


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
什么是数据治理
机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类。
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。
机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。
所谓的训练数据,就是经过预处理(一般是人工标注)后,有相对稳妥、精确的特征描述的数据集,以“样本”形式参与模型开发工作。
训练数据选择一般有以下要求:数据样本尽可能大、数据多样化,数据样本质量较高。
在
在准备训练数据时,
需要把握这样几个原则。
01
训练数据越多越好
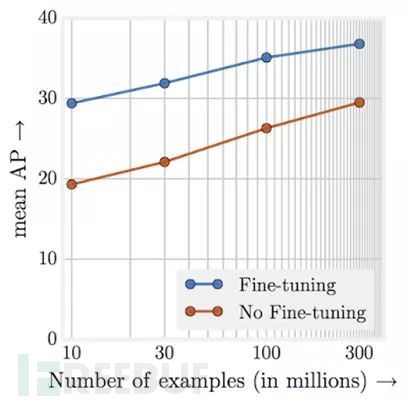
这张图片来自“重新审视那些有效到不合常理的训练数据”,并且展示了即使数据集已经增长到了数亿,图像分类模型的精度依然不断增加。
Facebook最近更加深入的使用大数据量,例如,在ImageNet分类中使用了数十亿个带有标签的Instagram图片,以达到新的记录精度。
这表明,即使对于大型、高质量数据集的问题,增加训练集的大小仍然可以提高模型结果。
02
训练数据准备是费时间的
纽约时报的一篇文章报道,数据科学家在挖掘出有价值的“金块”之前要花费50%到80%的时间在很多诸如收集数据和准备不规则的数据的普通任务上。
混乱的数据是数据科学家工作流中典型的比较耗费时间的。
对这一点我们应该有足够的心理准备,并且在实际工作中,为训练数据的收集留出较充足的时间。
03
单纯增加人力并不能解决一切问题
通过增加人手来标注数据确实可以在短时间内获得大量训练数据,但是根据经验,参与数据标注人数的增多往往会降低数据的准确性。
前面说过,训练数据的正确性对模型质量有非常非常大的影响。
在机器学习领域有个重要原则,GIGO原则(Garbage In Garbage Out),即垃圾进,垃圾出。
就是说如果训练数据就是不准确的无价值的,那么无论你的算法多么优秀都难以获得一个好的机器学习成果。
对于一些简单的常识性的标注工作比如标注商品,判断数字大小、标注方位,基本没有门槛,可以通过简单增加人手解决。
但对专业知识要求很高或数据内容较为复杂的任务,比如对癌细胞X光片的标注,对物种分类的标注这还真就必须得由有一定专业知识的人来做。
对标注的管理往往是对人以及信息的管理。依靠人力的标注很难百分百保证正确性。
为了保证大的正确率。需要通过各种工程手段、管理方法,从立项、准备数据到确定标注群体、确定工期、确定标注规则、标注、质量审核、数据过滤、算法验收等等,确保每个步骤尽量不要出现纰漏。
当然,在保质保量、按时完成的前提下,我们还需要考虑成本。很多人把数据比喻成人工智能的煤炭能源,但目前此行业较混乱,较原始,问题多,行业新,人才少。
更多信息详询:400 100 6790
杭州世平信息科技有限公司(简称“世平信息”),致力于智能化数据管理与应用的深入开拓和持续创新,为用户提供数据安全、数据治理、数据共享和数据利用解决方案,帮助用户切实把握大数据价值与信息安全。
近期热点
你们的五一,居然可以这样……
4.29首都网络安全日倒计时| 网络安全担当 世平在行动
个人信息安全大势下的自我救赎
国资委:将网络安全纳入央企负责人经营业绩考核
- 0 文章数
- 0 关注者