


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
0x01 简单介绍
数据传送时并不支持所有的字符,很多时候只支持可见字符的传送。但是数据传送不可能只传送可见字符为解决这个问题就诞生了base64编码。base64编码将所有待编码字符转换成64个可见字符表中的字符。
0x02 编码原理
被Base64编码之后所得到的所有字符都是在以下这个表当中的。
上表中总共有64个字符,2^6=64所以只需要6个bit位就足够描述所有的表中字符了。计算机中1个字节8个bit,一个ASCII码占1个字节。因此多出来的两位用0填充。比如我用00000110来表示表中数值为6的字符即G
计算机中1个字节8个bit,一个ASCII码占1个字节。因此多出来的两位用0填充。比如我用00000110来表示表中数值为6的字符即G
那么如何用上表中的字符来表达所有的字符呢?
Base64在编码时,首先将所有的待转换字符转成二进制的形式。
例如将”abc”转成110000111000101100011 之后在每个6位比特之前加上00也就是将3个8位字节转换成4个6位字节
由于base64编码是将3个8位字节变成4个6位字节因此最后所得到的字节数目一定是4的倍数。如果不是4的倍数要用=填充
我们从一个例子当中来具体体会一下转换过程
假设待转化的字符是 “example”
转化成二进制之后得到
01100101 01111000 01100001 01101101 01110000 01101100 01100101
example的长度是7因此为了使得最后得到的字符是4的倍数我们要再添上两个字符
01100101 01111000 01100001 01101101 01110000 01101100 01100101 00000000 00000000
然后我们将其按照6位1字符排好
011001 010111 100001 100001 011011 010111 000001 101100 011001 010000 000000 000000
填充00之后得到
00011001 00010111 00100001 00100001 00011011 00010111 00000001 00101100 00011001 00010000 00000000 00000000
再将这些二进制转换成十进制
25 23 33 33 27 23 1 44 25 16 0 0
对照表用字符替换之后得到
ZXhhbXBsZQAA
再将最后的AA换成==即可
ZXhhbXBsZQ==
放到python中解码验证一下

0x03 Python脚本实现
先附上代码
def myBase64Encode(preCoding) :
charTable = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' #字符表
if len(preCoding) < 0 :
return '' #字符串为空则返回空
lackCharNums = 3-len(preCoding)%3
if lackCharNums == 3 : lackCharNums = 0 #整除说明不缺字符
#待转换字符不是3的倍数的情况补全它
for i in range(lackCharNums) :
preCoding = preCoding + b'\x00'
result = '' #用于保存最终结果的str数据
rp = '' #处理补全字符时的暂存变量
#每三个字符处理一轮
for i in range(int(len(preCoding)/3)) :
threeChar = preCoding[i*3:i*3+3] #取三个字符出来
tCode = '' #用于存放三个字符拼接后的二进制数值 文本形式
pCode = '' #暂存变量
for j in range(3) :
pCode = bin(threeChar[j])[2:] #把省略的0补上
lackZeroNums = 8-len(pCode) #省略的0的个数
for x in range(lackZeroNums) :
pCode = '0'+pCode
tCode = tCode + pCode
pCode = ''
for j in range(4) : #每6位一个字符
pCode = tCode[j*6:j*6+6]
rp = rp + charTable[int(pCode,2)]
#处理补全的00字符
result = rp[:len(rp)-lackCharNums]
for j in range(lackCharNums) :
result = result + '='
return bytes(result,encoding="utf-8")
def myBase64Decode(encodedBin) :
charTable = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' #字符表
#如果字符不是4的倍数 返回空
if not len(encodedBin)%4 == 0 :
return ''
tCode = '' #用于存放最终的二进制文本字符串
pCpde = '' #暂存变量
#遍历encodedBin每一个字符
for i in encodedBin :
for j in range(len(charTable)) : #找到表中对应坐标
if chr(i) == charTable[j] :
pCode = bin(j)[2:] #转二进制去除开头的0b
lackZeroNums = 6-len(pCode) #省略的0的个数
for x in range(lackZeroNums) :
pCode = '0'+pCode
tCode = tCode + pCode
pCode = ''
result = '' #储存最终结果
for i in range(int(len(tCode)/8)) :
pCode = tCode[i*8:i*8+8]
result = result + chr(int(pCode,2))
return bytes(result,encoding="utf-8")写的不是很好,仅供参考。这里的解码函数只支持ASCII,如果需要支持所有的字符,可以去了解一下UTF-8 UTF-16 unicode的关系
0x04 逆向案例分析
这是一道在Bugku上看到的逆向题。先来执行看看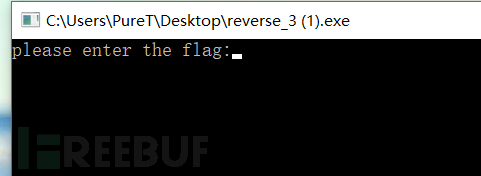
提示输入flag。一般这种题目就要看算法了
在确认无壳之后用IDA打开分析
先打开strings窗口
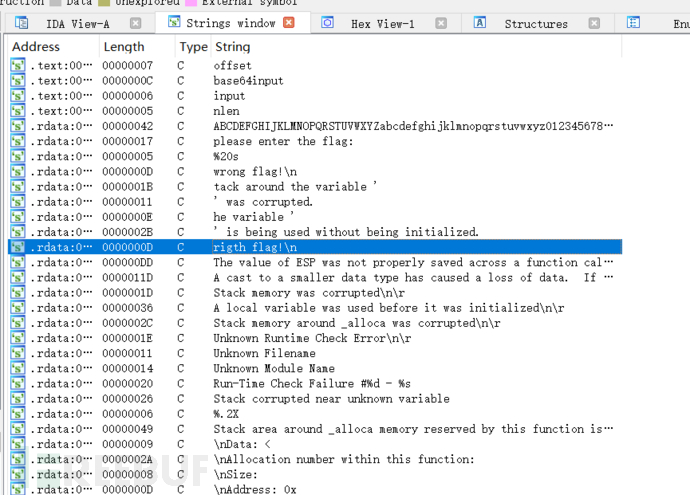
找到right flag跳转
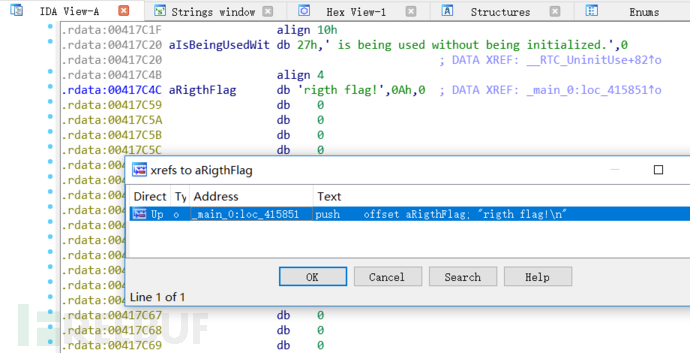 查看交叉引用
查看交叉引用
找到主要执行的部分
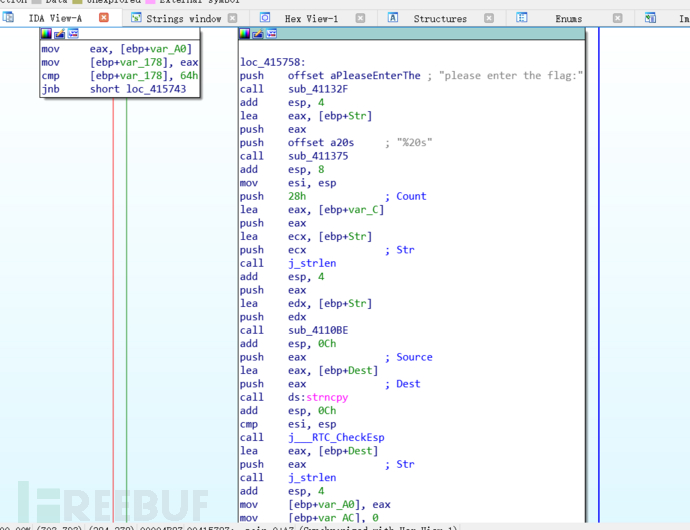
直接F5查看伪代码
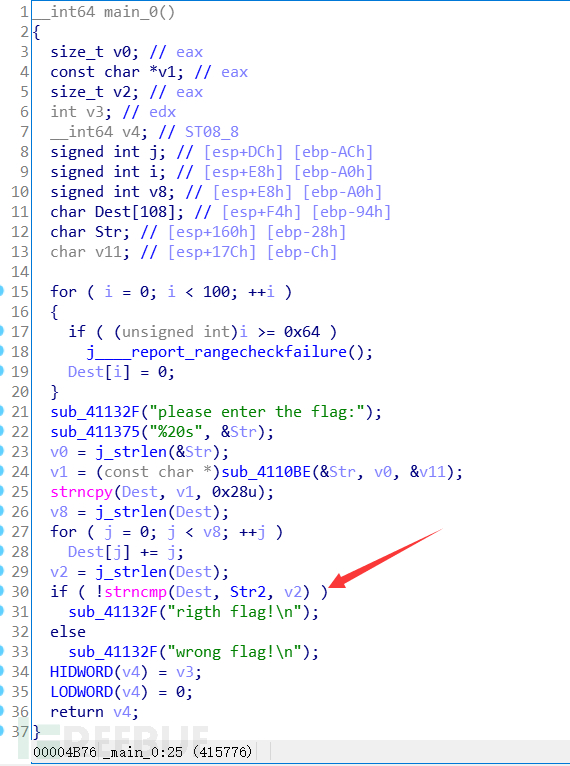
注意到需要让Dest和Str2相同才会输出right flag

而Str2是已知的,那么就可以大概推测出需要将Str2进行某种逆运算才能知道flag
再往上看可以看到
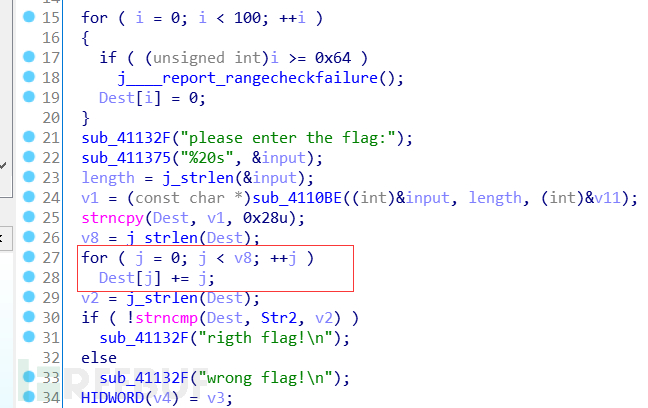
将Dest每一位都进行了移位处理,再往前看关注到一个函数

跟进查看一下

为了方便理解我已经把一些变量名重命名。
其中input为我们输入的字符串,length为输入字符串的长度
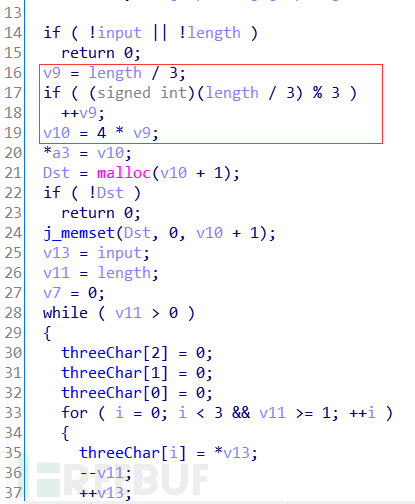
可以看到v9首先将总长度除以3。然后在将v9*4 仔细分析之后会发现v10保存的值就是最后Dst变量的长度。这跟Base64编码前和编码后的长度关系是非常相似的。
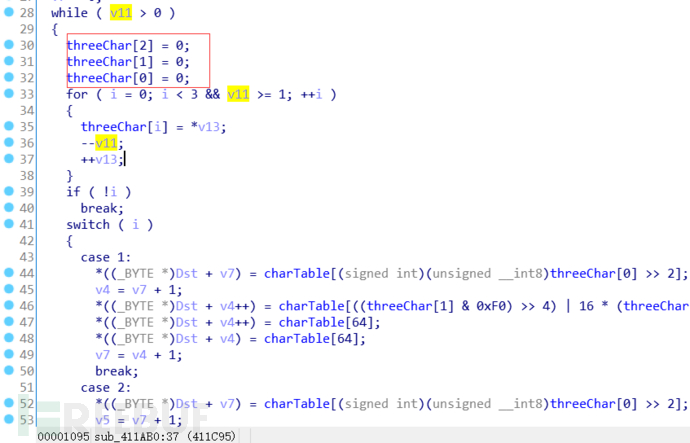
v11变量保存了length的值作为循环的条件变量,然后将threeChar数组初始化。
在经过一个循环之后threeChar数组中存放了i个字符。

三个case分别为三种情况。case 3即i=3时,threeChar正好取了三个字符。
case 2即i=2时,threeChar只取了两个字符。case 1即i=1时,threeChar只取了一个字符。
我们先来分析case 3

首先将threeChar[0]字符右移2位,相当于只取这个字符的前6位并在6位前补上2个0。补全了之后转成了signed int也就变成了字符表中的位置。charTable就是Base64编码的字符表

同样的道理我们再往下看

由于刚刚threeChar[0]字符的前6位已经被取过,我们应该取threeChar[0]的后两位和threeChar[1]的前4位拼接成一个6位再补全0成8位。
这里首先将threeChar[1]与0xF0进行与运算。0xF0转成二进制是11110000,即只保留threeChar[1]的前4位后4位则置0。接着的右移操作将这4位数据移动到二进制的最低位。后边的threeChar[0]&3运算则是保留threeChar[0]的最后2位前边6位置0
看到这里就会发现和Base64编码的原理都对应上了。另外两种情况也都是类似的分析,只不过最后的时候加了一个补全=的代码
到此就可以写出解题脚本了
import base64
a = 'e3nifIH9b_C@n@dH'
b = []
for i in range(len(a)) :
b.append(chr(ord(a[i])-i))
print(base64.b64decode(''.join(b)))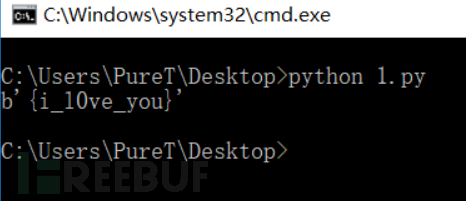
理解都比较初浅,如果有哪里讲得不对,希望各位大佬多多指点~
- 0 文章数
- 0 关注者