


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
原创:hpw合天智汇
原创投稿活动:重金悬赏 | 合天原创投稿等你来
前言
我想介绍一些不一样的东西-fuzz,也就是大家常说的模糊测试。Fuzz是近几年来安全顶会的热门,投稿难度也越来越大。一次成功的fuzz甚至能挖掘出几十个CVE。我准备在该文章中先介绍fuzz相关的知识,然后以AFL为例演示一个fuzz例子;不足之处还请各位读者斧正。
什么是Fuzz
进行软件漏洞挖掘时,通常有静态分析(staticanalysis)、动态分析(dynamicanalysis)、符号执行(symbolicexecution)、模糊测试(fuzzing)这几种技术手段。
静态分析就是不真正的运行目标程序,但是通过对它进行各种语法、语义、数据流等的分析,来进行漏洞发掘。静态分析是由静态分析软件完成的;它的速度快,但是误报率高。
动态分析就是我们通常见到的大佬们用od一步步跟踪程序运行进行的分析。它的准确率很高,但是需要调试人员丰富的知识储备,而且这种调试方法很难进行大规模的程序漏洞挖掘。
符号执行简单来说,就是试图找到什么输入对应什么样的运行状态,它要去覆盖所有的执行路径。因此,当被分析的程序比较复杂,有很多执行路径时,就会遇到路径爆炸的问题。
模糊测试不需要人过多的参与,也不像动态分析那样要求分析人员有丰富的知识。简单解释,它就是用大量的输入数据自动去执行程序,从而发现哪些输入能够使程序发生异常,进而分析可能存在的漏洞。当前比较成功的fuzzer(执行模糊测试的程序)有AFL、libFuzzer、OSS-Fuzz等。
用AFL来示意一个典型的Fuzz过程
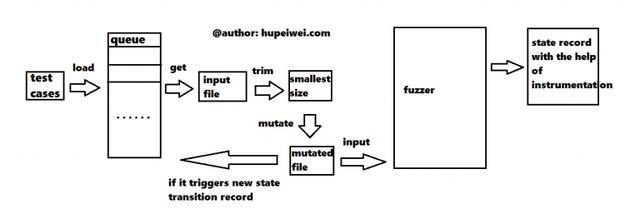
调试人员为程序提供一些输入,即最左侧的testcases,AFL加载后将其放入一个队列中。对于每一次迭代,AFL首先从队列中取出一个testcase,然后对它进行修剪,去除不必要的数据以提高运行效率;再然后对输入进行变异操作,变异的模式很多,可以产生很多新的testcase。对于这些新产生的输入,将它们送到目标程序运行,若能够产生新的执行路径或者导致程序崩溃,就把它再放到队列中。在整个过程中,程序崩溃会被记录下来,它可能代表一个潜藏的漏洞。
Fuzz的技术要点
那么这一项技术主要有哪些难点,或者说影响挖掘效率的点呢?在安全会议上经常能看到对于这些问题的研究,比如2019年USENIX上用粒子群算法来辅助变异操作符的选择,AFL的变体AFLGo其实也是在CSS上发表的。
输入数据
因为要用输入数据去自动执行程序,很明显数据的生成会极大的影响挖掘效率。1.假如目标程序的输入格式是pdf文件,那么不符合该格式的文件就很难进入到目标程序内部进行运行测试。2.即使是符合输入要求的数据,也许数据A和数据B触发相同的执行路径,那么让A和B都运行就是在浪费资源。3.对于单独的数据A,也许其中真正控制执行路径的只是一小部分,那么在其余部分的处理就是在浪费资源。
对于第一个输入格式的问题,generation-basedfuzzer给出了可行的解决方案。简单来说,它要求一些关于输入数据格式的先验知识,这样它就可以更好地根据用户输入数据产生新数据。对于第二和第三个问题,AFL中给出了相应的解决办法。Afl-cmin能够给出输入数据的最小**,也就是会把上述的A和B留其一;afl-tmin则能够将单个输入文件进行压缩。
变异操作
用户给出的数据是有限的,但是进行fuzz测试需要大量的数据,因此fuzzer会根据用户给出的数据产生新的数据,这一过程即所谓的变异操作。那么变异过程中定义哪些变异操作符(即哪些改变原输入数据的操作)?在一次变异时面对多个变异操作符该选择哪个?选用哪些输入数据进行变异?
提高覆盖率
Fuzz的本质就是用输入去检测当前输入对应的执行路径会不会产生可能的漏洞。因此,如果覆盖更多的路径,就意味着可能检测出更多的漏洞。提高覆盖率更像是一个根本性问题,前两个问题的解决其实也是在提高覆盖率。
AFL实战
安装要点
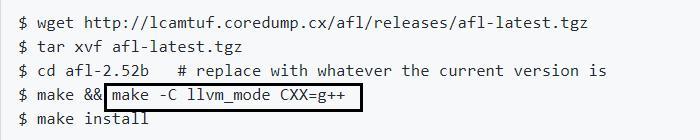
AFL其实有很多模式,除了标准模式,还有llvm模式和qemu模式。得益于clang,llvm模式下fuzz速度更快;qemu模式则可以对二进制程序进行fuzz。有很多人在安装时并没有同时编译安装llvm模式,虽然可以稍后单独编译,但是AFL官方文档中建议如果想要所有系统用户都可以使用llvm模式,就在编译安装AFL时同时安装llvm模式。
安装时还有一个坑:很多人喜欢在docker中使用它,但是别忘了在开启container时加上—privileged选项,否则在下述某一命令执行时会失败。
安装过程我就不赘述了,但是这里推荐一个安装过程。
如果docker不加—privileged这一条命令会失败:

这里是在安装AFL时同时编译安装了llvm模式:
编译安装目标程序
我们选取w3m作为这次的目标程序,在下载源码后,为了AFL能够顺利进行fuzz,我们不能直接用gcc进行编译,而是要用afl提供的afl-gcc进行。
Afl-gcc干了什么呢?其实我们从源码得到二进制程序,要经过从源代码到汇编代码,从汇编代码到机器码的过程。Gcc(特指gcc编译器)能够把源代码变成汇编代码,而as(也是GNU编译器套件一部分)则将汇编码变成机器码。Afl-gcc是gcc编译器的一个封装,它一方面调用gcc编译器进行编译,另一方面指定afl-as而非as进行汇编。Afl-as也是as的一个封装,它一方面分析汇编代码,进行插桩操作,另一方面调用as将插桩后的汇编代码变成机器码。
可能又有人要问了,什么是插桩?简单来说,它就是在目标程序的代码中插入一些额外的代码,来通知fuzzer目标程序的运行情况。
简单了解原理后,来对w3m进行编译:
由于我们只进行fuzz,不想真正安装w3m,因此不用进行makeinstall操作。
收集与处理输入数据
为了能够进行fuzz,我们需要提供一些输入数据。W3m是一款命令行浏览器,因此我们可以收集一些html文件作为输入。注意,AFL作者建议输入文件不要太大,尽量保持在1KB内。这里我找了几个文件作为示例:

就像前面说的,我们可以使用afl-cmin和afl-tmin进行输入数据的缩减。下图是使用afl-cmin取最小**的示例。因为输入太少了,它们都可以触发不同的路径,因此并没有文件被删除。

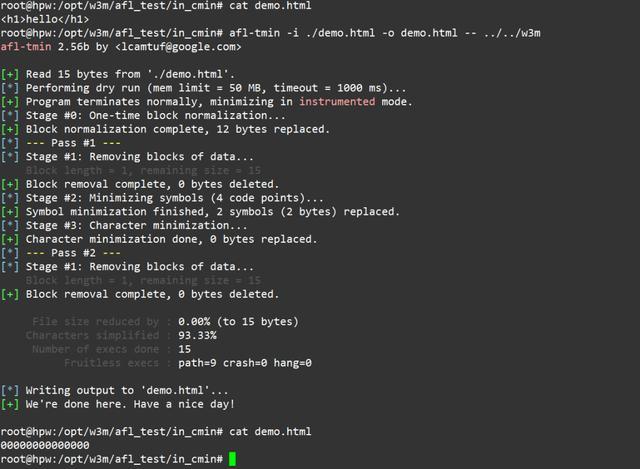
下图是使用afl-tmin对单个文件进行缩减的例子。为了提高速度,你可以写一个脚本多线程对所有输入文件进行缩减操作,否则这一过程是很费时的。
开始运行
通过以下指令开始对w3m的fuzz操作:

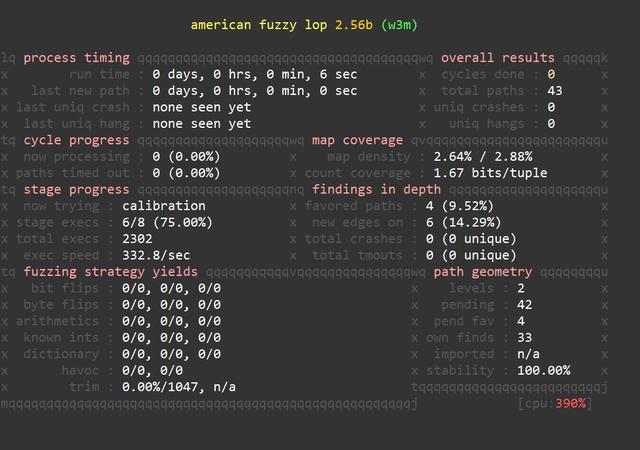
如果你不主动停止,这一个fuzz的过程是不会结束的。在右上角,你可以看到当前已经发现了多少个uniquecrashes。
运行的反思
上述只是一个简单的测试,那么实践中,还有哪些技巧来优化上述的fuzz过程呢?
- 你可以采用AFL的并行模式来提高fuzz效率
- 你可以在AFL运行一段时间后,暂停运行,进入保存队列的文件夹对队列中的test cases进行缩减,然后再继续运行;
- 你也可以通过采用llvm模式来提高速度。
结语
虽然上述fuzz是对本地程序进行的fuzz;其实,借助于丰富的插件,或者编写简单的入口代码,AFL也可以对网络程序,库文件等进行fuzz。写这篇简单的文章希望能够将Fuzz介绍给大家,使得大家能够将fuzz应用到自己的漏洞挖掘中。
合天网安实验室的相关实验(Fuzz之AFL),让你了解AFL的使用方法,通过AFL模糊测试一些简单的软件,学习fuzz的基本方法和思想。
http://www.hetianlab.com/expc.do?ec=ECID5ec5-3232-4f16-8c14-c98b75f8915d
声明:笔者初衷用于分享与普及网络知识,若读者因此作出任何危害网络安全行为后果自负,与合天智汇及原作者无关!
- 0 文章数
- 0 关注者