


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
目前市场上大多数深度学习应用通常面向销售、金融、社交媒体等领域,但在使用深度学习来保护这些领域的产品和业务、避免恶意软件和黑客攻击方面,却鲜有资源。像Google、Facebook、微软和SalesForce这样的大型科技公司已经将深度学习嵌入他们的产品之中,但网络安全行业仍在追赶的路上。
本期介绍深度学习以及它支持的一些现有信息安全应用,并讲解如何使用深度学习检测XSS注入攻击。
一、深度学习应用简介
2016年谷歌下属公司Deep Mind基于深度机器学习研究的AlphaGo首次打败围棋专业棋手李世石,使得深度学习再次引起全球范围内的轰动。深度学习是近年来在图像识别、语音识别、自然语言处理等领域的突破性应用。
深度学习是一个具有多个隐层的非线性神经网络结构,深层神经网络由一个输入层、数个隐层和一个输出层构成。每层有若干个神经元,神经元之间有连接权重。每个神经元模拟人类的神经元细胞,节点之间的连接模拟神经元细胞之间的连接。
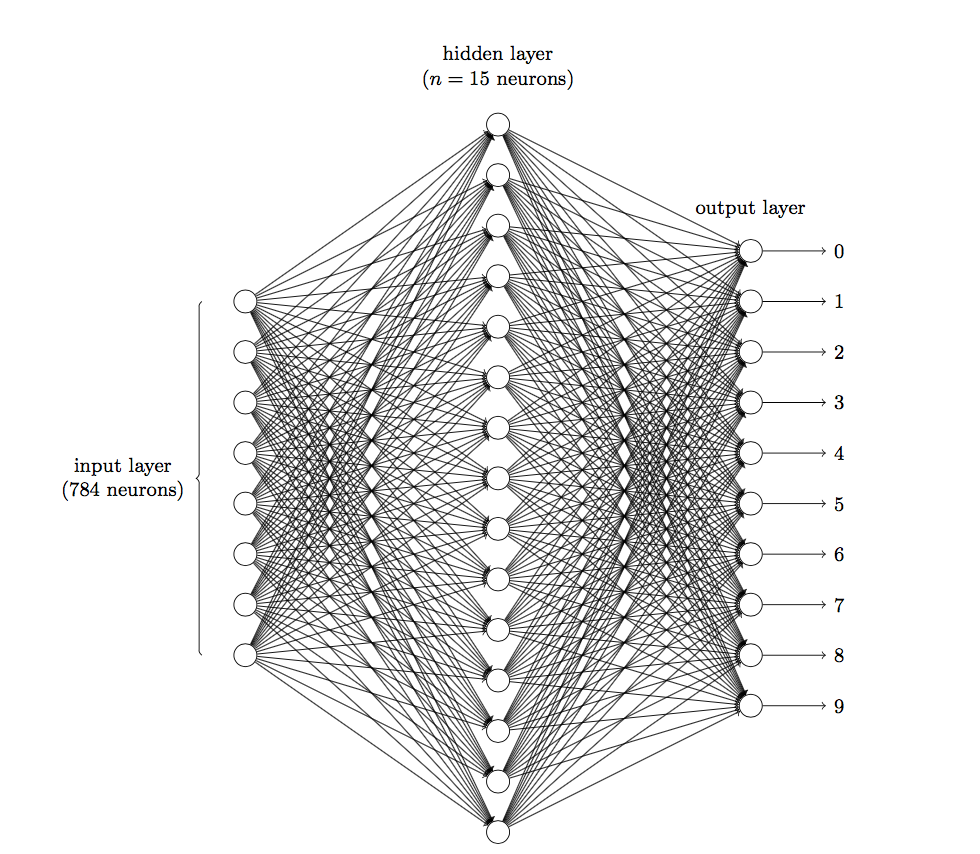
图1
二、深度学习在信息安全上的应用
1.恶意代码检测
恶意代码稍变形就可以绕过,而传统的杀毒软件是基于文件签名和特征码来确定恶意文件的,会导致大量漏报。后来出现了沙盒和虚拟机技术,可以对病毒的动态行为进行检测,这是从静态检测到动态分析的进步,很大程度上提升了对未知恶意代码的检测能力,但从本质上还是基于规则的检测。大量论文都提出了深度学习应用于恶意代码行为分析检测上的思路,已是大势所趋。
2.入侵检测
传统的入侵检测系统多是基于误用入侵检测技术,也就是说提取入侵行为的特征或规则,即黑名单方式。大多数国内厂商的竞争点还是入侵行为库的多寡,这跟恶意代码检测起初的思路是一样的。后来出现了异常行为检测技术,也就是基于统计的方法对正常行为进行概率统计建模,再对与正常模型偏差较大的异常行为进行分析和报警。深度学习也应用到了入侵检测,对网络包进行统计、分布、序列维度上的特征进行提取和模型训练。现在入侵检测的主流思路已经从黑名单转为白模型方式,正如安全圈盛行的那句话:“正常的总是相似的,异常各有各的异常。”
3.WebShell检测
利用深度学习进行WebShell检测,主要思路分为静态检测、动态检测和流量检测。静态检测是把WebShell文件作为普通文本序列,使用词袋模型(BOW)、TD-IDF进行特征提取;动态检测是对opcode或系统调用序列进行建模;流量检测的思路是基于Web流量,根据一系列参数特征、信息熵、时间分布特征等对正常流量和WebShell访问流量样本进行训练分类模型,从而发现WebShell的访问行为。
4.深度学习检测DGA
利用深度学习进行DGA检测,主要从语法分析的角度检测dga域名,包括使用n-gram和正常域名对比词频,使用hmm和正常域名对比域名字符组合的概率,分析域名的熵、辅音字母、数字等特征,作为dga域名的检测特征,之后使用LSTM算法进行模型训练。
三、基于深度学的XSS注入检测
1.数据准备
从xssed爬取训练数据,训练集正常样本30000条,XSS攻击样本25343条;验证集中正常样本10000条,XSS攻击样本10000条;测试集中正常样本5000条,XSS攻击样本5000条。
2.数据预处理
>>>①分词处理
使用结巴分词工具python版本进行分词处理。
分词遵循以下原则:
a.单双引号包含的内容 ‘xss’
b. http/https链接
c. <>标签 <script>
d.<>开头 <h1
e.参数名 topic=
f.函数体 alert(
g.字符数字组成的单词
>>>②词向量处理
将分词后的样本转化为计算机可以理解的矢量,常见的有one-hot 编码和Word2Vec(词向量)。
one-hot 编码:最简单的编码方式是把每个词都表示成一个长向量,向量的长度为词表的大小 ,只有这个词对应位置上为1,其余都为0,但无法表示词和词之间的关系。
Word2Vec:Google提出的Word2Vec,对于NLP有极大的帮助促进作用。Word2Vec 通过预测一个长度为c的窗口内每个词周边词语的概率,来作为这个词的词向量。其包含CBOW和Skip-gram神经网络模型,CBOW模型利用词的上下文预测当前的词,Skip-gram利用当前的词来预测上下文。
使用gensim模块的Word2Vec类训练一个词空间维度为128维的XSS语义模型,让机器能够理解<script>、alert()这样的HTML语言。
词向量处理代码:

图2
3.训练XSS检测模型
LSTM 通过刻意的设计来避免长期依赖问题,从左往右推进像传送带一样,将信息从上一个单元传送到下一个单元,和其他部分只有很少的相互作用。LSTM神经网络具有长期依赖信息、理解序列中上下文的知识等特点,可以利用此特点来训练XSS识别模型。
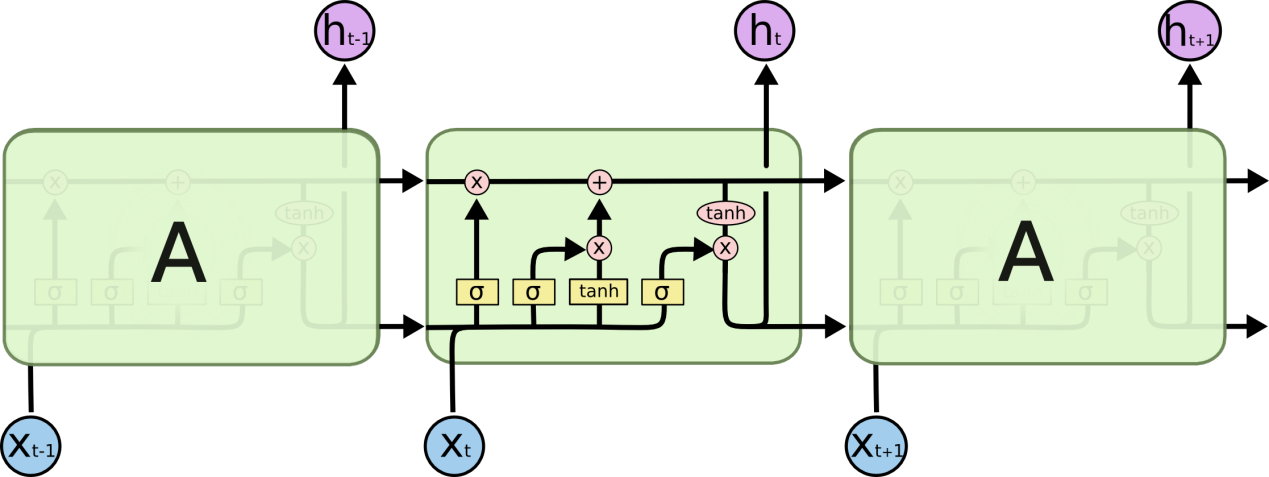
图3
这里使用keras和tensorflow进行训练,训练模型核心代码如下所示:

图4
4.XSS注入检测流程
首先使用结巴分词工具对数据集进行分词,并通过gensim模块的Word2Vec类训练得到XSS语义模型,然后训练集数据通过XSS语义模型转换为矢量,使用LSTM神经网络训练XSS检测模型,最后使用XSS检测模型对测试集数据进行检测,查看是否存在攻击行为。
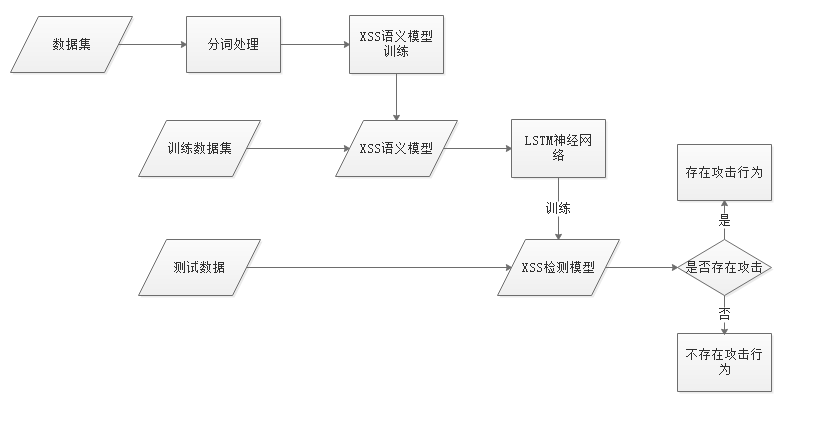
图5
- 0 文章数
- 0 关注者