


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文作者:feiniao,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
1. 分析背景
1.1 情况
此文是基于一次安全事件所引发的思考,在应急后进行的安全分析与挖掘。分析的数据基于DNS数据,这也是本人的一次尝试,各位大佬有好的思路或方法欢迎及时补充。
具体情况为大量政府及高校网站出现博彩类信息,很多网站首页打开会跳转到博彩站点,详细如下:
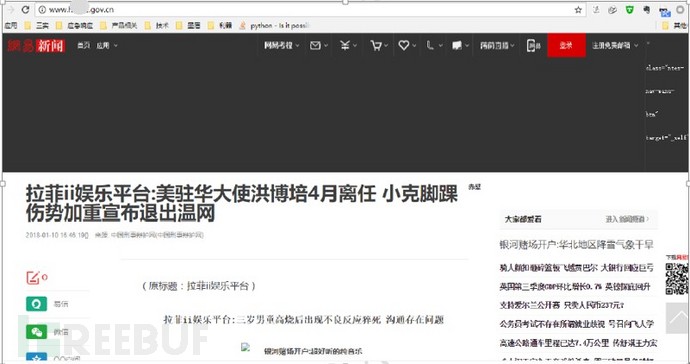
图-网站首页出现博彩信息
随意点击页面任意按钮,会跳转到博彩站点,具体如下:
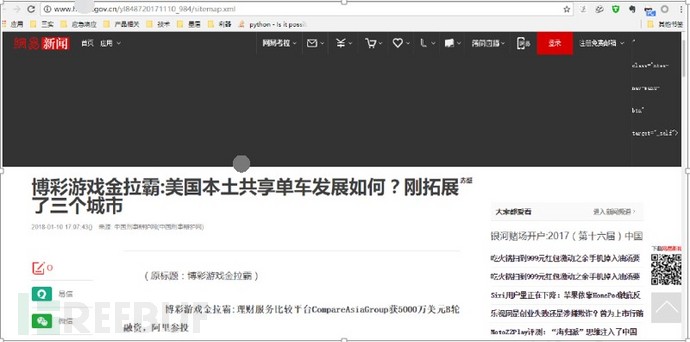
图-点击相关功能按钮会跳转到博彩内容
1.2 分析验证
对其进行分析,发现这些打开跳转到博彩页面都是因为其DNS解析被恶意修改,解析到107.151.129.28这个国外IP上。
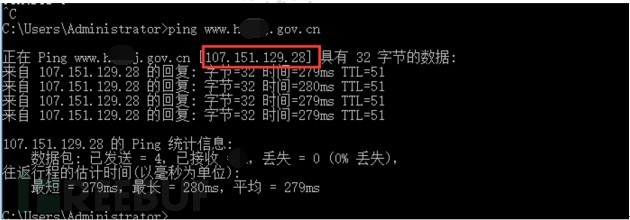
图-政府网站被解析到恶意IP
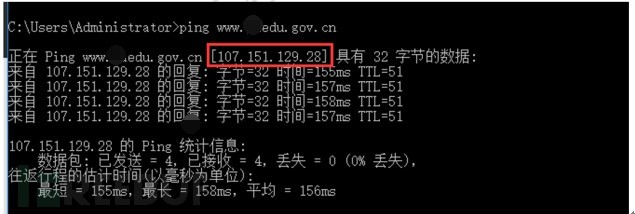
图-高校网站被解析到恶意IP
图-解析IP地理位置
对107.151.129.28这个IP进行关联分析,目前已发现大量政府、高校、财经类网站被恶意解析到107.151.129.28这个IP上,详细域名大家自行搜索,不方便贴图。这些政府、高校、财经类网站DNS都被恶意修改到该IP上。
1.3 深入分析
既然此次事件是因为域名被恶意解析导致的,DNS又是现代网络的基础,如果基础网络出现问题,那么上层应用根本没有安全可言。因此我们可以对重要的网站进行DNS层面深度分析,通过DNS层面挖掘其安全问题。具体思路如下:
1. 收集域名信息(本次收集以政府和高校为主)
2. 对域名进行批量查询其 A记录、CNAME与泛解析
3. 分析域名是否采用了CDN、云防护之类设备
4. 数据分析
a) IP下同一域名信息:这个实现原理为分析域名DNS解析后是否对应同一IP。一方面可以用来分析同一IP下有哪些网站;另一方面若该IP为恶意IP,通过IP上对应的域名了解哪些网站的域名被恶意解析。
b) 哪些域名使用CDN、云防护之类产品或服务
c) IP的地理位置分析。政府类域名解析后一般其IP地理位置都为其域名所有者所属地市,若发现存在非当地城市,进行提取并分析;即使采用了CDN、云防护之类的产品,DNS解析后的IP地理位置应该也在国内,一般不会解析到国外的IP。若解析到国外,提取并分析。
d) 结合IP威胁情报分析:把解析后的IP地址全部查询一下其IP威胁情况,对恶意的IP上的域名进行提取并统计同一IP下的域名。
e) 入侵目的分析:基于目的驱动的原则,黑客既然入侵,肯定会有所目的与动作。因此对恶意IP及同一IP下的域名提取并分析,以分析黑客入侵目的。
f) 若恶意的IP上有黑客注册的网站,可提取网站备案的邮箱、QQ及域名相关的日志,尝试关联黑客身份信息。
2. 数据处理
2.1 获取域名数据
域名收集这块大家自行想办法,这个是最基本的前提。数据量越大,后面的分析越有意义。可以以行业(政府、高校、企业等)进行分类获取,建议按照行业分类。下面是此次分析的域名数据,主要以政府类网站为主。粗略统计本次分析所用域名数据共4898条:其中政府类网站3249个、高校网站104个、其他网站1545个。
2.2 DNS解析
解析出上述域名的A记录、CNAME以及泛解析结果。
泛解析是DNS需要重点分析的点,曾经多次遇到黑客修改DNS泛解析进行SEO推广的案例。测试泛解析很容易,在正常域名前加下随机的子域名,为了随机,可以加个MD5值,d663778705dbadf091a5e7694d584908这种。本次测试时使用sanshibuying.+host这种形式。相关实现的代码如下所示:
#coding:utf-8
from dns.resolver import *
import re
hostlist = open('./host.txt','r')
for host in hostlist:
try:
host = host.split('\n')[0]
if 'gov.cn' in host:
attr = 'gov'
elif 'edu' in host:
attr = 'edu'
else:
attr = 'oth'
#查询A记录、CNAME记录
#ID 0:CNAME 1:A记录 2:泛解析
a = query(host)
for dns in a.response.answer:
if 'CNAME' in str(dns):
id = 0
elif 'A' in str(dns):
id = 1
for dns in dns.items:
f = open('./DNS解析结果.txt','a')
print(host.ljust(40),(str(dns)).ljust(40),attr.ljust(5),id,file=f)
#泛解析查询
host = 'sanshibuying.' + host
b = query(host)
for dns in b.response.answer:
for dns in dns.items:
pass
id = 2
f = open('./DNS解析结果.txt','a')
print(host.ljust(40),(str(dns)).ljust(40),attr.ljust(5),id,file=f)
except Exception as e:
pass
代码-DNS解析
解析后提取的数据如下所示:
图-DNS解析数据
2.3 查询地理位置
解析IP地址对应的地理位置,为后期数据分析提供基础数据。这里实现的方法为调用开源的IP地理位置库GeoLiteCity。具体实现代码如下:
#coding:utf-8
import pygeoip
gi = pygeoip.GeoIP('GeoLiteCity.dat')
def printRecord(ip):
try:
rec = gi.record_by_name(ip)
city = rec['city']
region = rec['region_code']
country = rec['country_name']
long = rec['longitude']
lat = rec['latitude']
except Exception as e:
pass
try:
f = open('IP地理位置.txt','a')
print(ip.ljust(20),city.ljust(20),country.ljust(10),file=f)
except Exception as e:
pass
if __name__ == '__main__':
IPFile = open('ip.txt')
for ip in IPFile.readlines():
ip = ip.strip('\n')
printRecord(ip)
代码-查询IP地理位置
解析后相应的数据及格式如下所示:
图-IP地理位置信息
2.4 数据入库
将解析后的数据(DNS相关数据及IP地理位置数据)全部存入数据库,另外为了方便了解网站的名称,同时将网站的title也一并爬取下来了,这里面爬取的时候使用了一个小技巧:
"x-forwarded-for":"123.125.66.120",
"referer":"https://www.baidu.com",
"user-agent":"Baiduspider/2.0+http://www.baidu.com/search/spider.html”
这样设置可以发现可能被黑客入侵并做SEO推广的相关信息。
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"x-forwarded-for":"123.125.66.120",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"https://www.baidu.com",
"connection":"keep-alive",
"user-agent":"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
}
def main():
urllist = open('fanjiexiurl.txt','r')
for url in urllist:
try:
url = url.split('\n')[0]
url = 'http://' + url
html = get(url,timeout=3,headers=headers)
html.encoding = html.apparent_encoding
name = re.search("<title>.*</title>", html.text)
name = name.group()
name = (name.split('<title>')[1]).split('</title>')[0]
f = open("./泛解析网站名称.txt", 'a')
print (url.ljust(40),name.ljust(30),file=f)
except Exception as e:
print(e)
pass
if __name__ == '__main__':
main()代码-查询域名的title
将DNS数据、Title数据及IP地理位置数据整合后存入数据库,相关数据如下:
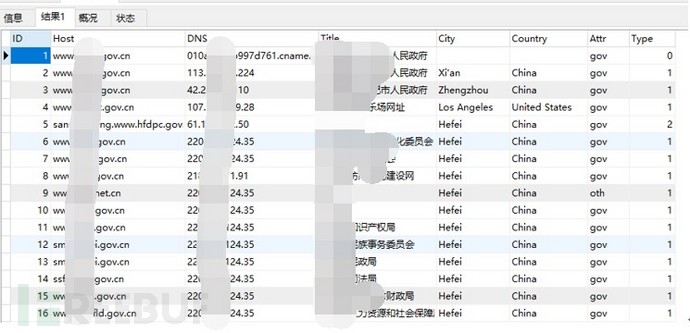
图-DNS数据库
3. 数据分析
3.1 IP次数分析
对DNS解析后的IP进行排序,把相同的IP提取并统计其次数。相同的IP说明这些网站都是在同一个物理位置,一般情况下同一IP下出现较多域名的话这个IP基本上为IDC。统计后IP出现次数最多的前20个IP如下:
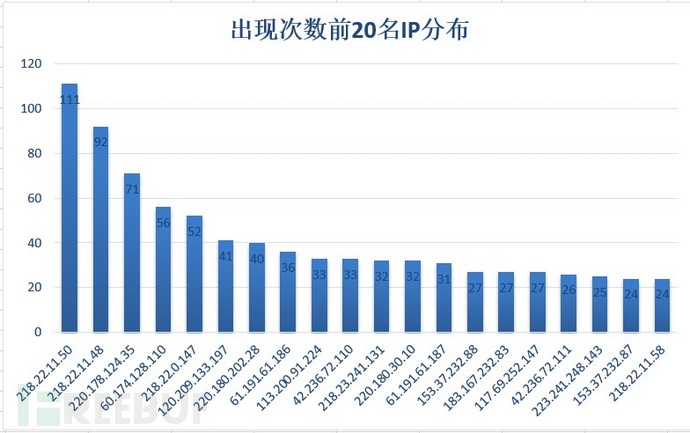
图-出现次数最多前20IP
这些IP基本上为IDC类的IP,选择其中一个IP统计其主机相关信息如下所示:
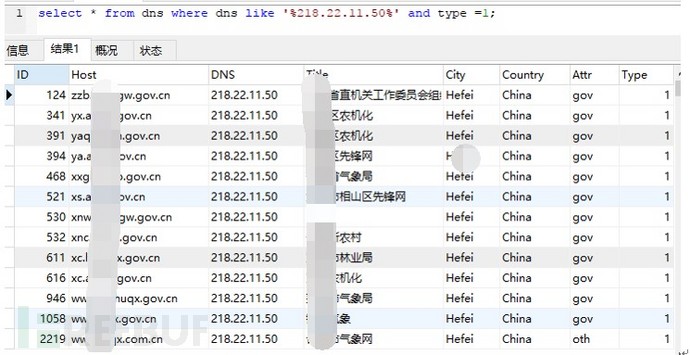
图-查询单一IP下的域名
相同IP下有多个网站的数据在实际工作中的意义为可以用来了解同一个IP下有哪些网站。如果同一IP下面的一个网站被黑客植入网马,其他网站同样存在安全威胁,在这种情况下可以进行预警通报。
另外,不同的政府单位都跑在一个IP上,这也间接说明这些IP为类似IDC的IP。因此,可以通过IP上网站数量来分析IP所属的行业(IDC这种)。
3.2 云防护、CDN分析
分析一下哪些网站使用了云防护、CDN之类的云产品。统计如下:
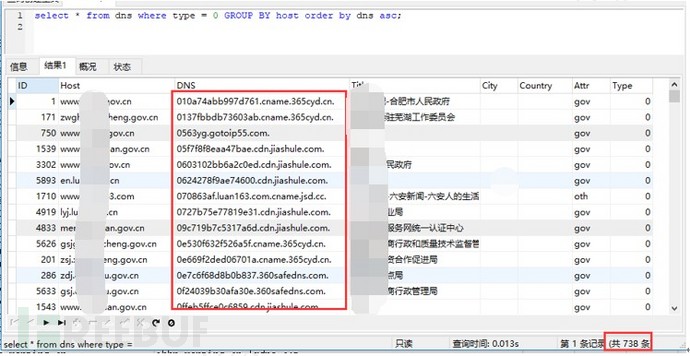
图-CDN、云防护情况
可以看出一共有738个网站具有CNAME属性,其中部分网站开启了CDN、云防护之类的云服务,需要从中提取出哪些网站开启了云防护、CDN以及使用哪些厂商的云服务。方法为分析其CNAME中是否有相关厂商的域名信息,一般情况下,CDN、云防护厂商其CNAME命名规则为XXXX.厂商域名,如:010a74abb997d761.cname.365cyd.cn.这种,提取其主域名365cyd.cn,可以看到其为知道创宇的创宇盾。
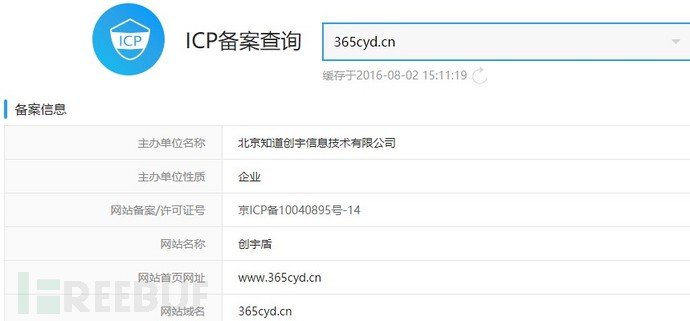
图-查询ICP备案信息
根据此种方法,从CNAME中提取使用CDN、云防护的代码如下:
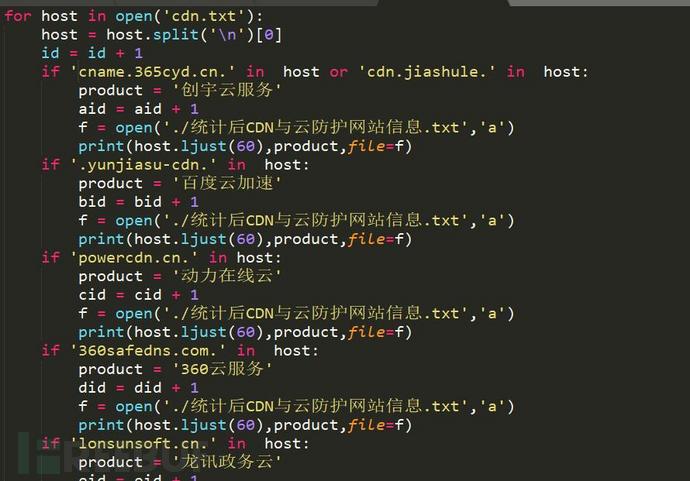
最终统计使用了CDN、云防护的网站数量、网站名如下:
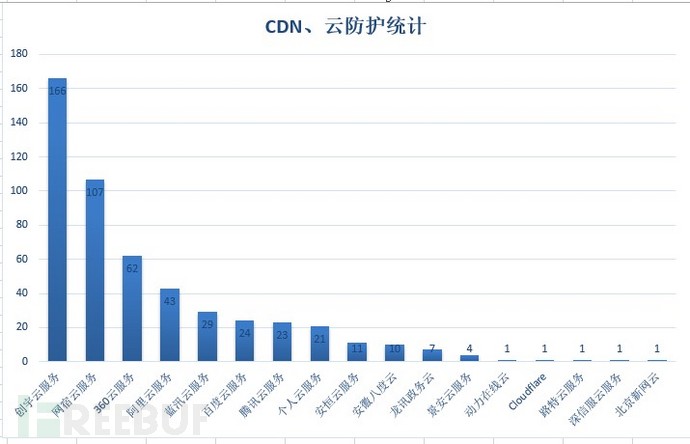
图-云防护、CDN厂商占有情况
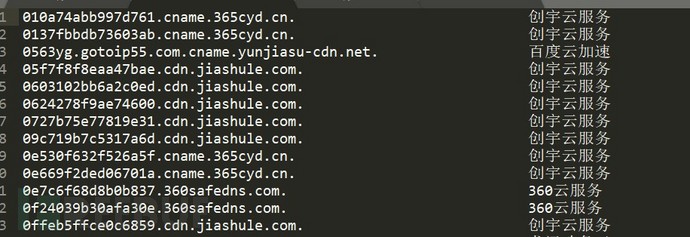
图-云防护、CDN厂商占有情况
最终,存入数据库,最终库表结构及相关内容如下所示:
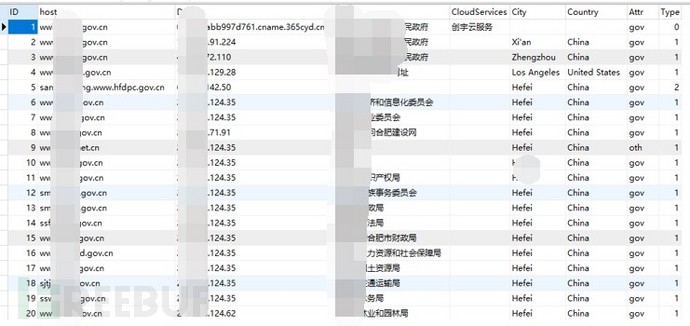
图-DNS库
CDN与云防护在DNS这块及实际工作中的作用为:
1. 分析用户是否使用CDN、云防护
2. 相关CDN、云防护厂商的占用率及用户分布
3. 了解CDN、云防护厂商的IP地理位置分布
4. 为DNS恶意解析判断提供基础数据
3.3 泛解析分析
泛解析指的是在域名解析时设置一下默认解析的配置,当前面所有的解析都解析不成功后,默认后返回一个解析地址。
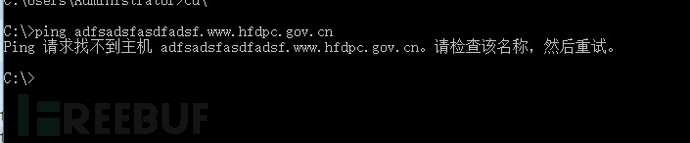
图-没有开启泛解析
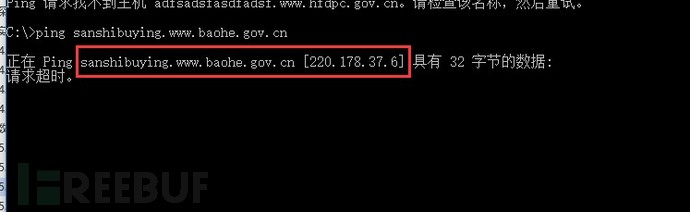
图-开启泛解析
根据相关数据分析,分析出148个网站开启了泛解析,相关数据如下:
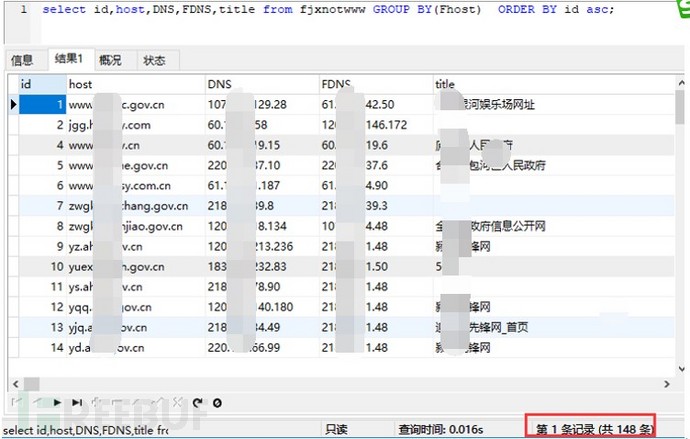
图-开启泛解析网站
在开启泛解析的情况下,正常解析和泛解析之后的IP地址应该是一致或者在相同网段的,如果开启泛解析后的地址与正常解析的地址相差较大,则DNS这块可能被恶意修改,需要进行重点分析。
通过分析开启泛解析且其解析后与正常解析不一致的情况,统计出如下所示:
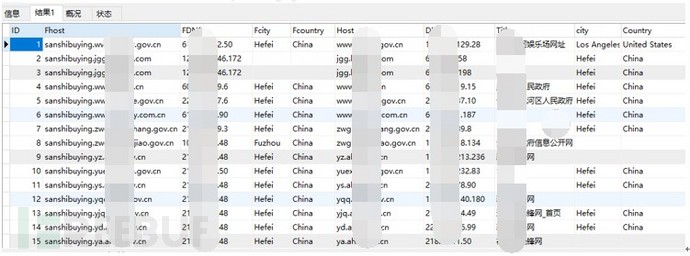
图-开启泛解析且解析后与正常解析不一致
虽然很多开了泛解析,但是其泛解析后的地理位置与主站地理位置一样,因此优化了一下。对其泛解析后地理位置与主站地理位置不一致的进行分析,统计如下:
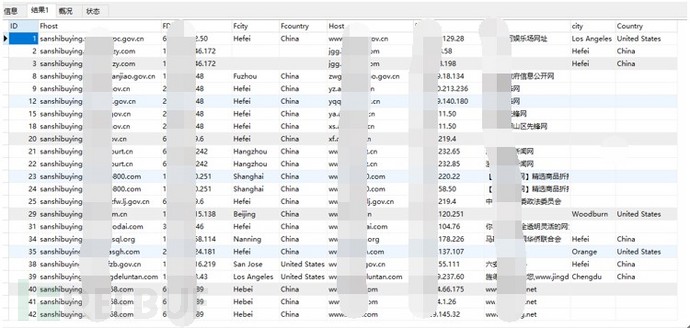
图-泛解析后地理位置与主站地理位置不一致
过滤出正常解析或泛解析地址为非国内的,如下所示:
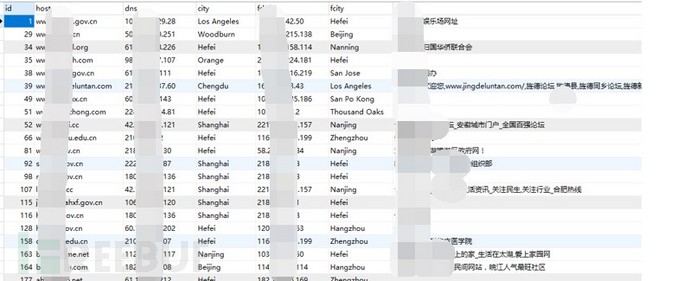
图-解析后地理位置非国内
上面这些网站泛解析后其地址都解析到国外,都是高度可疑的。需要提取出来进行深度分析。
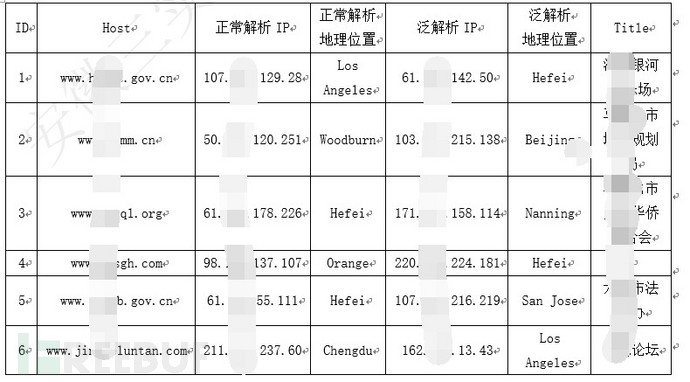
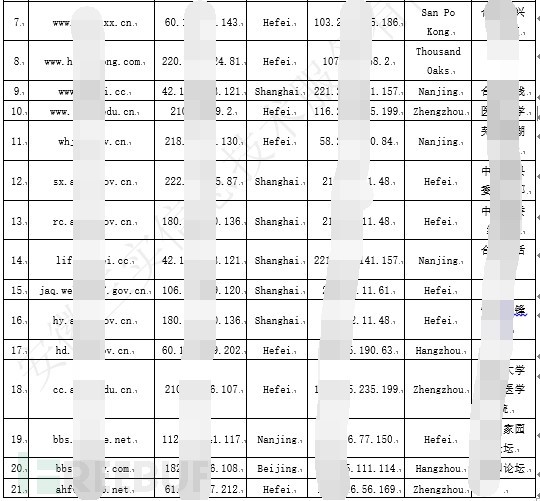
图-解析后其IP为国外
3.4 IP地理位置分析
上面已经分析了在开启泛解析的情况下,泛解析与正常解析后地址非国内的相关域名,另外还需要分析正常解析情况下解析后的IP地址位置非国内的。分析正常解析后IP位置的原因是如果主站都被恶意解析了并且没有开启泛解析的情况下上面是分析不到的,这两个数据最后需要进行去重。
从数据库中提取相关数据,这里面仅提取政府网站IP地理位置非国内的,提取后相关数据如下:
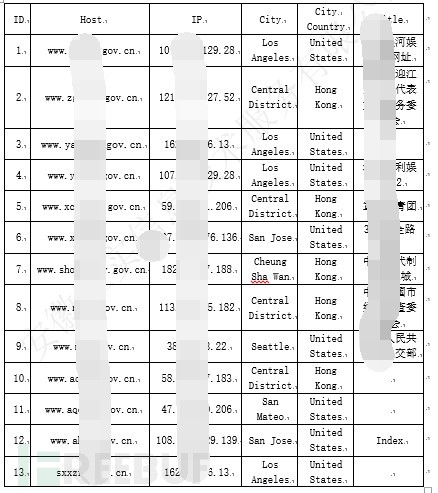
图-政府主站解析后IP地理位置非国内
3.5 网站Title分析
通过上面的网站Title已经看出很多网站存在博彩类信息,需要把相关含有博彩类信息的网站Title,IP地址、IP地理位置全部提取出来。
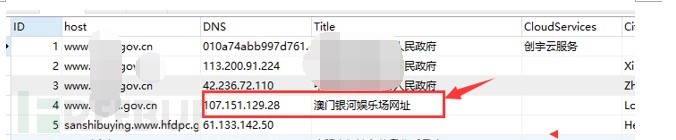
图-博彩类网站
提取后的Title关键词数据如下:
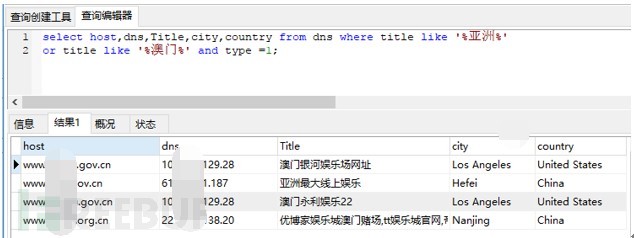
图-博彩类网站
根据上述提取出IP,根据IP统计相关网站,这里面就是前面介绍的统计同一个IP下面的网站功能:
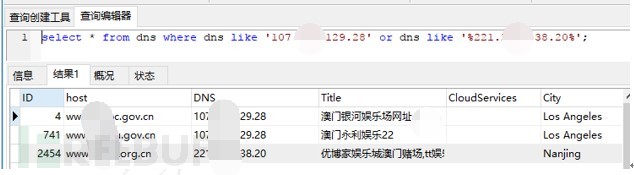
图-博彩类网站
由于本次使用的网站数量相对较少,相关的数据也比较少。因此可以使用云悉资产的数据。统计后相关数据如下:
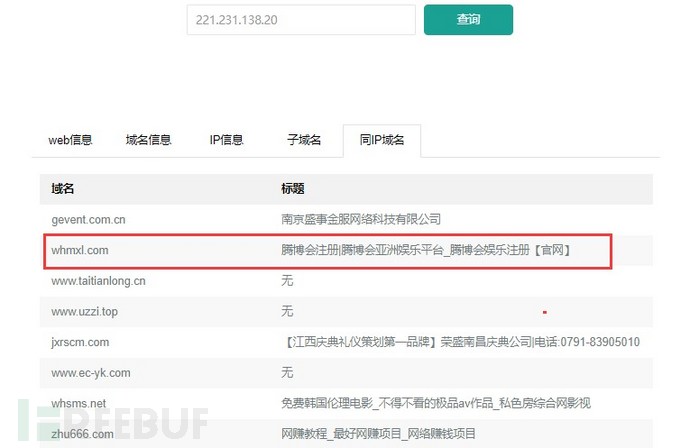
图-同一IP下的博彩网站
后期可以分析黑客是如何入侵该网站的,如果是网站被入侵的话,那么在同一台服务器下的网站都会存在安全风险。在实战过程中可以提取出相关网站进行针对性预警通报。
3.6 安全分析
3.6.1 DNS解析安全分析
前面已经统计出相关的一些信息,如title中为博彩类网站、解析后IP为国外IP。其都是零散的,在这里作个统一的汇总分析,并统计出其中可能存在的安全问题:
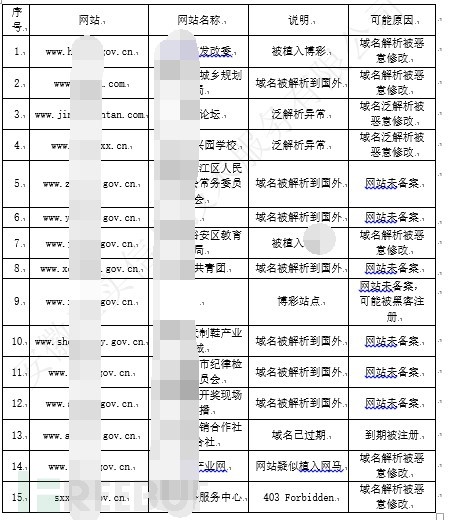
图-DNS解析后IP非国内安全情况
3.6.2 同一IP安全分析
通过DNS与泛解析这一块已经发现很多被解析到恶意的IP,这些IP一般都是相关黑客的IP。黑客一般会入侵并篡改的DNS解析到同一个IP,这种为我们分析哪些网站被入侵也提供了一个很好的思路。通过IP反查该IP上的所有域名,收集所有域名然后查找域名的备案信息。
在针对政府网站分析时,我们可以提取出IP上所有的政府网站,在黑客IP上跑的所有政府网站基本上都是被黑客恶意解析的。这样为我们分析哪些网站被入侵也提供了很好的思路。
在针对107.151.129.28这个黑客IP进行分析,统计出下面网站被解析到这个IP。基本上断定这些域名的解析被恶意修改,这样后续应急也比较简单,通过其域名管理系统后台取日志进行分析。
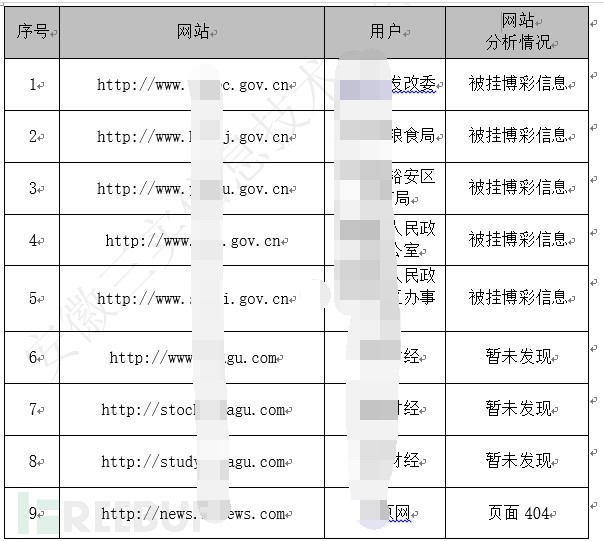
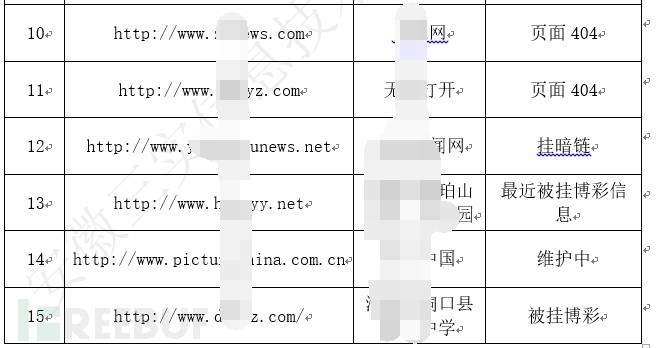
图-107.151.129.28下被恶意解析的网站
3.7 后续分析思路
前面分析的IP是否正常单纯是根据解析后的IP所在地以及网站title,这个分析逻辑相对简单。跳过DNS这个思路,站在IP情况的角度,可以解析后的IP结合威胁情报进行分析,若发现IP存在安全威胁,可以把该IP层上的所有域名统计出来,再进行安全分析。
另外,一般情况下,黑客都会在其服务器上开设网站,可以尝试通过网站的备案、网站上的邮箱、QQ、手机号等相关信息来关联黑客身份。前期使用这种方法定位过一个做博彩的灰产人员,且灰产人员通过入侵政府网站进行SEO推广。
4. 数据的价值
目前IT已进入DT时代,在DT为王的时候,数据的价值远远超过方法、理念甚至产品的价值。而DNS是DT中的基础网络数据,其价值至关重要。以后IT领域的竞争会越来越集中到数据领域的竞争。
这篇文章前后花了五六个晚上完成,希望给大家在分析基础数据时提供一些参考。DNS数据的价值远远超过目前个人所分析的,目前个人所分析的仅为DNS解析这块,另外DNS里面的DGA、非DNS通信数据等也有比较好的挖掘点,大家有好的想法与思路可以一起讨论。
*本文作者:feiniao,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者