon:
max_args_length: 10 # 最大检测参数个数
min_hits: 120 # 最小命中事件数
max_unique_args: 2 # 最大动态变化参数
threshold_percent: 70 # 请求阈值百分比
threads: 16 # 多进程
beacon_module: true # 开启周期性检测
min_interval: 1 # 最小周期
window: 2 # 抖动窗口
user_agent: 20 # 唯一UA个数
field:
true_client_ip:
alias: src_ip
type: [hash]
host:
alias: http_host
type: [hash]
uri_path:
alias: url_path
type: [hash]
uri:
alias: url
user_agent:
alias: user_agent
output:
json:
enable: yes # 本地输出
path: /var/log/spider/spider_detect.json
redis:
enable: no # 输出至Redis,联动情报数据进行研判。
host: redis_server
port: 6379
db: 0
password: redis_password
key: spider:feeds
field: src_ip
alert:
- debug
告警输出
{
"detail": {
"percent": {
"cookieid": 81
},
"unique": {
"cookieid": 133
}
},
"tags": [
"enumerate", // 存在参数遍历行为
"suspicious-ua" // user_agent 超过阈值
],
"src_ip": "54.160.169.250",
"url_path": "/image/cookieId.html",
"http_host": "canon88.github.io",
"unique_ua": 47,
"alert": true,
"beacon": {},
"args_list": [
"cookieid"
],
"total_hits": 164,
"url_sample": "/image/cookieId.html?cookieid=E99A3E54-5A81-2907-1372-339FFB70A464",
"period": "1:00",
"timestamp": "2020-06-02T11:07:59.276581"
}告警简述
根据以上告警内容。1小时内 IP: 54.160.169.250 总共访问了该接口164次且cookieid参数更换了133次,占到总请求量的81%。并更换了47个不同的user_agent。

写在最后
find_spider: 用于检测参数遍历的行为,这里加上find_beacon是为了增加一个周期性的检测维度。当然很多爬虫都会「自带」时间抖动,以及使用爬虫池,所以效果并不是特别明显。
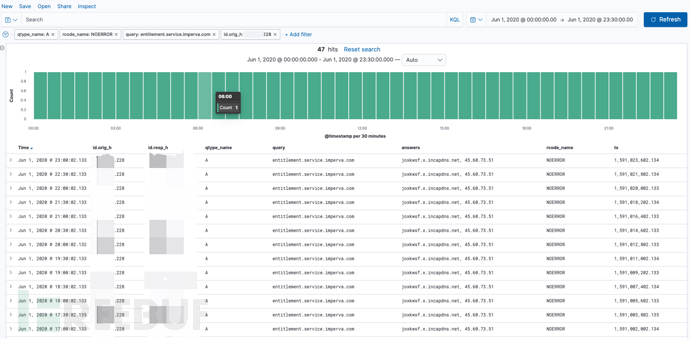
find_beacon: 更适用于检测C2连接,例如针对DNS域名的请求这种情况,这里有一个检测到的域名周期性请求的告警:
{
"src_ip": "x.x.x.228",
"hostname": "entitlement.service.imperva.com",
"answers": [
"joxkwsf.x.incapdns.net",
"45.60.73.51"
],
"percent": "100",
"interval": 1800,
"occurrences": 23,
"timestamp": "2020-06-01T08:03:38.164363",
"period": 12,
"event_type": "beaconing",
"num_hits": 806379,
"num_matches": 3,
"kibana_url": "https://canon88.github.io/goto/5f089bcc411426b854da71b9062fdc8c"
}
DNS周期性请求
 参考
参考
*本文作者:Shell.,转载请注明来自FreeBuf.COM
本文为 独立观点,未经允许不得转载,授权请联系FreeBuf客服小蜜蜂,微信:freebee2022
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐
- 0 文章数
- 0 关注者