


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一、“告知-同意”以外
网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息。但是,经过处理无法识别特定个人且不能复原的除外。
——《网络安全法》第四十二条第一款
我国个人信息保护规则围绕着“告知-同意”原则构建,无论是收集、使用几乎都需要向个人信息主体告知并获得同意。征求意见中的《信息安全技术 个人信息告知同意指南(征求意见稿)》就是对“告知-同意”的详尽路线图。但无论怎样设计“告知-同意”都是一条充满荆棘的路途,而在这条路途以外,去标识化就成为值得探索的荒原。
《信息安全规范 个人信息去标识化指南》(GB/T 37964-2019)(“《个人信息去标识化指南》”)是个人信息领域最为重要的国家标准之一,是“告知-同意”以外,个人信息收集、处理的另一条进路。在杨合庆主编的《中华人民共和国网络安全法解读》中,将个人信息去匿名化的重任,交给了国家标准:“对个人信息匿名化处理的具体规则和技术要求等,本条未作具体规定,应当遵守有关标准和技术规范要求。”
匿名化处理的本质在于将个人信息处理为非个人信息,让匿名化处理后的个人信息不再具有人格属性,从而无需再遵守关于个人信息保护的规定。去标识化虽然不完全等同于匿名化,但却是现阶段退而求其次的选择,可以有效帮助企业降低收集、处理个人信息的合规风险,控制个人信息泄露的危害。
二、去标识化是在谈论什么
在GDPR中,主要使用“匿名化”(Anonymization)的概念;美国HIPAA与加州的CCPA更多使用了“去标识化”(De-identification)的概念。在《信息安全规范 个人信息安全规范 》(GB/T 35273-2017)(“《个人信息安全规范》”)中,有匿名化与去标识化两个概念:

根据概念,匿名化的安全程度更高,可以明确匿名化处理后所得的信息不属于个人信息;而去标识化则更强调对标识内容的处理。匿名化概念更符合《网络安全法》下“经过处理无法识别特定个人且不能复原”的表述。在2019年发布的《数据安全管理办法(征求意见稿)》中,就使用了“匿名化”:
第二十条 网络运营者保存个人信息不应超出收集使用规则中的保存期限,用户注销账号后应当及时删除其个人信息,经过处理无法关联到特定个人且不能复原(以下称匿名化处理)的除外。
第二十七条 网络运营者向他人提供个人信息前,应当评估可能带来的安全风险,并征得个人信息主体同意。下列情况除外:
(三)经过匿名化处理;
另外一些《个人信息去标识化指南》中的重要概念:
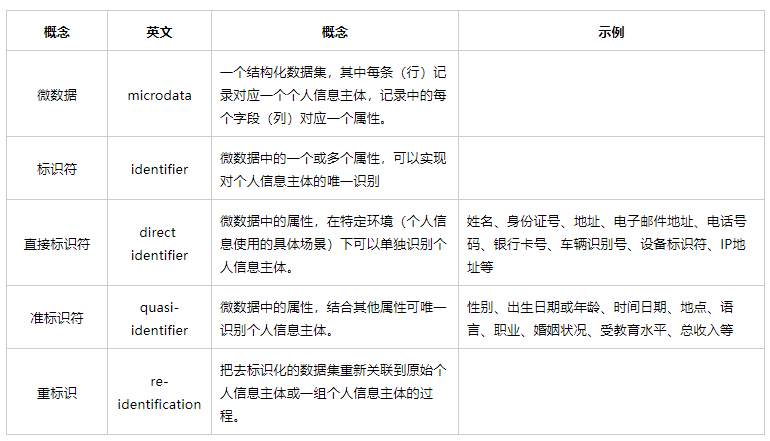 简而言之,微数据是个人信息通常存储的状态,可以想象成为一个大的excel表格,其中每一行对应一个自然人的个人信息,每一列对应不同的属性。举个例子:
简而言之,微数据是个人信息通常存储的状态,可以想象成为一个大的excel表格,其中每一行对应一个自然人的个人信息,每一列对应不同的属性。举个例子:
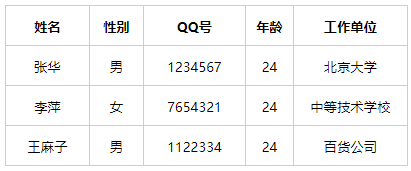
直接标识符就是姓名、QQ号这样的信息,准标识符就是性别、年龄、工作单位这样的信息。去标识化的目标包括:
- 对直接标识符和准标识符进行删除或变换,避免攻击者根据这些属性直接识别或结合其他信息识别出原始个人信息主体;
- 控制重标识的风险,根据可获得的数据情况和应用场景选择合适的模型和技术,将重标识的风险控制在可接受范围内,确保重表示风险不会随之新数据发布而增加,确保数据接收方之间的潜在串通不会增加重标识风险;
- 在控制重标识风险的前提下,结合业务目标和数据特性,选择合适的去标识化模型和技术,确保去标识化后的数据集尽量满足其预期目的。
而去标识化工作的最大挑战,来自于重标识的风险:
- 分离:将属于同一个个人信息主体的所有记录提取出来。
- 关联:将不同数据集中关于相同个人信息主体的信息联系起来。
- 推断:通过其它属性的值以一定概率判断出一个属性的值。
三、深入落实去标识化工作
去标识化工作不止是一项技术工作,也需要一整套的流程:
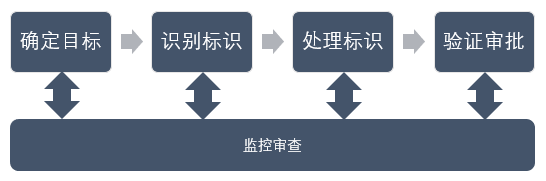
在去标识化工作中,需要首先目前目标是什么,并不是简单给技术人员说我们要去标识这么简单,而是要结合法律法规、数据类型、业务背景等元素确定目标。此外,需要识别处理的数据,不同的数据与目标需要对应不同的技术与模型,在此基础上处理标识符,在处理完成后进行验证。而全程需要监控审查。
对法律人来说,最为关键的,是需要理解去标识化的武器库里有哪些工具可以用,以及这些技术的能力与边界:
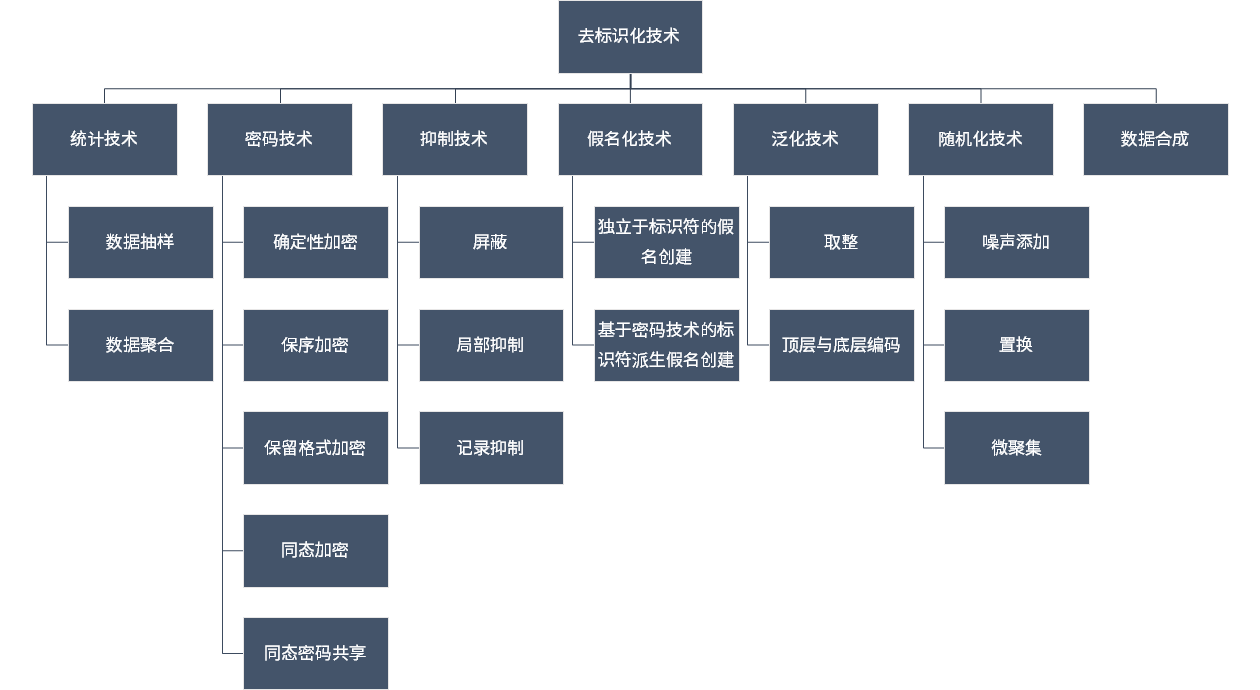
虽然去标识化技术可以让微数据内的个人信息无法轻易被识别,但如果攻击者有其他外部信息的辅助,仍然可能对去标识化技术处理后的个人信息进行重标识。比如在2006年,Netflix举办了一个预测算法的比赛(Netflix Prize),比赛要求在公开数据上推测用户的电影评分。Netflix 把唯一识别用户的信息抹去,认为这样就能保证用户的隐私。但是University of Texas at Austin 的两位研究人员表示通过关联Netflix公开的数据和IMDb网站上公开的记录就能够识别出匿名后用户的身份。
因此,如果针对重标识风险的量化保证纳入目标,则需要选择合适的去标识化模型。《个人信息去标识化指南》中去标识化模型主要有K-匿名模型与差分隐私(Differential Privacy)模型两种。
K匿名算法通过参数k,指定用户可承受的最大信息泄露风险,要求发布的数据中的准标识符至少存在k,比如2-anonymity可以确保处理后的数据里至少有2个人是有相同的属性,让攻击者无法确切了解具体某人是否在公开数据中,并且无法确认具体某人是否具有某项特定的属性,从而保护了个人隐私。差分隐私在向数据添加“噪声”的同时,避免在数学意义上对统计造成影响,从而达到保护隐私的效果。苹果即是通过在设备本地部署差分隐私技术以改进打字、表情、快速查找、浏览器输入等功能;美国2020年人口普查同样会引入差分隐私技术保护隐私。当然K-匿名模型与差分隐私的操作远比我的解释复杂得多,这里只是简单说明。
四、用看得见的方式保护隐私
用技术手段保护个人信息非常重要,而让公众知悉企业为保护个人信息所付出的努力同样重要。技术手段通常会埋没于代码与内部文档中,嵌入产品,虽然提升了安全性但可能并不会给用户直观的感受。现在隐私保护已经成为企业核心竞争力,企业对隐私保护的投入有必要走向前台,因此我们看到了Google、苹果、华为、小米、蚂蚁金服等巨头纷纷发布自己的隐私保护白皮书、不遗余力在发布会上强调自己新测试的隐私保护技术、设立网页解释新技术的原理,以打造隐私保护的形象。企业也有必要做好准备,在发生法律纠纷之时,向监管部门或裁判机构证明自己已经为保护隐私尽到义务,并且付出巨大,从而降低自己的法律责任。
去标识化是一系列的技术措施,也是完整的管理要求,更是需要法律从业者从证据、合规层面做好准备的工作。
- 0 文章数
- 0 关注者