


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
Deepfake技术通过深度神经网络将视频中的一张脸替换为另一张脸,这个以假乱真的技术存在被滥用的隐患,与此同时又变得越来越普及。
本文,我将仔细研究这项技术本身,通过自己创建作品的方式,来回答:Deepfake软件如何工作?使用起来有多难?效果会如何?
我从“小扎”在国会作证的视频开始,然后用《星际迷航:下一代》中尉指挥官(Brent Spiner,Mr.Data)的脸代替了他的脸。总花费:552美元。
这个视频并不完美,因为它不能完全捕捉到Mr.Data的脸部全部细节,如果仔细观察,会发现人脸边缘有一些伪像。
不过,值得注意的是,像我这样的新手可以如此迅速地制作出这样水平的视频,而且花费这么少的钱。那么,在未来几年中,Deepfake技术将继续变得越来越好,越来越便宜。
Deepfake需要大量的计算能力和数据
我们称之为Deepfake,是因为它们使用了深度神经网络。在过去的十年中,计算机科学家发现,当你添加的神经元层越多,神经网络就变得越强大,但是要释放这些更深层网络的全部功能,需要大量数据和计算能力。
Deepfake就是这样。为了创建自己的Deepfake,首先,我租用了一个带有四个强大图形卡的虚拟机。即便如此,训练我的Deepfake模型也花了将近一周的时间。
然后,我需要一堆小扎和Mr.Data的图像。我上面的最后一个视频只有38秒长,但是我需要收集更多的素材进用来训练。
为此,我下载了一堆包含他们面部表情的视频:14个Mr.Data的视频和9个小扎的视频,包括他正式演讲,两次电视采访,甚至还有他在家后院抽烟的镜头。
我将所有这些剪辑加载到iMovie中,并删除了不包含小扎或Mr.Data的面孔的部分。我还减掉了较长的序列,因为Deepfake软件不仅需要大量的图像,而且还需要大量的不同图像。它需要从不同角度,不同表情和不同光照条件下看到一张脸。长达一个小时的小扎演讲的视频可能并不能比同一讲话的五分钟片段提供更多的价值,因为它只是一次又一次地显示相同的角度、照明条件下的表情。因此,几个小时的素材最后缩减到了9分钟的Mr.Data和7分钟的小扎视频。
Faceswap:端到端的Deepfake软件
是时候使用Deepfake软件了。最初,我尝试使用一个名为DeepFaceLab的程序,并设法使用该程序制作了粗糙的Deepfake视频。
但是,当我把视频发布在SFWdeepfakes subreddit上的时候,一些人建议我改用Faceswap,因为它提供更多功能,更好的文档和更好的在线支持。所以,我决定听取他们的建议。
Faceswap可以在Linux,Windows和Mac上运行,涵盖了执行Deepfake流程的每个步骤的工具,从导入初始视频到生成完整的Deepfake视频。并且附带了详细的教程(该教程由Faceswap开发人员Matt Tora编写)。
Faceswap需要功能强大的图形卡,而我用了六年的MacBook Pro显然不行。因此,从云提供商那里租了一台虚拟Linux计算机。
我开始使用一个带有Nvidia K80 GPU和12GB图形内存的实例。经过几天的训练,我升级到了2 GPU模式,然后又升级为4 GPU。它具有4个Nvidia T4 Tensor Core GPU,每个GPU都具有16GB的内存(它还具有48个vCPU和192GB的RAM,由于神经网络训练需要大量的GPU,因此大部分内存反而都没有使用)。
在两周的时间中,我在云计算方面花了552美元。无疑,我为租用计算机硬件付出了高昂的代价。而Faceswap的开发人员Tora告诉我,目前Deepfake硬件的“最佳选择”是至少具有8GB VRAM的Nvidia GTX 1070或1080卡,不过你也可以选择购买几百美元的卡。当然,一张1080卡不能像我使用的四个GPU一样快速地训练神经网络,不过只要多等待几周时间,也能获得一样的训练结果,就是稍微慢了一点。
Faceswap工作步骤:
1、提取:将视频剪切成帧,在每个帧里检测人脸面部,然后输出每个面部的对齐裁剪的图像。
2、训练:利用提取出来的图像训练一个Deepfake神经网络,该神经网络可以获取一个人脸的图像,并以相同的姿势、表情和光照度输出另一个人脸的图像。
3、转换:在最后一步中,把训练出来的模型应用于特定的视频,从而产生深层次的效果。并且,训练模型可以应用于包含训练对象的任何视频。
这三个步骤所需要的人力和算力完全不同。
提取软件可以在几分钟内完成,但是随后可能要花费数小时的人工检查结果,同时,该软件会标记每个提取图像中的每个面孔以及相当数量的误报。为了更好的呈现效果,必须人工检查并删除不相关的面孔以及该软件误以为面孔的任何事物。
相反,训练几乎不需要人工监督。但是,可能需要几天甚至几周的计算时间才能获得结果。我从12月7日开始训练我的最终模型,并将其运行到12月13日。要是再经过一周的训练,我的Deepfake的质量可能会进一步提高。如果你是在功能不那么强大的GPU的个人计算机上进行此类工作,训练好模型可能需要花费数周的时间。
最后一步,即转换,拥有最终模型后,输出Deepfake视频文件可能需要不到一分钟的时间。
Deepfake如何运作
在描述我的Faceswap训练过程之前,先解释一下基础技术。
自动编码器是Faceswap和其他领先的Deepfake软件包的核心。这是一个经过训练的神经网络,用来获取一个输入图像并输出一个相同的图像。这似乎没有什么用处,但正如我们将要看到的那样,它是创建Deepfake的关键部分。
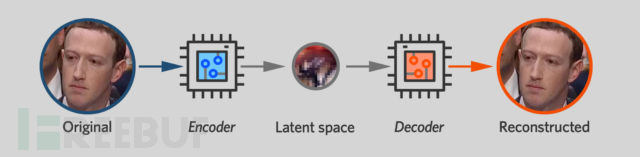
自动编码器的结构像两个漏斗,窄小的那端粘在一起。神经网络的一端是编码器,它获取图像并将其压缩为少量变量,在我使用的Faceswap模型中,它是1024个32位浮点值。神经网络的另一端是解码器。它采用这种紧凑的形式,即所谓的“latent space”,试图扩大到原始图像。
人为地限制编码器可以传递给解码器多少数据,迫使这两个网络为人脸开发出紧凑的表示形式。
你可以将编码器看作是一种有损压缩算法——在有限的存储空间下,它会尝试捕获尽可能多的人脸信息。而latent space必须以某种方式捕获重要的细节,例如对象面对的方向,对象的眼睛是睁开还是闭着,对象是微笑还是皱着眉头。
至关重要的是,自动编码器仅需要记录人脸随时间变化的各个方面,不需要捕获永久的细节,例如眼睛的颜色或鼻子的形状。例如,如果小扎的每张照片都显示蓝眼睛,则小扎解码器网络将学会自动用蓝眼睛渲染他的脸。
无需使用从一幅图像到另一幅图像不变的信息,将拥挤的latent space弄得一团糟。就像我们将看到的那样,自动编码器对待人脸的暂时性特征与永久性特征的区别,这是其生成深层伪造的能力的关键。
训练神经网络的每种算法都需要某种方法来评估网络的性能,因此可以对其进行改进。在许多情况下,一个人需要通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型,也就是监督训练。但自动编码器是不同的,它们只是复制自己的输入,所以训练软件可以自动判断其表现,也就是无监督训练。
像任何神经网络一样,Faceswap中的自动编码器使用反向传播进行训练。训练算法将特定的图像输入神经网络,并找出输出中的哪些像素与输入的不匹配。然后,它会计算出是神经网络最后一层中哪里出了问题,然后调整每个神经元的参数。
然后,错误将传播到倒数第二层,再一次调整每个神经元的参数。误差以这种方式向后传播,直到调整了编码器和解码器中的神经网络的每个参数。
然后,训练算法将另一个图像馈送到网络,并且整个过程再次重复。可能需要数十万次此过程的迭代才能生成自动编码器。
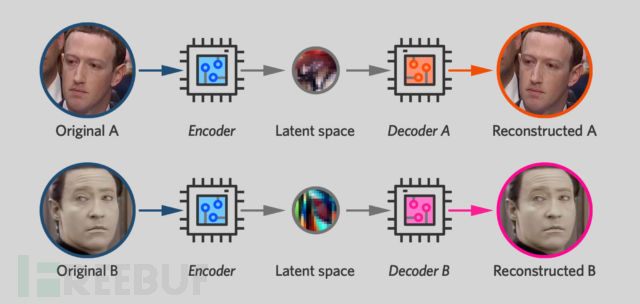
Deepfake软件通过并排训练两个自动编码器来工作,其中一个用于原始面孔,一个用于新面孔。在训练过程中,每个自动编码器仅显示一个人的照片,并经过训练以产生与原始照片非常相似的图像。
但是,有一点不同的是:虽然两个网络使用相同的编码器单元。解码器(位于网络右侧的神经元)保持分离,每个神经元都被训练生不同的面孔。但是,网络左侧的神经元则具有共享参数,这些参数可以在训练自动编码器网络时随时可以更改。当在小扎网络上训练小扎面孔时,也会修改Mr.Data一半的编码器。同理,每次在Mr.Data网络训练Mr.Data面孔时,小扎编码器也会做出这些更改。
因此,这两个自动编码器有一个共享编码器,可以“读取” 小扎或Mr.Data的脸。
不管是小扎还是Mr.Data的照片,编码器的目标是使用相同的表示方式来表示头部角度或眉毛位置。反过来,这意味着如果你用编码器压缩了一张脸,你就可以用任何一个解码器来扩展它。
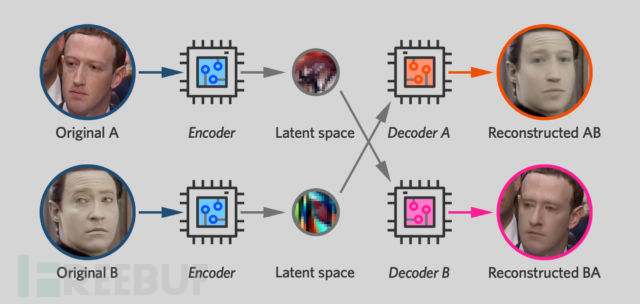
因此,一旦像这样训练了2个自动编码器,那么Deepfake的步骤就很简单。
我们之前说过latent space倾向于捕获人脸的瞬时特征(表情,他所面对的方向,眉毛的位置),而永久性特征(如眼睛的颜色或嘴巴的形状)则由解码器产生。这意味着,如果你对小扎的图片进行编码,然后使用数据解码器对其进行解码,那么您将拥有一张具有Mr.Data永久特征(例如,他的脸部形状)但具有小扎表情和朝向的面孔。
如果将这种技术应用于小扎视频的连续帧,则可以获得一个新的视频,Mr.Data的脸部动作与小扎在原始视频中所做的一样,包括微笑,眨眼,转头。
这是相对的。当你训练一个神经网络来输入小扎的照片并输出Mr.Data的照片时,同时训练网络以摄取Mr.Data的照片和输出小扎的照片。Faceswap的视频转换工具包括一个“交换模型”复选框,该复选框可让用户交换解码器。结果:它没有用小扎的脸代替Mr.Data的脸,而是做了相反的事情,产生了像这样的搞笑视频:
训练数据
在实践中,要通过Deepfake软件做出一个好的视频并不容易。
如前面所说,我收集了大约7分钟的Mr.Data的视频素材和9分钟小扎的视频素材。然后,我使用Faceswap的提取工具将视频剪切,并获得两张男人脸部的剪裁图像。视频每秒大约有30帧,但我仅提取了六分之一的图像,因为图像的多样性比原始数量更重要,并且要是捕获视频的每一帧意味着你也会收获大量非常相似的图像。
同时,Faceswap的提取工具产生了大量误报,甚至在某些镜头的背景中识别出面孔。因此,我花了大概几个小时来手动删除所有非两个人物的提取照片。最后,我获得了2598张Mr.Data和2224张小扎的面孔图像。
至此,终于可以开始实际训练我的模型了。当前,Faceswap预包装了10种不同的Deepfake算法,这些算法支持不同的图像大小和不同的计算能力要求。在底层,有一个“轻量级”模型可以处理侧面64像素的面部图像。它可以在具有小于2GB VRAM的计算机上运行。其他型号可同时处理侧面128、256甚至512像素的图像,不过需要更多的视频内存以及更多的训练时间。
我开始训练了一个所谓的DFL-SAE模型,但是,Faceswap文档警告说,此模型遭受“identity bleed”,其中一张脸的某些特征会渗入另一张脸。经过一天的培训,我切换到了另一种叫做Villain的模型,该模型可处理128像素图像。然后我等啊等,经过六天的训练,在周五的时候,训练仍在进行中。这时候的`模型已经可以制作出非常不错的Deepfake,但是如果我再有一周的计算时间,可能会获得更好的结果。
Faceswap软件是为长时间的计算工作而精心设计的。如果你从图形用户界面运行训练命令,那么GUI会定期更新预览屏幕,显示有关软件如何渲染Data和Zuck的示例。如果你更喜欢从命令行训练,也可以这样做。Faceswap GUI包含一个“生成”按钮,能做出你需要执行的确切命令。
DeepFakes 可以做到多好?
在训练过程中,Faceswap会持续显示两个自动编码器各自的数字得分,称为损失。这些图证明小扎和Mr.Data的自动编码器可以很好地再现他们的照片。当我上周五停止训练时,这些“损失”的数字似乎仍在下降。
当然,我们真正关心的是Mr.Data解码器如何将小扎的脸转换为Mr.Data的脸。我们不知道这些“转换后的图像”看起来是什么样子,因此无法精确测量结果的质量。我们能做的就是一直看着它,直到它看起来比较正常。
上面4个训练过程中的作品显示了DeepFakes的效果,随着训练不断进行,人物的脸部细节变得更加栩栩如生。
经过三天的训练后,12月9号,我发布了初始视频,就像右上角那个视频一样,结果受到严厉批判:“总的来说看起来很糟糕,根本没有说服力。我还没有看到其中哪一种看起来不是假的。”
确实,存在很多的痕迹。在某些帧中,Mr.Data的脸和小扎头部的边界不太正确,有时候能看到小扎得美貌从Mr.Data的脸后面透出来。这些合成问题需要大量的人力后期来处理,也就是逐帧浏览视频然后调整遮罩。
然而,更根本的问题是,deepfake算法在复制人脸最精细的部分做得似乎还不是很好。比如即使经过将近一个星期的训练,脸部仍然看起来有些模糊,而且根本没有细节。包括deepfake软件似乎无法以一致的方式渲染人的牙齿。有时候,别人的牙齿会清晰可见,但几帧之后,人物的嘴巴会变成黑色的空隙,根本看不到牙齿。
在更高的分辨率下,“面部交换”问题变得越来越困难。自动编码器可以很好地再现64 x 64像素的图像。但是要重现128 x 128图像的精细细节(更不用说侧面256像素或更高分辨率的图像了),仍然是一个很大的挑战。这也可能是最很多Deepfake往往是相当宽的镜头而不是某人脸部特写的原因之一。
不过,在未来几年,研究人员很可能会开发出克服这些局限性的技术。
Deepfake软件经常误认为是基于生成式对抗网络(GAN, Generative Adversarial Networks,但实际上,它是基于自动编码器,而不是GAN。但是GAN技术的最新进展表明,深层仿冒仍有很大的改进空间。
当GAN在2014年首次推出时,它们只能生成块状的低分辨率图像。但是最近,研究人员已经弄清楚了如何设计可生成最大1024像素的逼真的图像的GAN。这些论文中使用的特定技术可能不适用于Deepfake,但可以联想到或许也会有人为自动编码器开发类似的技术来进行面部表情转换。
最后
Deepfake的普及显然是一个值得关注的问题。这些软件和其他数字工具的出现意味着我们不得不以怀疑的态度观看视频。如果我们看到一个视频,有人说了一些可耻的话或脱了衣服,我们必须考虑是否是人为仿造。
而在我的实验中,至少目前来说Deepfake技术存在局限性:需要大量的知识和精力来制作出完全令人信服的虚拟面孔。而且只能交换人脸,不会换头发、手臂或腿,因此这些因素都可以用来识别Deepfake视频。
当然,几年后,Deepfake技术会进步。可以说,Deepfake的开发是不可避免的,创建一种用户友好的开放源代码换脸工具将有助于揭开该技术的神秘面纱,并就其功能和局限性对公众进行教育。
当然,从长远来看,也存在风险:Deepfake可能会完全破坏公众对视频证据的信任。
*参考来源:arstechnica,kirazhou编译整理,转载请注明来自 FreeBuf.COM。
- 0 文章数
- 0 关注者