


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文作者:mscb,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
前言
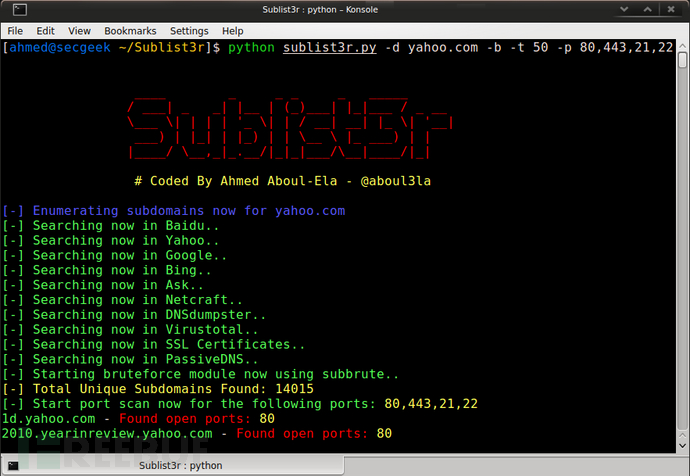
Sublist3r是一款简单易用的子域名枚举利器。但是今天我不打算讲解它的使用教程,而是深入一层,从它的代码中窥探原理。也许有人可能很不理解,为什么不好好的使用工具而偏偏去深究它的代码实现细节。
从我个人角度来说,我觉得:
第一个层面,一位优秀的安全从业者,至少在读/写代码层面不能成为短柄。如果一味的只使用工具,不了解原理,那很容易成为大家口中的“脚本小子(script kiddie)”。
第二个层面,这是我个人推崇的的学习方法,从自己的学习道路中,我喜欢遵循3个W的学习原则,即(What->Why->What):
第一个What表示在初学阶段,需要学会哪些东西能干些什么,比如知道了Sublist3r工具可以用来枚举子域名。
第二个Why则表示在中级阶段,去了解这个东西的实现原理,以及为什么要这么实现,比如通过工具的代码学会它的底层细节,与此同时还能丰富知识体系。
第三个What表示在高级阶段,知道要干什么事情需要什么工具,不在细究技术细节,而是通过前期的学习,形成自己的知识网络,能精准的根据当前情况定位到具体的工具。
Sublist3r工具介绍
从Sublist3r的GitHub主页(https://github.com/aboul3la/Sublist3r)上,我们可以了解到这是一款基于python开发使用OSINT技术的子域名枚举工具。帮助渗透测试者和bug捕获者收集目标域名的子域名。
什么是OSINT
OSINT是英文名“Open-source intelligence”的缩写,中文名称叫“公开来源情报”。从公众可见的信息中,查找所需目标的信息。说的通俗易懂一点,就是我想知道某某东西的详细信息,我在公开的信息里查找、检索,找到有关这个东西的任何内容都提取出来,最后将这些内容汇总,得到较为详细的信息。再说的通俗易懂一点就是:查资料。再再通俗一点就是:找百度。最终目标信息的准确度、详细程度均依赖于查找源。所以Sublist3r的原理就是这样,但是Sublist3r的查找源很多,不仅仅是在个别搜索引擎上查找。搜索源包括有百度、Yahoo、Google、Bing、Ask、Netcraft等等除此之外使用通过查找SSL证书、DNS、暴力枚举等这些手段去查找子域名。
简单使用
可以通过git clone https://github.com/aboul3la/Sublist3r.git安装Sublist3r。然后使用sudo pip install -r requirements.txt安装依赖库。最后通过一个简单的命令查找子域名,这里以freebuf为例子。python3 sublist3r.py -d freebuf.com网站内容越多查询时间越慢,可以加一个-v来实时显示找到的子域名。
代码细节
代码目录
在Linux终端下,使用tree能打印当前目录等结构树:
.
├── LICENSE
├── README.md
├── requirements.txt
├── subbrute
│ ├── init.py
│ ├── names.txt
│ ├── resolvers.txt
│ ├── subbrute.py
└── sublist3r.py
入口函数
sublist3r的的主要代码实现在sublist3r.py文件中。可以使用你喜欢的代码编辑器,打开这个文件。为了便于阅读,我们把所有的代码块(def、class)合上。你大概会看到如下的场景:
import re
import sys
#......省略若干引用
def banner():
def paeser_error(errmsg):
#......省略若干函数
class enumratorBase(object):
class enumratorBaseThreaded(multiprocessing.Process, enumratorBase):
class GoogleEnum(enumratorBaseThreaded):
class YahooEnum(enumratorBaseThreaded):
class AskEnum(enumratorBaseThreaded):
class BingEnum(enumratorBaseThreaded):
class BaiduEnum(enumratorBaseThreaded):
#......省略若干 XXEnum 的类
def main(domain, threads, savefile, ports, silent, verbose, enable_bruteforce, engines):
#...省略main内容
if name == "main":
args = parse_args()
domain = args.domain
threads = args.threads
savefile = args.output
ports = args.ports
enable_bruteforce = args.bruteforce
verbose = args.verbose
engines = args.engines
if verbose or verbose is None:
verbose = True
banner()
res = main(domain, threads, savefile, ports, silent=False, verbose=verbose, enable_bruteforce=enable_bruteforce, engines=engines)
如果不是使用包引用,而是直接在控制台打开,会执行if name == "main":下的内容。这里我们可以大概的了解到这里的功能,主要是用于处理用户在控制台输入的参数,并将其作为参数去调用main函数。我们可以简单的了解一下这些参数,domain是用户输入的主域名,比如freebuf.com;savefile是用于指定查找结束后子域名数据的保存目;verbose就是我们前面说的-v参数,通过这个参数来控制是否实时输出信息;engines是查找引擎(搜索源),如果为空则表示查找全部的引擎,如果用户指定了某个引擎(比如baidu),则只使用指定的引擎(比如baidu)进行查找。
main函数
一下是main这个函数的代码,我省略了很多的细节和错误处理部分的代码。
def main(domain, threads, savefile, ports, silent, verbose, enable_bruteforce, engines):
search_list = set()
if is_windows:
subdomains_queue = list()
else:
subdomains_queue = multiprocessing.Manager().list()
# Validate domain
domain_check = re.compile("^(http|https)?[a-zA-Z0-9]+([-.]{1}[a-zA-Z0-9]+).[a-zA-Z]{2,}$")
#...省略域名验证代码
parsed_domain = urlparse.urlparse(domain)
supported_engines = {'baidu': BaiduEnum,
'yahoo': YahooEnum,
'google': GoogleEnum,
'bing': BingEnum,
'ask': AskEnum,
'netcraft': NetcraftEnum,
'dnsdumpster': DNSdumpster,
'virustotal': Virustotal,
'threatcrowd': ThreatCrowd,
'ssl': CrtSearch,
'passivedns': PassiveDNS
}
chosenEnums = []
if engines is None:
chosenEnums = [
BaiduEnum, YahooEnum, GoogleEnum, BingEnum, AskEnum,
NetcraftEnum, DNSdumpster, Virustotal, ThreatCrowd,
CrtSearch, PassiveDNS
]
else:
engines = engines.split(',')
#...省略自定义引擎处理
# Start the engines enumeration
enums = [enum(domain, [], q=subdomains_queue, silent=silent, verbose=verbose) for enum in chosenEnums]
for enum in enums:
enum.start()
for enum in enums:
enum.join()
subdomains = set(subdomains_queue)
for subdomain in subdomains:
search_list.add(subdomain)
subdomains = search_list
if subdomains:
subdomains = sorted(subdomains, key=subdomain_sorting_key)
if savefile:
write_file(savefile, subdomains)
#.....省略
return subdomains
首先,代码开头根据本地的操作系统类型去声明变量subdomains_queue,这个用于保存找到的子域名。接着你可以看到domain_check,这个用于验证域名是否合法。字典变量supported_engines内即为今天的重头戏——查找引擎。冒号前面的字符串比如‘baidu’表示引擎的名字,冒号后面的BaiduEnum表示对应的类class BaiduEnum(enumratorBaseThreaded)。
{
'baidu': BaiduEnum,
'yahoo': YahooEnum,
'google': GoogleEnum,
'bing': BingEnum,
'ask': AskEnum,
'netcraft': NetcraftEnum,
'dnsdumpster': DNSdumpster,
'virustotal': Virustotal,
'threatcrowd': ThreatCrowd,
'ssl': CrtSearch,
'passivedns': PassiveDNS
}
每一个引擎就是一个写好的类,我们把类作为数据保存到列表enums里面。最终我们通过for循环来依次调用每一个类。而这每一个类都对应了该网站的子域名查询规则。就像BaiduEnum这个类,它里面就写好了如何在百度上查找关键词,以及如何筛选数据等等内容。
类BaiduEnum
因为文章篇幅有限,我们就不一个一个类讲过去,就从BaiduEnum这个类为例子,其他的类处理方法也差不多。BaiduEnum这个类继承与enumratorBaseThreaded类,而enumratorBaseThreaded类又继承于multiprocessing.Process类以及enumratorBase类。这2个类是所有引擎的基类。它们把引擎的基本功能提取出来,比如网络请求、http头数据等等。如果不是很了解这个概念可以去查找一下面向对象编程中的继承概念。我们来看看BaiduEnum的构造函数:
def init(self, domain, subdomains=None, q=None, silent=False, verbose=True):
subdomains = subdomains or []
base_url = 'https://www.baidu.com/s?pn={page_no}&wd={query}&oq={query}'
self.engine_name = "Baidu"
self.MAX_DOMAINS = 2
self.MAX_PAGES = 760
enumratorBaseThreaded.init(self, base_url, self.engine_name, domain, subdomains, q=q, silent=silent, verbose=verbose)
self.querydomain = self.domain
self.q = q
return
重点在于base_url,url中的{page_no}以及{query}就是需要最终替换的目标,query表示查询参数,page_no表示页数,也许很多人会以为这个页数是我们通俗意义上的1表示第一页,2表示第二页。但如果你去仔细看代码,你会发现在默认情况下这个page_no是每一次加10。这是因为百度和谷歌对于page_no的处理并不是以页数为基础,而是以搜索条数为基础。每一页显示10条搜索内容,那么下一页就是源基础上加上10。这样说可能会有点抽象,说的简单点,page_no为0的时候,搜索引擎默认显示的是1-10条记录,当page_no为10的时候,搜索引擎显示的是第11-20条记录,以此类推。这2个参数会在后续代码中构造出来并替换。比如{query}在后续的代码中它则会根据查找出来的子域名实时替换。
def generate_query(self):
if self.subdomains and self.querydomain != self.domain:
found = ' -site:'.join(self.querydomain)
query = "site:{domain} -site:www.{domain} -site:{found} ".format(domain=self.domain, found=found)
else:
query = "site:{domain} -site:www.{domain}".format(domain=self.domain)
return query
要理解这个,我们要先了解一下一个搜索的小技巧。如果我希望在搜索引擎上查找关于域名的知识,那我可以搜索域名。但是突然我觉得这样搜索很不精准,我想把所有百度知道的内容排除掉,那我就可以搜索:域名 -百度知道。再进一步,我想把百度贴吧的数据也排除掉,那么我的搜索词应该是这样的:域名 -百度知道 -贴吧。最后我发现,只有知乎上的信息比较符合我的要求,那我就可以直接指定查询条件:域名 site:zhihu.com来查询。这个技巧也用到了{query}身上。假设我们想寻找freebuf.com的子域名,那么我们最开始的初始值应该是这样的:site:freebuf.com,接着我们发现有一个子域名www.freebuf.com,那么我们的查询条件就变成了:site:freebuf.com -site:www.freebuf.com。再接着,我们发现了一个新的子域名job.freebuf.com,那我们的查询条件就变成了site:freebuf.com -site:www.freebuf.com -site:job.freebuf.com以此类推,不断的限制查询条件直到找不到为止。好了,我们已经知道如何构建url链接去搜索,那么它sublist3r又是如何通过搜索结果获取域名的呢?在类BaiduEnum的extract_domains方法里就实现了url地址的解析,如下所示。
def extract_domains(self, resp):
links = list()
found_newdomain = False
subdomain_list = []
link_regx = re.compile('?class="c-showurl".?>(.?)')
try:
links = link_regx.findall(resp)
for link in links:
link = re.sub('<.?>|>|<| ', '', link)
if not link.startswith('http'):
link = "http://" + link
subdomain = urlparse.urlparse(link).netloc
if subdomain.endswith(self.domain):
subdomain_list.append(subdomain)
if subdomain not in self.subdomains and subdomain != self.domain:
foundnewdomain = True
if self.verbose:
self.print("%s%s: %s%s" % (R, self.engine_name, W, subdomain))
self.subdomains.append(subdomain.strip())
except Exception:
pass
if not found_newdomain and subdomain_list:
self.querydomain = self.findsubs(subdomain_list)
return links
其余的代码都是为上下文服务的,我们就来看看几个关键代码就好,比如re.compile('?class="c-showurl".?>(.?)')这是一个正则表达式。找到所有class名称为‘c-showurl’的a标签。我们可以在百度上随便搜索一点东西,然后右键源代码,看到搜索记录的html代码。我这里的一个例子是这样的:
<a target=\"_blank\" href=\"http://www.baidu.com/link?url=Z6IgCu5XyBlPrQ5dB9aEMfc_kRh9NhHpI1LcsEe3xR4tfVp_VaDNr3kRUPzi88eGvokctArtiUoNh1ANE5BZM_\" class=\"c-showurl\" style=\"text-decoration:none;\">www.freebuf.com/articl… /a>没错,这个a标签的class是c-showurl,且我们可以看到在a标签包含下,有一个若隐若现的网址,虽然被隐藏了后面一半,我们还是可以看出它的子域名。第二个正则表达式re.sub('<.*?>|>|<| ', '', link)的目的是把找到的文本的细枝末节砍掉,留下我们需要的那一段域名。就这样我们我们通过正则表达式找到了搜索记录里的子域名,最后经过去重,拿到最终的子域名列表。代码的其他细节我就没有很详细的描述,我希望这里只是一个阅读引导,更多代码的细节由于篇幅有限就不在一行一行详细描述。因为大部分的代码写出来是为了执行上下文而写的,并不是为了原理而写。我们只要知道代码的执行原理,以及代码的目的即可。
暴力枚举子域名
暴力枚举也是很普遍的一种方法。所谓的暴力枚举真的很暴力,它是通过一个一个子域名试过去,看看目标子域名是否存在。暴力枚举域名的代码没有写在sublist3r.py代码中,而是独立包装了一个库,称之为subbrute,代码在/subbrute/subbrute.py文件中。它会根据你目前的参数去配置是否激活暴力枚举。这一段代码写在main函数中,前面的main函数为了简洁,我把暴力枚举那一部分的代码去掉了。如果要看完整版的可以去看官方的代码。下面是通过sublist3r.py中main函数调用subbrute的代码片段。
if enable_bruteforce:
if not silent:
print(G + "[-] Starting bruteforce module now using subbrute.." + W)
record_type = False
path_to_file = os.path.dirname(os.path.realpath(file))
subs = os.path.join(path_to_file, 'subbrute', 'names.txt')
resolvers = os.path.join(path_to_file, 'subbrute', 'resolvers.txt')
process_count = threads
output = False
json_output = False
bruteforce_list = subbrute.print_target(parsed_domain.netloc, record_type, subs, resolvers, process_count, output, json_output, search_list, verbose)
subdomains = search_list.union(bruteforce_list)
你可以看到,先通过enable_bruteforce变量判断是否要激活(默认是激活状态)暴力枚举。然后读入‘names.txt’和‘resolvers.txt’文件,最终,传给包subbrute,得到枚举后的子域名列表。并存储到bruteforce_list内。subbrute的代码大家可以自己去浏览一下。但是这里可以简单的讲解一下它的原理。其实相对来说也是比较简单的。暴力枚举虽然暴力,但是并不傻。不会真的从a开始一直试到zzzzz……它是采用了把可能会使用到子域名都写出来,然后再一个一个试过去。前面代码中引入的‘names.txt’就是可能用到的子域名。不行大家可以打开看看,里面包含了大部分我们日常生活中会用到的子域名组合,比如'email,www'等等。至于‘resolvers.txt’文件其实就是开放的DNS查询地址,类似于8.8.8.8这种DNS服务的集合。
使用ssl证书枚举子域名
现在带有的ssl证书的越来越多,如果目标站点是全站https,一般就只有一个证书,然后,各个子域名都包含在证书里面。我们可以通过对ssl证书的解析去获取子域名数据。比如下面的这个例子:
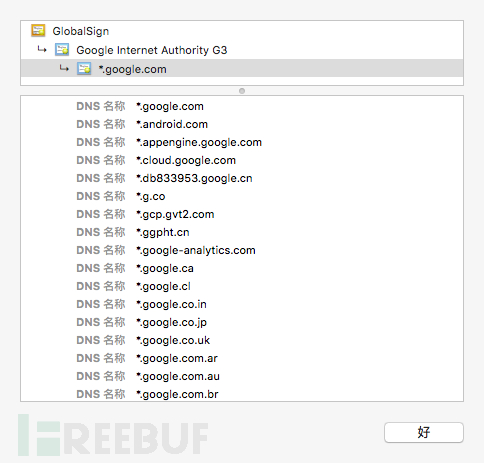
 你可以看到,这个证书颁发给了旗下的这么多域名。但是在sublist3r中没有采用自己下载ssl证书解析的形式,而是直接通过一个在线服务https://crt.sh/ 来查询,相对来说会比较方便,但是隐藏了ssl子域名枚举的技术细节,对于想通过代码了解实际原理的小伙伴来说不太友好。另外还有一个通过DNS枚举子域名也是通过在线的服务https://dnsdumpster.com来达到目的。至于dnsdumpster的底层细节我猜测可能是通过一些我们熟知的域传送漏洞,dns反查,暴力枚举等方法去实现。
你可以看到,这个证书颁发给了旗下的这么多域名。但是在sublist3r中没有采用自己下载ssl证书解析的形式,而是直接通过一个在线服务https://crt.sh/ 来查询,相对来说会比较方便,但是隐藏了ssl子域名枚举的技术细节,对于想通过代码了解实际原理的小伙伴来说不太友好。另外还有一个通过DNS枚举子域名也是通过在线的服务https://dnsdumpster.com来达到目的。至于dnsdumpster的底层细节我猜测可能是通过一些我们熟知的域传送漏洞,dns反查,暴力枚举等方法去实现。
总结
sublist3r代码量不多,很适合初学者学习。从写文章的角度来说,实在是难以一行一行代码展开讲。这也是我第一次写代码阅读的文章,没有什么经验,如果大家有什么建议欢迎大家理性的提出来。
*本文作者:mscb,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者