


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注

一边是阿里、华为、商汤等国内巨头纷纷发布类ChatGPT产品,一边是ChatGPT泄露三星机密数据,被花旗银行、高盛、摩根大通、德意志银行等企业禁用,人工智能带来的机遇和风险就这样不期而遇。
在此背景下,FreeBuf咨询特别发布洞察报告《GPT浪潮席卷下的安全思考》,从GPT算法迭代路径入手,深入探讨以GPT为代表的算法模型可能面对的安全隐患、应对举措及未来发展态势。
报告关键发现
1. GPT-1-GPT-3发展期间参数规模呈指数级扩张,InstructGPT引入的奖励机制允许模型以较少的参数实现更优的效果,标志着未来GPT模型的发展重点将主要聚焦算法机制的增强迭代,而非一味扩大参数规模。
2. 算法偏见歧视、算法弱鲁棒性等模型本体诱发的安全风险主要依靠提升模型精度来减轻,未来可通过加强多模型、多模态整合,优化安全规则奖励机制两个层面进行提升。
3. 与先前版本相比,GPT-4引入了对抗性测试、RBRMs等多重安全机制,引导模型生成合规内容,未来需继续优化模型风控体系。
4. AIGC的高速发展增加了数据及隐私保护的监管难度,例如算法的不可解释性加大了数据来源的追查难度、算法的涌现性导致了非预期型用户特征生成等。
5. 算法治理应当继续秉持伦理先行的基本原则,采取先紧后松的监管方针,在确保技术可控性后逐步放宽管控力度,明晰不同应用场景的具体要求。
ChatGPT一经推出,迅速引发各行各业以及庞大C端消费群体的大量关注与使用。由此伴生的内容滥用、用户数据超范围采集、生成结果等可能包含偏见歧视或政治引导性内容、论文作弊等问题也频受争议,意大利率先采取行动禁止本国用户使用ChatGPT,三星员工将企业机密信息传至ChatGPT导致数据泄露,花旗银行、高盛、摩根大通、德意志银行等企业纷纷禁止员工访问ChatGPT,诸如此类的安全事件掀起与之相关的技术使用边界、伦理风险、安全隐患等话题的讨论热潮。
GPT模型算法迭代路径
GPT模型的迭代可分为两个主要阶段。第一阶段为参数扩张阶段(GPT-1-GPT-3):此阶段GPT模型的参数规模呈指数级扩张,GPT-2的参数规模达15.8亿,较GPT-1扩大超10倍,GPT-3的参数规模更是突破性地增长到1750亿,较GPT-2增长超100倍。与此同时,GPT-3训练数据量规模达到45TB,模型层数也达到96层,标志着大语言模型(LLM)时代的正式开启。
第二阶段为模型增强阶段(InstructGPT及之后版本)。在GPT-1-GPT3发展期间,算法能力的增强主要围绕二阶段训练模式进行调整,GPT-2采用零次学习zero-shot取代GPT-1的fine-tuning, GPT-3采用少量学习模型few-shot取代zero-shot。
InstructGPT在算法模式上实现了质的突破,通过引入人类反馈强化学习方案(RLHF),鼓励模型输出与人类偏好一致的结果(公正的前提下),例如避免输出带有种族、性别、地域的歧视性言论。实验证明,InstructGPT以1/100(13亿)的参数即实现了优于GPT-3(1750亿)参数的表现,GPT模型正式走入算法增强阶段。
ChatGPT与InstructGPT的结构类似,并优化了Chat机制。ChatGPT的产品化也使ChatGPT得以开放至公众进行测试训练,从而产生更多有效的标注数据。
GPT-4引入多模态大语言模型(MLLM),MLLM融入了图像、交错型图像与文本等文本外的其他模态,为感知与语义的结合提供了可能性,这种跨模态的训练方式加强了模型的推理能力。与此同时,GPT-4加入了基于规则的奖励模型(RBRM),根据预定义的规则为特定动作或事件分配奖励,进一步规避生成歧视性、恶意政治引导性等错误信息或有害内容。
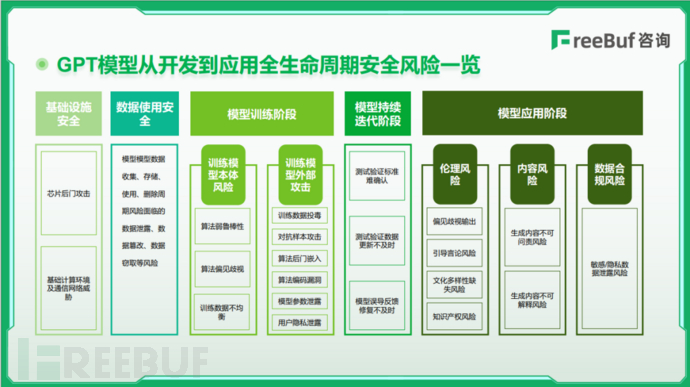
GPT模型全生命周期安全风险一览
GPT模型从开发到应用主要分为数据采集、模型训练、模型增强以及模型应用四个核心阶段。其中,训练阶段模型可分为训练模型本体风险:主要包括训练数据不均衡导致的算法偏差、算法鲁棒性弱导致模型易受干扰等;以及训练模型外部攻击:主要包括数据投毒、对抗样本攻击等,攻击者在训练数据中渗入恶意、有毒数据、增添干扰项等手段,刻意改变模型输出结果的风险,窃取模型、窃取用户隐私等。模型应用阶段主要包括偏见歧视输出、引导言论等伦理风险,生成内容不可解释等内容风险以及敏感/隐私数据泄露风险。
由于数据的使用贯穿模型运行的整个周期,FreeBuf咨询将数据采集阶段的安全风险合并为数据使用安全。此外,GPT模型的开发还涉及基础设施环境所存在的安全风险,包括芯片后门攻击、基础计算环境与通信网络威胁等。
FreeBuf咨询将GPT模型从开发到应用全生命周期可能面临的安全风险用下图进行梳理:
增强模型精度
算法精度是控制模型安全风险的根本,算法鲁棒性、算法偏见歧视等模型本体引发的安全风险主要依靠增强模型精度来减轻。
FreeBuf咨询认为,未来模型精度可通过以下两个方面进行提升:一是加强模型整合,包括多模型整合以及多模态整合两个维度。多模型整合即GPT模型与其他模型的整合,作为一款自然语言模型,GPT在生成某些特定专业领域内容的正确率仍有待提升。2023年3月,ChatGPT更新功能,支持其与5000+应用的交互,其中包括与数学引擎Wolfram模型的整合。这种整合化的模型应用将打通算法能力,帮助不同模型补齐各自的短板,从而在融合发展的过程中提升算法精度。多模态整合即拓宽训练数据语料库格式,包括图像、音频等,目前GPT-4引入了MLLM模型,为感知与语义的结合提供了可能性,未来或将进一步丰富训练语料组的形式,诸如音频、视频等,从而构建模型链式思维网。
二是优化安全规则奖励机制。GPT-3.5模型引入了RLHF奖励机制,鼓励输出与人类偏好一致的结果。GPT-4在此基础上加入RBRM模型,进一步引导模型生成合规内容、拒绝有害内容。FreeBuf咨询认为,不断优化奖励机制,从而增强模型对于有害信息的识别能力,将会是规避错误、违法、歧视性内容输出的大趋势。
点击链接或扫描下方二维码获取报告全文:
链接:https://pan.baidu.com/s/15ycfJfGJUDunCUkMGPjZ9w?pwd=svof
提取码:svof

关于FreeBuf咨询
FreeBuf咨询集结安全行业经验丰富的安全专家和分析师,常年对网络安全技术、行业动态保持追踪,洞悉安全行业现状和趋势,呈现最专业的研究与咨询服务,主要输出四个种类的咨询报告:行业研究报告、能力评估报告、产品研究报告以及甲方定制化报告。FreeBuf咨询自成立以来, 已积累了500+ 甲方安全智库资源,为行业研究报告、企业咨询服务提供指导。访谈上百位行业大咖,为业界输出真实、丰富的安全管理价值与实践经验,具备超过80万+ 精准用户,直接触达CSO、企业安全专家、投资人等专业人群。如有疑问,请联系 FreeBuf咨询 陈珣之 :
电话:18621018976邮箱:xunzhi.chen@tophant.com
- 0 文章数
- 0 关注者