


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文原创作者:DX安全团队----0d9y,本文属FreeBuf原创奖励计划,未经许可禁止转载
一个功能完善可以自定义的渗透系统可以帮助你省下很多的时间来思考目标站点的弱点,本文章就是教你怎么搭建一个Web入口的集群式渗透系统。
0×00 介绍
不知道大家在平时渗透中,有没有觉得在自己电脑上进行渗透非常的不方便。需要费一部分的脑力进行窗口切换,结果查看,并且有时还要黏贴到下一个工具进行自动化渗透等等。而我们的电脑本身运算能力有限,带宽有限,稳定性有限,都不能最大程度的加快我们的渗透进程,所以在一个月前,就想搭建一个Web平台的集群渗透系统,把任务下发到服务器去做,我们只要等一段时间浏览下网页看看结果就好,最大程度解放双脑,而且速度和稳定性都有所提升。
目前项目已经成型,但是因为代码中包含很多我平时的渗透思想和一些自己的检测手段,所以暂时不能开源,不过我会教大家如何去搭建一个属于你自己Web端的任务分发式渗透系统,让大家都能解放自己的双手。
0×01 要求
既然是Web渗透平台,其中的难度肯定是有的,希望大家首先熟悉Python、Html、并且至少拥有一台自己的服务器。我会讲解如何搭建,从前端都后端到服务器脚本的部署,以及搭建中容易遇到不好解决的一些问题,如有在制作过程遇到坑请在下面留言,本人会一一解答。另外希望大家有实践动手能力。
0x02 结果展示
为了激起大家的搭建欲望和搭建兴趣,能够最终或大或小都搭建出一个自己的平台, 我先将自己搭建成功的Web系统给大家看一下,也为了能给大家感受一下到底是一个什么样的东西。
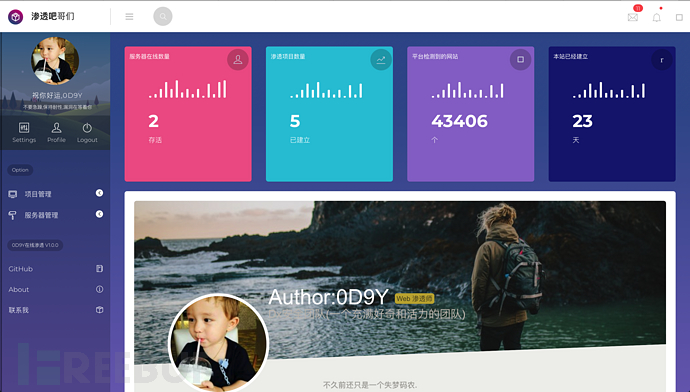
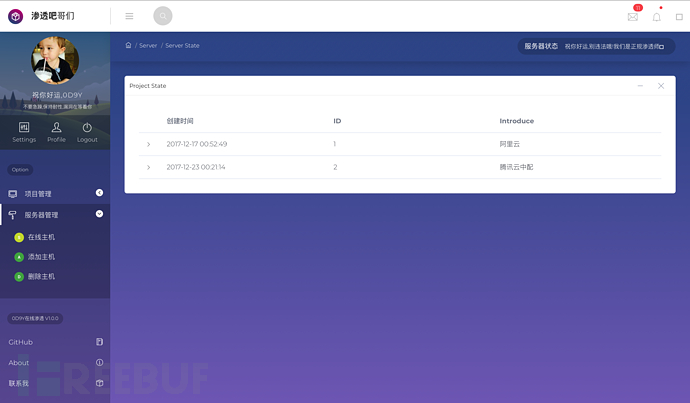
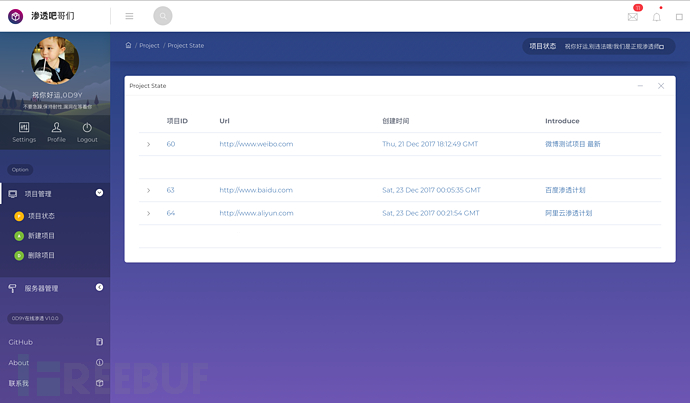
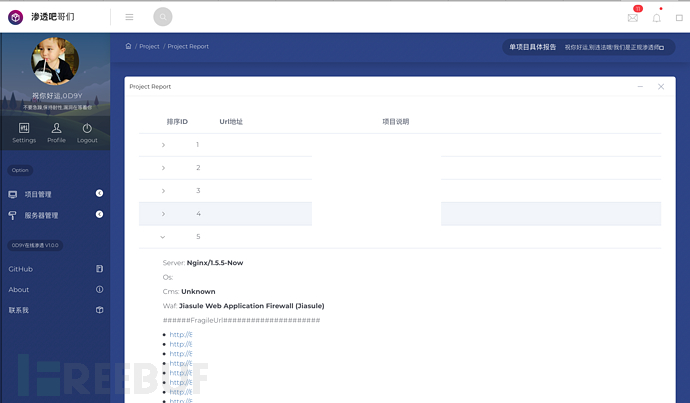
0×03 前端 后端 渗透脚本
后端提供Api返回数据库中的一些信息的JSON,然后前端通过Ajax来获取,这样前后端维护起来方便。
可是这有一个问题,前端接收JSON信息显示,后端返回信息,那后端的信息是哪里来的?后端是怎么获取到扫描器的结果的呢?
很简单,在数据库中设置一个Flag,写一个python脚本检测这个Falg, 譬如我本次设置的State,一旦扫描器脚本检查到State为0的项目,就把数据哪来过开始扫描,并且吧State设置为1,可以通过yield来进行协程,把每一次的数据异步的存在数据库,而不用等到全部数据都扫描完毕在存,一个浪费时间,二是万一程序中断,另外提一句,日志的输出很重要,因为开始做的时候没注意导致浪费了不少时间。这样就可以Web前端,Web后端,Web扫描器所在的服务器统统解耦分开,维护起来更加的方便,定位问题起来更加的精准。
另外在提及一些Web扫描器如何实现可扩展性。如下,因为扫描的过程一定是有先后的,我们把所有的定义扫描全部都写在start里面,然后在setting设置里面添加扫描的先后和扩张一些扫描的脚本,譬如Domain一定是第一个进行的,所以在第一个列表里面,UrlPath、OS、Server、CMS、Scrapy都是在Domain获取到的结果中进行的 ,而Sql、Xss、Jsonp都是在Scrapy爬到的链接中进行的,如果后续要扩张检测一些cms的1day之类的,就可以把脚本加载第三个列表,把函数在家start里面
if datatmp:
for funlisttmp in checkFunciton:
for fun in funlisttmp:
fun(datatmp)
from lib.start.start import *
checkFunciton=[[Domain],[UrlPath,OS,Server,CMS,Scrapy],[Sql,Xss,Jsonp]] #
0×04 利用到的框架
前端:VUE.js.
jQuery Bootstrap
后端:Python Flask
数据库:Mysql
可以去Github搜索一个已经将基本样式包装好的然后进行修修改改,遇到不会的马上去搜索,都可以摸索出来的。这里我给大家推荐一个在线通过拉拉小框框就可以做一个漂亮的前端工具,我刚开始入门就是在这里拉框框看源码一点一点学会的,各位可以先不用在意样式美丑与否,我们的目标就是做一个给自己平时使用的Web渗透系统而已 Bootstrap前端在线生成,VUE组件,再说的简单点,我们就是要一个能够写入和读取展示数据库都东西而已,只不过Web来展示比较方便
后端Python Flask是一个非常轻巧,侵略性很低的框架,只要你pip install flask安装好了,import进来即可。使用方法如图所示,这个框架也是我对比几个PythonWeb框架后最推荐大家选择的一个,因为轻巧,入门十分容易,而且功能已经够用。只要在定义的函数上方加上@api.route('/url') 然后访问http://ip:port/url ,就会自动执行下方的函数,我们在用pymysql,进行数据库读取操作,最后把数据进行读取,用Flask自带的json解析函数返回,一个API接口就完成了。
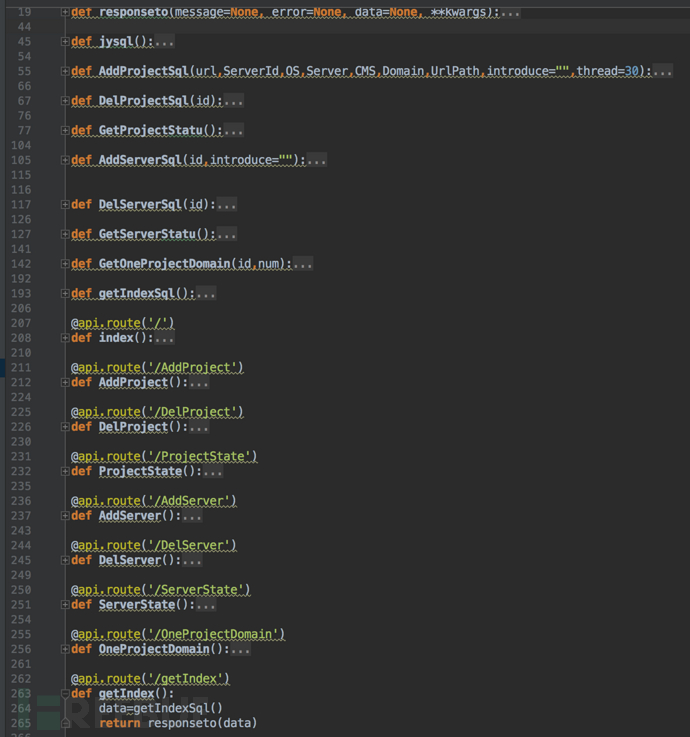
我这里定义了8个API接口,大家可以参考参考分别是
(1))/getIndex 接口。 这个接口返回的是服务器中建立了多少项目,有多少集群服务器,扫到了多少可能存在漏洞的网站。用于一开始进入主页的时候的信息展示,让开发者了解更多信息
(2)/AddProject接口 添加一个项目,当Web端用户需要添加项目的时候,就访问如下接口,以POST的方式接受数据
要被扫描的地址url 、 进行扫描的服务器 ServerId 进行扫描的项目 OS Server Cms UrlPath Scrapy Xss Sql备注信息 introduce 线程数量 ,添加的时候把需要扫描的项目的字段标记为1
(3)/DelProject删除项目 删除一个项目,需要提交参数Id
(4)/ProjectState 返回目前项目的状态 ,让使用这可以清楚的看到当前项目扫描到扫描程度。可以利用State和一些项目的参数,譬如如果State为0 那么说明整个项目都还没有开始 ,State一旦为1 把)OS Server Cms UrlPath 等字段统统标记0 开始执行标记为1 结束标记为2
(5)/AddServer。添加服务器信息 , 给这个服务器设置一个ServerId 每次ServerId为他,就说明是想调用这个服务器进行本次扫描
(6)/DelServer。删除服务器信息 ,提交要删除的服务器ID
(7)/ServerState 服务器状态,返回当前服务器有多少个,他的备注是什么,在添加项目和删除服务器的时候都可以用到
(8)/OneProjectDomain 获取某一个项目的具体信息 当我想获取结果的时候就要调用这个API 传入具体的参数,还需要传入像知道的具体页数。因为有时候一个项目的结果可以能上百上千个,如果一次性AJAX获取的话可能会照成网络堵塞,所以需要AJAX异步来调用 给一页设置为10个数量,通过num来返回具体某一页。每当AJAX成功的回调函数就是下一页,不成功则再次获取这一页
值得一提的是,因为API接口和前端是分离的 对有没有权限获取一定要做好把控,访问有人把你的扫描结果通过API给拿走了,我这里有2种解决办法 我采取的是第二种。
第一种就是验证seesion 吧前端框架和FLASK合并在一起,只有seesion有权限才可以
第二种就是在post参数里面加上一个参数,这个参数通过某种基于时间的加密手段,配合前端js 达到一定程度的加密,是的只有一定程度,因为前端js可以破解只能增加一些成本
这些接口分别对应上方展示图的各个页面,其实就是一些与数据库有关的操作,所以数据库结构其实很重要,大家可以在建立数据库的时候也可以参考一下,这个布局也是我当前认为比较好的数据库布局,比较清晰。
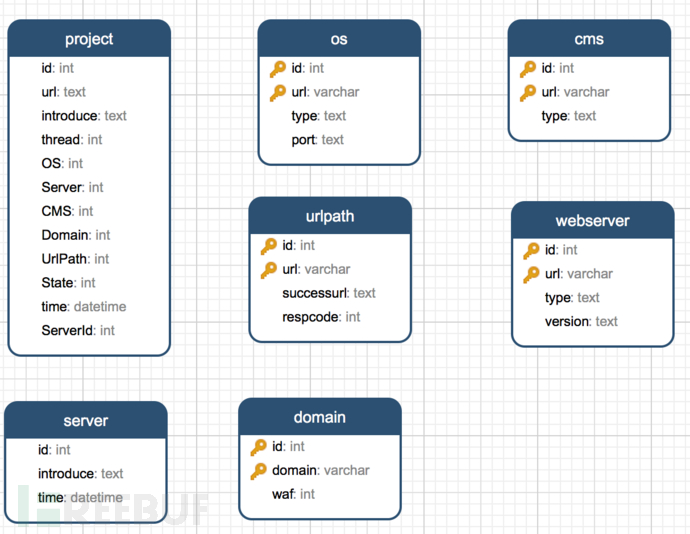
数据库Mysql 这个大家肯定都熟悉吧,Sql注入的基础,之所以选择Mysql,还是因为轻巧。上图就是我的数据库的结构图。可以看到,一共7个表,其中project和server分别的表示项目状态信息和集群服务器状态信息的,其中project表中的url代表要渗透的网站,thread是渗透要执行的线程数量OS、Server、CMS、Domain、UrlPath代表是否执行该种渗透检测。而State则表示当前项目是否在执行,也是上文提到的FLAG。其他五个表分别是储存脚本执行后的一些关键渗透结果数据,我给每一个渗透选项都建立了一个表,这样结构比较清晰,采用project的id+脚本获取的信息为主键。使得每次集群服务器运行完毕某一个脚本后生成的数据直接存到数据库然后可以通过Python Flask提供的API接口让前端Ajax调用。
0×05 如何修改一些开源的脚本到我的Web渗透系统来
其实这个系统,最关键的东西还是集成大家一起牛逼的开源扫描器,和自己写的一些用起来比较顺手的扫描器整合起来,然后利用Web这个便捷的入口进行操作,那怎么样把别人的扫描器的数据结果存入数据库呢?首先,我在开源项目中使用了他人的脚本有lijiejie的二级域名爆破脚本和Sublist3r的二级域名搜索脚本(其设计原理是基于通过使用搜索引擎,从而对站点子域名进行列举。)都是开源的,网上可以搜到,可是怎么样把他们改造成我们的渗透利器的一部分呢?首先抓住一点,我们要把他们关键的输出数据修改成符合我们数据库结构的样子在输入到数据库。可以发现,基本上每个开源的渗透脚本都是会有把关键信息print输出出来的,所以我们的首要目标就是搜索print 看看是否有定义某一个信息输出类,如果有,就找到类包装的输出关键信息的那个函数,在函数下面吧输出的信息改造成你要想的数据,然后储存在一个事先定义的全局变量里,然后在设计一个函数把变量里的关键信息进行储存到数据库中即可。如果没有这个类,那就直接全局查找print,查看哪个print输出点输出的信息是我们要的,一般这些工具都是多线程或者多进程设计的,print关键信息的基本上就一句到二句。找到后就同上即可。
0×06 总结与预告
如果大家对这种系统的搭建感兴趣,我可以后续继续写几篇来详细介绍一波大家问题存在最多的地方。然后我推荐大家的一种方法就是先去做,做的过程遇到不懂得再回过来看,会发现我把很多你可能会遇到的大问题都已经总结在上面了,当然也有可能我忽略了一些坑,而你刚好遇到了,欢迎你留言或者来我的博客找到我的QQ或者微信来交流交流。
*本文原创作者:DX安全团队----0d9y,本文属FreeBuf原创奖励计划,未经许可禁止转载
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者