


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
首先什么是xPath:xPath是一种在xml查找信息的语言
在xPath中,有七种元素的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根节点)。xml文档被当作文档树来解析,树的根被称为文档节点或者根节点。

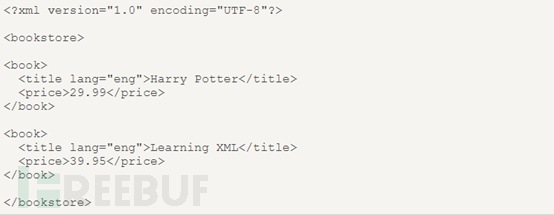
这是一份基本的xml文档的源码,从这份xml源码中可以看出,bookstore为文档节点(根节点),book、title、author、year、price是元素节点。其中book节点拥有四个子元素节点:title、author、year、price,title节点有三个同胞:author、year、price。title这个元素节点拥有一个属性和文本节点,属性节点是lang,值为en,文本节点的值是HarryPotter。
下面还有一些xml节点关系的描述(类似于数据结构中的树):
父:book节点的父为bookstore,book节点是title、author、year、price节点的父。(每个节点只能有一个父)。
子:book是bookstore的子,book节点的子是title、author、year、price的子。
(元素节点可以有零个、一个或者多个子)。
同胞:拥有相同父的节点,类似于树结构的兄弟节点,title的同胞是author、year、price。(节点可以有零个、一个或者多个同胞)。
先辈:节点的父、父的父、父的父的父(无限循环),title元素节点的先辈就是book、bookstore。
后代:节点的子、子的子、子的子的子(无线循环),bookstore文档节点的后代就是book、title、author、year、price、lang。
知道了xml的节点关系还不够,还需要知道它是如何进行查询的,xPath通过路径表达式来选取文档中的节点或者节点集。节点是沿着路径或者步来选取的。
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
nodename:选取此节点的所有接待你
/:从根节点选取
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
.:选取当前节点
..:选取当前节点的父节点
@:选取属性
下面直接来通过js使用xpath查询语法来进行查询
首先写一份关于xpath调用的html(调用的代码写到js中)文件模板,然后准备好一份xml文件用来查询。
js模板的源代码如下:
https://www.runoob.com/try/try.php?filename=try_xpath_select_cdnodes
挨个看一下这份html文件中的js代码(因为只有js代码)
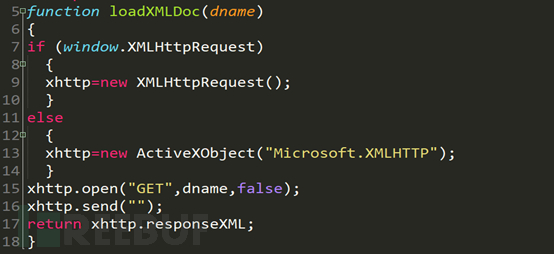
这是js的一个异步调用函数,重要的代码在第15行和第17行,第15行由函数传入的dname函数是xml的路径,第17行返回得到的xml文件。
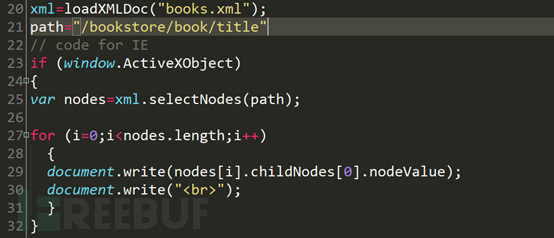
再看第20行,xml变量获得loadXMLDOC函数执行得到的xml文件。21行path变量为xpath的查询语法。第一个if语句,判断是否是IE6及以下浏览器,如果是IE6或以下浏览器,获得对应的查询的到的节点数组之后,将数组中的值遍历输出到页面中。
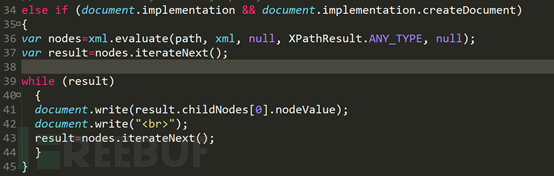
第二个if语句对于非IE6及以下浏览器,执行的过程一样,只是语法稍有不同,非IE6及以下浏览器通过evaluate函数进行查询,格式基本固定,实践一下刚才的几个语法。
查询语法的替换只需要修改path的值就行。

先列出需要查询的语法:
注:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
bookstore:选取 bookstore 元素的所有子节点。
/bookstore:选取根元素 bookstore。
bookstore/book:选取属于 bookstore 的子元素的所有 book 元素。
//book:选取所有 book 子元素,而不管它们在文档中的位置。
bookstore//book:选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore:之下的什么位置。
//@lang:选取名为 lang 的所有属性。
但是只有这些单个的查询有的还不能得到想要的查询结果,需要将它们还有其他的查询语法组合起来才可以。以下是需要配合的一些语法:
谓语(用方括号,为了得到更精确的查询结果):
/bookstore/book[1]:选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()]:选取属于 bookstore 子元素的最后一个 book 元素。
/bookstore/book[last()-1]:选取属于 bookstore 子元素的倒数第二个 book 元素。
/bookstore/book[position()<3]:选取最前面的两个属于 bookstore 元素的子元素的 book 元素。
//title[@lang]:选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang='eng']:选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。
/bookstore/book[price>35.00]:选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title:选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
选取未知节点:
*:匹配任何元素节点。
@*:匹配任何属性节点。
node():匹配任何类型的节点。
例如:
/bookstore/*:选取 bookstore 元素的所有子元素。
//*:选取文档中的所有元素。
//title[@*]:选取所有带有属性的 title 元素。
选取若干路径:
//book/title | //book/price:选取 book 元素的所有 title 和price 元素。
//title | //price:选取文档中的所有 title 和 price 元素。
/bookstore/book/title | //price:选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素
看几个查询的例子:
查询第二个book的title值:/bookstore/book[1]/title

查询所有book的title的值:/bookstore/book//title

查询所有带lang属性的title的值:/bookstore/book//title[@lang]

- 0 文章数
- 0 关注者