


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
WebShell脚本检测机器学习实践
webshell作为黑客惯用的入侵工具,是以php、asp、jsp、perl、cgi、py等网页文件形式存在的一种命令执行环境。黑客在入侵一个网站服务器后,通常会将webshell后门文件与网站服务器WEB目录下正常网页文件混在一起,通过Web访问webshell后门进行文件上传下载、访问数据库、系统命令调用等各种高危操作,达到非法控制网站服务器的目的,具备威胁程度高,隐蔽性极强等特点。
由于其显著危害性,webshell的检测一直是安全领域一个长盛不衰的话题,宏观上可分为运行前静态检测和运行后动态检测两种。简单来说,黑客入侵web服务器,不管是上传webshell还是在原文件中添加后门,对文件静态属性进行分析的方法属于静态检测;webshell执行时,browser/server数据通过HTTP交互,我们对交互行为和信息进行分析,这类方法统称为动态检测。静态检测方法预测数据采集成本较低且便与部署,缺点是容易被各种混淆及加密方法绕过;采用动态检测理论上可以避免被绕过,但测试数据采集成本较高,需要去搭建一个安全的沙箱环境收集流量特征,缺点是在生产中也只有当webshell活跃状态时才能发挥效果。
1 静态检测思路
1.1 文件名检测
最初人们通过构建一个webshell文件名字典去匹配网页文件名,查看是否存在webshell文件。我一开始是不敢相信的,但这是真的,黑客随便拿一个webshell文件来用,甚至都不需要修改文件名就能达到入侵的目的,可见最初工业界对网络安全的不重视。附上webshell文件名,大家感受下:
渗透小组专用ASP小马
vps提权马
asp一句话
改良的小马
国外免杀大马
backdoor.php
1.2 特征码匹配法
特征码匹配法目前普遍采用的一种静态检测方法,通过对webshell文件进行总结,提取出常见的特征码、特征值、威胁函数形成正则,对整个网页文件进行扫描。特征码匹配的方式优点也是十分突出,能对webshell后门精细化分类具备高可解释行且逻辑结构简单,便于在苏宁安全平台的工程化部署。同时缺点也很明显,对安全专家的知识广度和深度高度依赖,且只能识别已知的webshell模式,同样对混淆加密webshell效果有限。对安全人员来说,维护起来极其繁琐,拆西墙补西墙,陷入不断打补丁的死循环,针对大文件对性能消耗较高。厂家更多情况下是采用正则先做一遍筛选,命中严格正则的直接定性,命中宽泛正则的进一步采取其他分析方式。
rule=r'(array_map[\s\n]{0,20}\(.{1,5}(eval|assert|ass\\x65rt).{1,20}\$_(GET|POST|REQUEST).{0,15})'
rule='(call_user_func[\s\n]{0,25}\(.{0,25}\$_(GET|POST|REQUEST).{0,15})'
rule='(\$_(GET|POST|REQUEST)\[.{0,15}\]\s{0,10}\(\s{0,10}\$_(GET|POST|REQUEST).{0,15})'
rule='((\$(_(GET|POST|REQUEST|SESSION|SERVER)(\[[\'"]{0,1})\w{1,12}([\'"]{0,1}\])|\w{1,10}))[\s\n]{0,20}\([\s\n]{0,20}(@{0,1}\$(_(GET|POST|REQUEST|SESSION|SERVER)(\[[\'"]{0,1})\w{1,12}([\'"]{0,1}\])|\w{1,10}))[\s\n]{0,5}\))'
rule='\s{0,10}=\s{0,10}[{@]{0,2}(\$_(GET|POST|REQUEST)|file_get_contents|str_replace|["\']a["\']\.["\']s["\']\.|["\']e["\']\.["\']v["\']\.|["\']ass["\']\.).{0,10}'
rule='((eval|assert)[\s|\n]{0,30}\([\s|\n]{0,30}(\\\\{0,1}\$((_(GET|POST|REQUEST|SESSION|SERVER)(\[[\'"]{0,1})[\w\(\)]{0,15}([\'"]{0,1}\]))|\w{1,10}))\s{0,5}\))'
rule='((eval|assert)[\s|\n]{0,30}\((gzuncompress|gzinflate\(){0,1}[\s|\n]{0,30}base64_decode.{0,100})'
rule='\s{0,10}=\s{0,10}([{@]{0,2}\\\\{0,1}\$_(GET|POST|REQUEST)|file_get_contents|["\']a["\']\.["\']s["\']\.|["\']e["\']\.["\']v["\']\.|["\']ass["\']\.).{0,20}'
rule='(include|require)(_once){0,1}[\s*]+[\"|\']+[0-9A-Za-z_]*\://'
rule='([^\'"](include|require)(_once){0,1}\s{0,5}(\s{0,5}|\(\s{0,5})["\']([\.\w\,/\\\+-_]{1,60})["\']\s*\){0,1})'
rule='((include|require)(_once){0,1}(\s{0,5}|\s{0,5}\(\s{0,5})[\'"]{0,1}(\$(_(GET|POST|REQUEST|SERVER)(\[[\'"]{0,1})\w{0,8}([\'"]{0,1}\])|[\w]{1,15}))[\'"]{0,1})'
rule='\s{0,10}=\s{0,10}([{@]{0,2}\$_(GET|POST|REQUEST)|[\'"]{0,1}php://input[\'"]{0,1}|file_get_contents).{0,20}'
rule='gzdeflate|gzcompress|gzencode'
rule = '(preg_replace[\s\n]{0,10}\([\s\n]{0,10}((["\'].{0,15}[/@\'][is]{0,2}e[is]{0,2}["\'])|\$[a-zA-Z_][\w"\'\[\]]{0,15})\s{0,5},\s{0,5}.{0,40}(\$_(GET|POST|REQUEST|SESSION|SERVER)|str_rot13|urldecode).{0,30})' 1.3 语义分析
语法分析可以看作是特征匹配的抽象升级版。 其根据脚本语言的编译实现方式,对代码进行清洗,抽取函数、变量、系统关键字等字符串单元,来实现危险函数的捕获。通常将源代码拆分后结构化为中间状态表示,再在抽象后状态的基础上进一步分析。相比特征正则匹配,可以做到更精细化的关联分析,在检出率和误报率上提升一大步。该方法要做到非常好的检出效果相对困难,实现复杂,对开发人员要求较高且十分耗时,性价比并不是很高。
Pecker Scanner检测工具就是基于语法的php文件webshell检测方法。该方法对检测文件代码进行清洗后,分析其变量、函数、字符串来实现关键危险函数的捕获,这样可以很好地解决漏报,但同时也存在大量误报。
1.4 统计特征检测
针对某些变形混淆的webshell,代码在编码风格上会明显有别于正常脚本,同时会表现出特殊的统计特征。NeoPI就是一个典型的代表,它通过多种统计方法来检测文本/脚本文件中的混淆和加密内容,辅助检测隐藏的webshell。进一步剖析,NeoPI通过计算下属5中特征来标注可疑文件:
- 字符级重合指数(LanguageIC): 字符重合指数越低,说明代码越混乱,有可能被加密或混淆过
- 字符级信息墒(Entropy):度量代码中所使用字符的不确定性,可用gini系数来代替使计算更高效,二者具备相似性质(跟上面的字符重合指数也具有相似的效果)
- 最长单词长度(LongestWord):最长的字符串一般是base64编码,存在被编码或被混淆的可能
- 恶意代码签名特征(SignatureNasty):统计代码中包含的恶意代码片段个数
- 压缩特征(Compression):计算代码文件压缩比
上述5种类型的特征重点在于识别混淆代码,但正常代码被base64编码后也会被识别为高风险webshell文件,产生一系列误报,同时对未经过编码和混淆的webshell代码不敏感。在实际应用中可以考虑对恶意代码片段的正则进行完善,利用gini系数来代替信息墒等方式对其进行改进。另一方面,我们也可以围绕上述特征提取思想来挖掘出更多有效特征,与机器学习结合,以取得更佳效果。
2 机器学习方法实践
上面提到了几种webshell静态检测的方法,无论是特征码匹配、语义检测还是特征统计方法,都需要建立在安全从业人员webshell原理深入的理解基础之上进行提炼,这是个非常耗时的过程,同时维护起来也是异常繁琐。
苏宁在传统检测方法的基础之上,利用机器学习对webshell脚本检测进行赋能(详细使用方式可以参考webshellDc_v0.1。)。我们把webshell检测转换成一个NLP领域的文本分类的问题,通过投喂训练数据的方式锻炼模型对正常脚本及webshell脚本代码组合的记忆能力,以达到识别的效果。
2.1 训练样本获取
可选择的ML方法有很多,无论是传统机器学习或者深度学习,稍微有些NLP经验的前辈都能做出一个很好的解决方案,无非是变换一下特征提取方式和模型。重点其实是数据,掌握的websehll样本越丰富,训练出来的模型效果就越好。要培养一个某领域的专业人才,需要不断去学习该领域的专业知识信息,反复锤炼,其中知识的质量和数量缺一不可,模型训练也是如此。算法的改进是不断去触摸当下数据集所能达到的上限,高质量的数据集才是AI项目性能的基石。苏宁除了主机入侵检测系统观察到的webshell样本外,还收集了160个Github项目的webshell样本用于训练。
有了黑样本,白样本的收集就相对简单一些,但也不代表白羊本不重要,白样本的分布和广泛性也比较重要。我们可以在Github、码云、GitLab、Gitee、Coding等开源直接搜索对应文件类型的项目(由于jsp是建立在java基础上的一种网络编程语言,因此在正常jsp样本不充分的情况下可考虑用java文件来代替 );第二种方式是在条件允许的情况下,将自身业务环境中对应文件类型的文件拿来作为白样本,毕竟在自家数据环境中被教育出来的模型,在解决自家问题的时候也更加驾轻就熟,以此避免模型上线时因训练数据不充分造成的水土不服问题。
2.2 特征处理和模型训练
模型训练借鉴了兜哥《web安全之深度学习实战》书中第十一章思想,采用CountVectorizer和TfidfTransformer对n-gram后的样本进行特征向量处理,分别采用多层神经网络、XGBoost、朴素贝叶斯进行训练,其中MLPClassifier模型表现较好。主要特征处理和训练代码如下:
def features_process(negativedir, postivedir, maxfeatures):
webshell_texts = read_dir(negativedir)
normal_texts = read_dir(postivedir)
webshell_number = len(webshell_texts)
normal_number = len(normal_texts)
texts = webshell_texts + normal_texts
webshell_lables = [1] * webshell_number
normal_lables = [0] * normal_number
lables = webshell_lables + normal_lables
logger.info("白样本总量:%i" % normal_number)
logger.info("黑样本总量:%i" % webshell_number)
countvectorizer = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
min_df=1, analyzer="word",
token_pattern=r'[^\w\s]+|\b\w+\b',
max_features=maxfeatures)
tfidftransformer = TfidfTransformer(smooth_idf=False)
cv_x = countvectorizer.fit_transform(texts).toarray()
tf_x = tfidftransformer.fit_transform(cv_x).toarray()
joblib.dump(countvectorizer, "model/countvectorizer_" + options.version + ".pkl")
joblib.dump(tfidftransformer, "model/tfidftransformer_" + options.version + ".pkl")
return tf_x, lables, countvectorizer, tfidftransformer
def evaluation(y_test, y_pred):
logger.info("准确率:%s" % metrics.accuracy_score(y_test, y_pred))
logger.info(confusion_matrix(y_test, y_pred))
logger.info(classification_report(y_test, y_pred))
def train(trainset, lables, mode, seed):
x_train, x_test, y_train, y_test = train_test_split(trainset, lables, test_size=0.3, random_state=seed)
clf = model_collection(mode)
clfname = "model/" + mode + "_" + options.version + ".pkl"
clf.fit(x_train, y_train)
logger.info("训练集评估:")
evaluation(y_train, clf.predict(x_train))
logger.info("测试集评估:")
evaluation(y_test, clf.predict(x_test))
joblib.dump(clf, clfname, compress=3)2.3 评估
代码中通过featuresprocess函数传入黑白样本文件地址和maxfeatures,同时完成CountVectorizer和TfidfTransformer模型的训练。实际操作中可根据训练样本的实际情况对CountVectorizer模型中maxfeatures和ngramrange参数进行微调已达到最佳效果。项目分别采用混淆矩阵和ROC曲线对模型进行评估。
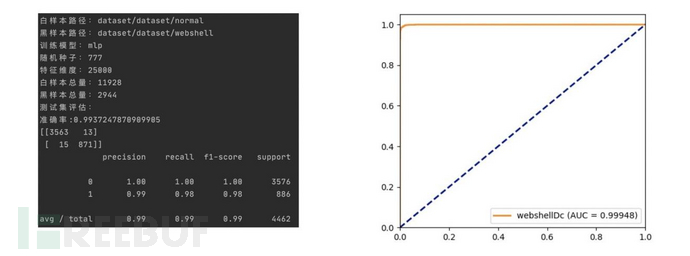
3 结语
高质量的训练样本是决定模型好坏的先决条件。在实践中,我们采用了苏宁安全产品历史以来积累的上万个黑样本,同时添加了数百个Github项目黑样本,来保证训练数据的多样性。模型在攻防同事的模拟测试中,取得了多数在线及离线开源webshell检测器更好效果。模型上线后也取得了比传统静态检测手段更高的检出率和更低的误报率,提升了苏宁主机入侵检测系统对webshell的静态检测能力。
然而无论什么方式都会有被绕过的风险,AI模型更是如此。 工具在进步,对抗在升级,AI安全模型的绕过和防绕过技能,以后也会成为AI安全从业者的必备素养。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者