


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一、背景
1. 验证补丁的困惑
众所周知,寻找并定位二进制代码之间存在(源)代码复用、存在的差异,其准确率及召回率是2个关键指标。无恒实验室在日常的研究工作中发现,面对ROM中数百程序和动态链接库,如果可以像分析源码一样分析二进制补丁,那么验证补丁的效率会大大提升。
基于此,无恒实验室对市面的工具进行调研。用radiff2做补丁扫描,召回率堪忧,扫描完之后仍然需要手动返工来消除误报,且其效率感人;再换用bindiff,召回率几乎99%,但当研发切换编译工具链或者修改编译优化等级,则准确率就会明显下降。
2. 对比主流工具
记XO为不同编译优化等级场景,XC1为同类编译器不同版本,XC2为不同类编译器,以TALOS所用数据集中的libssl与libz作为数据集[1],strip后则可测得

可以看到
- - radiff2表现很差
- - BinDiff表现优于radiff2,但在XC2下召回率显著下降
看来是不得不选择BinDiff了,那么问题来了,如何提升BinDiff的召回率呢?
我们首先需要了解不同类型的二进制相似度检测任务,以及代码克隆检测任务。
二、前置知识
1. 如何划分二进制相似度检测任务
根据TALOS的综述,可以将二进制相似度检测任务划分为6类[1](下表将编译器与编译器版本合并为一栏)——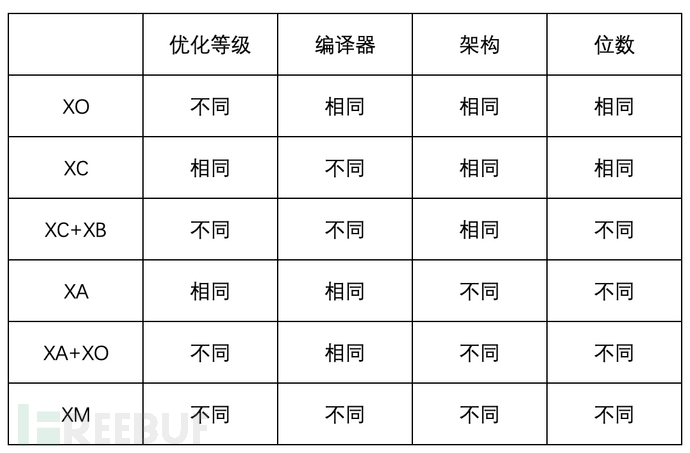
2. 如何描述代码克隆类型
我们把代码相似度分为下面4种[2]
目前,Type-1/2/3已经有成熟解决方案比如SourcererCC[3]等,而Type-4也有不少工作,比如Technion的code2vec[4]。此外,近年来随着大模型发展,UniXcoder[5]、CodeT5+[6]等代码大模型在Type-4的代码克隆检测上也能通过微调取得不错的表现。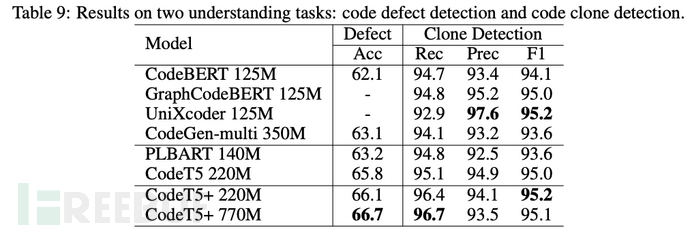
三、函数相似度与匹配
1. 初代废弃方案
2. structure2vec
借TALOS综述所言,我们选择用structure2vec[8]来生成ACFG图嵌入。在GNN下,CFG + IR + Int + Strings各类任务中最佳,其次是CFG + BoW IR/opc[1]。 但structure2vec的节点属性是定长向量,而基本块中的Int、String之类的constants序列是不定长的,因此我们对Gemini的ACFG进行拓展,使用CFG + BoW Hexrays IR + len(constants)作为基本块节点向量来构成ACFG。
但structure2vec的节点属性是定长向量,而基本块中的Int、String之类的constants序列是不定长的,因此我们对Gemini的ACFG进行拓展,使用CFG + BoW Hexrays IR + len(constants)作为基本块节点向量来构成ACFG。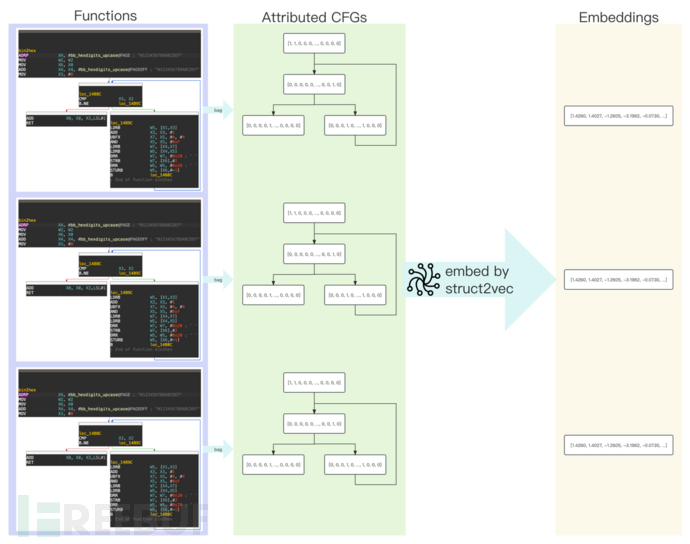
 3. 业余炼丹士
3. 业余炼丹士
structure2vec embedding + function properties就够了吗?XO与XC会导致控制流的变化,ACFG也会随之变化,这会降低structure2vec的表现。但是,函数语义是不变的,因此我们可以站在两位巨人肩膀上——代码大模型与反编译伪代码,通过代码大模型对C风格伪代码做Type-4的代码克隆检测。这里我们选择UniXcoder[5]与CodeT5+[6]的encoder来生成embedding,并用POJ104作为数据集微调——
- microsoft/unixcoder-base-nine,125M参数,微调代码:https://github.com/microsoft/CodeBERT/blob/master/UniXcoder/downstream-tasks/clone-detection/POJ-104/run.py
- Salesforce/codet5p-110m-embedding,110M参数,微调代码:https://github.com/Cossack9989/CodeT5/blob/main/CodeT5%2B/tune_codet5p_clone_detection.py
在8张T4跑完两轮微调任务后,模型的代码克隆检测准确率如下

4. 匹配流程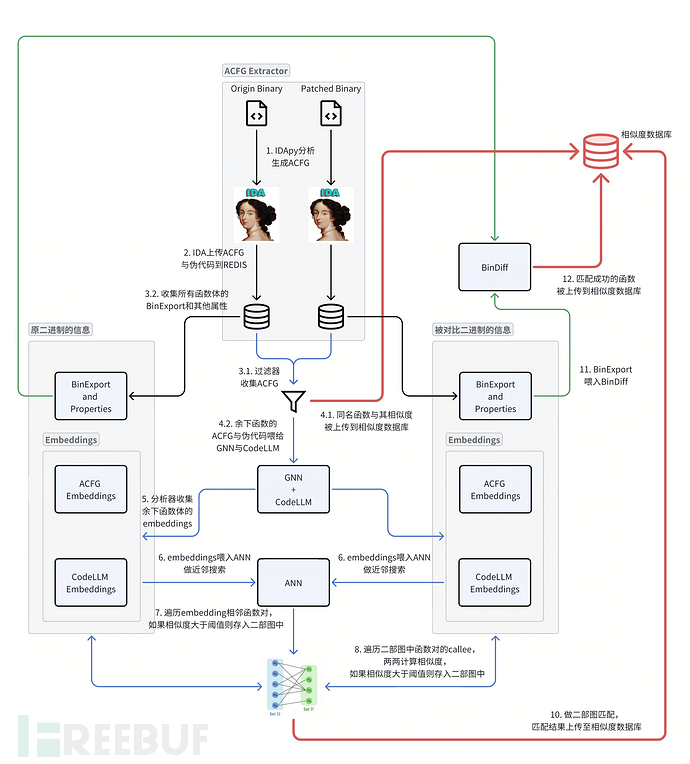
四、metrics
1. 实验设置
我们选择TALOS的DataSet-1的strip后的libz.so.1.2.11和libssl.so.3作为数据集[1],架构为ARM64,实验环境是8c32g MBP(M1 Pro),记我们的方法为BinDiff+AI(合并BinDiff与GNN+LLM的对比结果)
链接为 https://drive.google.com/drive/folders/1g9P0KKSwqdFt0K6dDeKKhWfmhqiQHQqU?usp=sharing
我们关注如下几个任务:
- XO
- XC1/XC2
- XO+XC1/XO+XC2
因为目标是自动化补丁检测,所以我们无须关注XA、XB相关的任务
2. 实验结果

从F1看,我们发现,BinDiff加上embedding后,XO与XC1基本保持一致,XO+XC1得到了2%左右的提升,XC2与XO+XC2都得到了5%左右提升
五、一些思考
1. 调用链特征
二部图匹配忽略了函数之间的调用关系,匹配流程第8步callee的匹配也仅仅只是覆盖了相邻调用关系,这个特征的缺失或许很重要。
2. 代码大模型
本次实验只使用了UniXcoder[5]和CodeT5+[6]的encoder来生成伪代码语义embedding,但在Type-4的代码克隆检测上已经不再是SOTA,可以考虑换别的代码大模型。
六、关于无恒实验室
无恒实验室是由字节跳动资深安全研究人员组成的专业攻防研究实验室,致力于为字节跳动旗下产品与业务保驾护航。通过漏洞挖掘、实战演练、黑产打击、应急响应等手段,不断提升公司基础安全、业务安全水位,极力降低安全事件对业务和公司的影响程度。无恒实验室希望持续与业界共享研究成果,协助企业避免遭受安全风险,亦望能与业内同行共同合作,为网络安全行业的发展做出贡献。
参考文献
>[1] Andrea Marcelli, Mariano Graziano, Xabier Ugarte-Pedrero, Yanick Fratantonio, Mohamad Mansouri, and Davide Balzarotti. How machine learning is solving the binary function similarity problem. In 31st USENIX Security Symposium (USENIX Security 22), pages 2099–2116, Boston, MA, August 2022. USENIX Association.
[2] Chanchal Kumar Roy and James R. Cordy. A survey on software clone detection research. SCHOOL OF COMPUTING TR 2007-541, QUEEN’S UNIVERSITY, 115, 2007.
[3] Hitesh Sajnani, Vaibhav Saini, Jeffrey Svajlenko, Chanchal K. Roy, and Cristina V. Lopes. Sourcerercc: scaling code clone detection to big-code. In Proceedings of the 38th International Conference on Software Engineering, ICSE ’16. ACM, May 2016.
[4] Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. code2vec: Learning distributed representations of code, 2018.
[5] Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. Unixcoder: Unified cross-modal pre-training for code representation. arXiv preprint arXiv:2203.03850, 2022.
[6] Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi D.Q. Bui, Junnan Li, and Steven C. H. Hoi. Codet5+: Open code large language models for code understanding and generation. arXiv preprint, 2023.
[7] Qian Feng, Rundong Zhou, Chengcheng Xu, Yao Cheng, Brian Testa, and Heng Yin. Scalable graph-based bug search for firmware images. In CCS 2016 - Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016.
[8] Hanjun Dai, Bo Dai, and Le Song. Discriminative embeddings of latent variable models for structured data, 2020.
- 0 文章数
- 0 关注者