


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
引言
在前面主要例举了很多JSP webshell的构造方法,同时也提到了在tomcat jsp解析的时候将会对动态生成的java源码进行编译,在这个过程中将会处理Unicode编码,将unicode编码进行解码
而这里核心是通过跟进编译的过程,了解ecj.jar是如何进行编译的,并且通过其中的细节构造一些混淆方式
多个u绕过
使用注释符逃逸
正文
unicode解码过程
具体的解析位置可以跟踪到org.eclipse.jdt.internal.compiler.parser.Scanner#getNextToken0方法中
这里主要是对前面通过generateJava生成的jsp代码进行一个字符一个字符的进行解析
我们简单的看一下原理
在getNextToken0的开头将会判断是否diet模式
https://wiki.eclipse.org/JDT_Core_Programmer_Guide/ECJ/Parse
官方文档的描述

主要是用来跳过方法体源代码,通过解析源代码中的字符,跳过注释、空白和字符串来定位方法体的结束位置
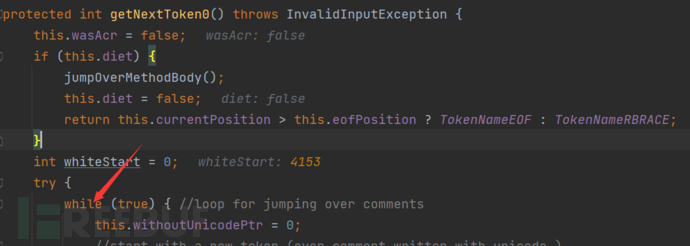
通过一个do-while循环遍历每一个字符
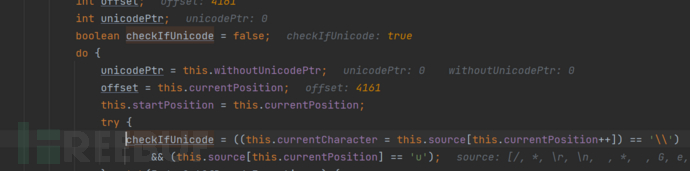
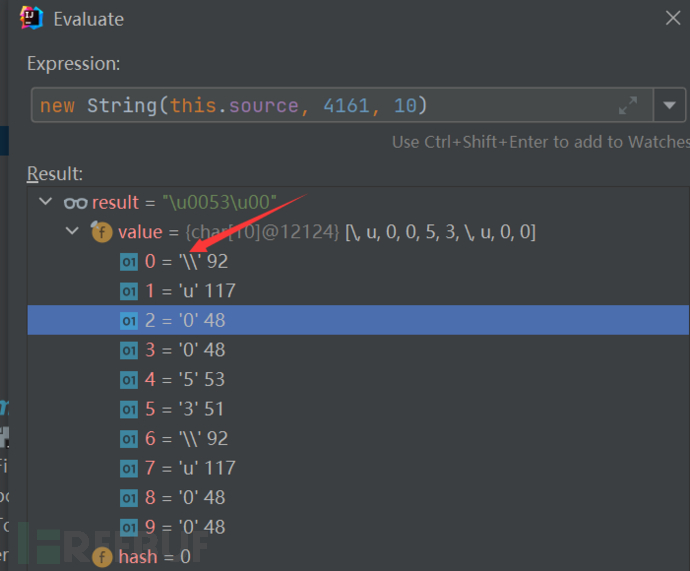
通过将jsp源码抽象成一个char数组,其中的\字符会被转义为\\

通过\u来判断是否处理的是unicode

这里通过jumpOverUnicodeWhiteSpace来判断这个unicode字符解码之后是否是一个空白字符,如果是的话,则通过do-while循环继续解析下一个字符
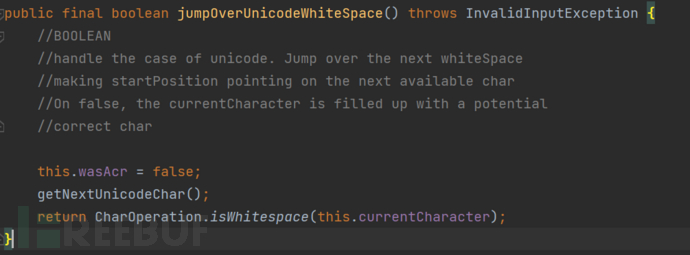
具体是通过getNextUnicodeChar来对当前识别到的unicode进行解码之后将解析到的字符保存在currentCharacter属性中
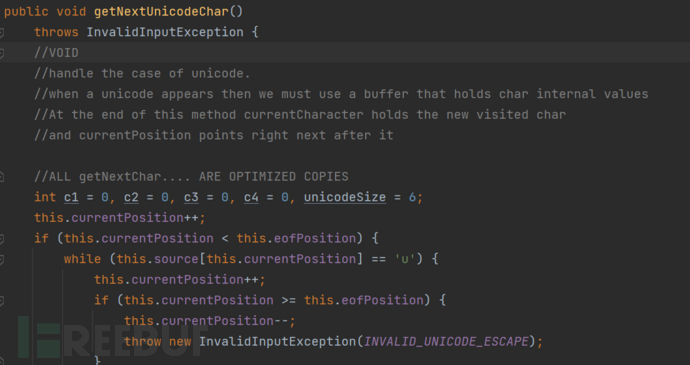
简单描述一下这个方法的逻辑
首先通过
this.currentPosition++;跳过u字符之后的while循环用来循环的处理多个连续的
u字符,所以这也是为什么后面可以通过插入多个u的方式进行混淆,最后获取的u的字符数量会保存在unicodeSize中如果当前位置指针越过文件末尾,或者在连续的 'u' 后不足 4 个字符,表示无效的 Unicode 转义
检查并获取 4 个十六进制数字(0-9, A-F)作为 Unicode 编码的四个部分。如果其中任何一个不是有效的十六进制数字,同样抛
- 0 文章数
- 0 关注者