


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
1、ZGC简介
1.1 介绍
ZGC 是一款低延迟的垃圾回收器,是 Java 垃圾收集技术的最前沿,理解了 ZGC,那么便可以说理解了 java 最前沿的垃圾收集技术。
从 JDK11 中作为试验特性推出以来,ZGC 一直在不停地发展中。
从 JDK14 开始,ZGC 开始支持 Windows。
在 JDK15 中,ZGC 不再是实验功能,可以正式投入生产使用了。
在最新的 JDK 开源库中,已经出现了分代收集的 ZGC 代码,预计不久的将来会正式发布,到时相信 ZGC 各项表现将会更加优秀。
图1 分代收集的ZGC
如上图,JDK21 中已经有了分代 ZGC 的 Feature。
1.2 ZGC 特征
1.低延迟
2.大容量堆
3.染色指针
4.读屏障
1.3 垃圾收集阶段
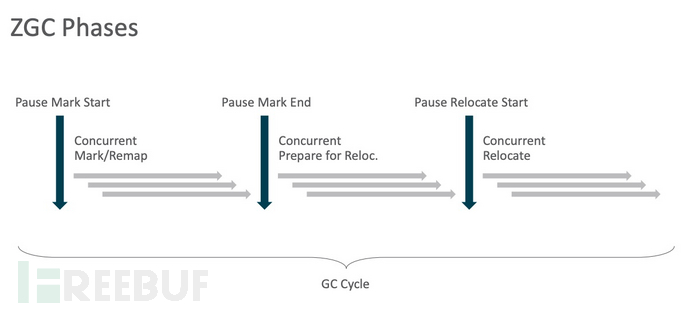
图2 ZGC 运作过程
如上图,主要有以下几个阶段,初始标记、并发标记/并发重映射、并发预备重分配、初始重分配、并发重分配,本次主要分析的就是”并发标记/并发重映射“部分源代码。
1.4 带着问题去读源码
1.ZGC 是如何在指针上标记的
2.ZGC 三色标记的过程
3.ZGC 只用了读屏障是如何防止漏标的
4.ZGC 标记过程中的指针自愈过程
5.ZGC 并发标记中的并发重映射过程
2、源码
2.1 入口
整个 ZGC 的源码入口是 ZDriver::gc 函数
void ZDriver::gc(const ZDriverRequest& request) {
ZDriverGCScope scope(request);
// Phase 1: Pause Mark Start
pause_mark_start();
// Phase 2: Concurrent Mark
concurrent(mark);
// Phase 3: Pause Mark End
while (!pause_mark_end()) {
// Phase 3.5: Concurrent Mark Continue
concurrent(mark_continue);
}
// Phase 4: Concurrent Mark Free
concurrent(mark_free);
// Phase 5: Concurrent Process Non-Strong References
concurrent(process_non_strong_references);
// Phase 6: Concurrent Reset Relocation Set
concurrent(reset_relocation_set);
// Phase 7: Pause Verify
pause_verify();
// Phase 8: Concurrent Select Relocation Set
concurrent(select_relocation_set);
// Phase 9: Pause Relocate Start
pause_relocate_start();
// Phase 10: Concurrent Relocate
concurrent(relocate);
}其中,concurrent() 是一个宏定义
// Macro to execute a termination check after a concurrent phase. Note
// that it's important that the termination check comes after the call
// to the function f, since we can't abort between pause_relocate_start()
// and concurrent_relocate(). We need to let concurrent_relocate() call
// abort_page() on the remaining entries in the relocation set.
#define concurrent(f) \
do { \
concurrent_##f(); \
if (should_terminate()) { \
return; \
} \
} while (false)于是我们可以知道并发标记的函数是 concurrent_mark
void ZDriver::concurrent_mark() {
ZStatTimer timer(ZPhaseConcurrentMark);
ZBreakpoint::at_after_marking_started();
//开始对整个堆进行标记
ZHeap::heap()->mark(true /* initial */);
ZBreakpoint::at_before_marking_completed();
}2.2 并发标记过程
2.2.1 并发标记
接下来看 ZHeap::heap()->mark
void ZHeap::mark(bool initial) {
_mark.mark(initial);
}再往下
void ZMark::mark(bool initial) {
if (initial) {
ZMarkRootsTask task(this);
_workers->run(&task);
}
ZMarkTask task(this);
_workers->run(&task);
}这里用了一个任务框架,执行任务逻辑在 ZMarkTask 里
class ZMarkTask : public ZTask {
private:
ZMark* const _mark;
const uint64_t _timeout_in_micros;
public:
ZMarkTask(ZMark* mark, uint64_t timeout_in_micros = 0) :
ZTask("ZMarkTask"),
_mark(mark),
_timeout_in_micros(timeout_in_micros) {
_mark->prepare_work();
}
~ZMarkTask() {
_mark->finish_work();
}
virtual void work() {
_mark->work(_timeout_in_micros);
}
};这里具体执行的函数是 work,往下看 _mark->work
void ZMark::work(uint64_t timeout_in_micros) {
ZMarkCache cache(_stripes.nstripes());
ZMarkStripe* const stripe = _stripes.stripe_for_worker(_nworkers, ZThread::worker_id());
ZMarkThreadLocalStacks* const stacks = ZThreadLocalData::stacks(Thread::current());
if (timeout_in_micros == 0) {
work_without_timeout(&cache, stripe, stacks);
} else {
work_with_timeout(&cache, stripe, stacks, timeout_in_micros);
}
// Flush and publish stacks
stacks->flush(&_allocator, &_stripes);
// Free remaining stacks
stacks->free(&_allocator);
}这里的 stripe 就是标记条带,stacks 是一个线程本地栈。
往下看 work_with_timeout 方法
void ZMark::work_with_timeout(ZMarkCache* cache, ZMarkStripe* stripe, ZMarkThreadLocalStacks* stacks, uint64_t timeout_in_micros) {
ZStatTimer timer(ZSubPhaseMarkTryComplete);
ZMarkTimeout timeout(timeout_in_micros);
for (;;) {
if (!drain(stripe, stacks, cache, &timeout)) {
// Timed out
break;
}
if (try_steal(stripe, stacks)) {
// Stole work
continue;
}
// Terminate
break;
}
}可以看到这里是一个循环,会一直从标记条带里取数据,直到取完了或时间到了。 这里就是 ZGC 三色标记的主循环了。 接下来看 drain 函数,drain 就是使排空的意思,这里就是从栈中取出指针进行标记,直到栈为空。
template <typename T>
bool ZMark::drain(ZMarkStripe* stripe, ZMarkThreadLocalStacks* stacks, ZMarkCache* cache, T* timeout) {
ZMarkStackEntry entry;
// Drain stripe stacks
while (stacks->pop(&_allocator, &_stripes, stripe, entry)) {
//标记和跟随
mark_and_follow(cache, entry);
// Check timeout
if (timeout->has_expired()) {
// Timeout
return false;
}
}
// Success
return !timeout->has_expired();
}可以看到这里一直在从栈里取数据,然后标记和递归标记,直到栈排空。
既然有从栈里取数据的地方,那肯定有往栈里放数据的地方,我们先把这个点记下来,叫“记录点1”。
接着往下看 mark_and_follow 函数
void ZMark::mark_and_follow(ZMarkCache* cache, ZMarkStackEntry entry) {
// Decode flags
const bool finalizable = entry.finalizable();
const bool partial_array = entry.partial_array();
if (partial_array) {
follow_partial_array(entry, finalizable);
return;
}
// Decode object address and additional flags
const uintptr_t addr = entry.object_address();
const bool mark = entry.mark();
bool inc_live = entry.inc_live();
const bool follow = entry.follow();
ZPage* const page = _page_table->get(addr);
assert(page->is_relocatable(), "Invalid page state");
// Mark
//标记对象
if (mark && !page->mark_object(addr, finalizable, inc_live)) {
// Already marked
return;
}
// Increment live
if (inc_live) {
// Update live objects/bytes for page. We use the aligned object
// size since that is the actual number of bytes used on the page
// and alignment paddings can never be reclaimed.
const size_t size = ZUtils::object_size(addr);
const size_t aligned_size = align_up(size, page->object_alignment());
cache->inc_live(page, aligned_size);
}
// Follow
if (follow) {
if (is_array(addr)) {
//递归处理数组
follow_array_object(objArrayOop(ZOop::from_address(addr)), finalizable);
} else {
//递归处理对象
follow_object(ZOop::from_address(addr), finalizable);
}
}
}这里有两个函数要看,我们先看 page->mark_object,再看 follow_object,至于follow_array_object,和 follow_object 类似,就不在详细介绍了。
page->mark_object 源码如下
inline bool ZPage::mark_object(uintptr_t addr, bool finalizable, bool& inc_live) {
assert(ZAddress::is_marked(addr), "Invalid address");
assert(is_relocatable(), "Invalid page state");
assert(is_in(addr), "Invalid address");
// Set mark bit
const size_t index = ((ZAddress::offset(addr) - start()) >> object_alignment_shift()) * 2;
return _livemap.set(index, finalizable, inc_live);
}可以看到这里用了一个 map,来存储了所有对象地址的 finalizable 和 inc_live(新增存活)信息。
const size_t index = ((ZAddress::offset(addr) - start()) >> object_alignment_shift()) * 2;
从这个代码看,livemap 的大小大概是整个堆的对象对齐大小分之一,然后再乘以2。 这个 map 存的信息非常重要,ZGC中判断一个地址是否被标记过,一个对象是否存活都是通过这个 map 里的信息来判断的。
再回到上一步,继续看 follow_object 函数
void ZMark::follow_object(oop obj, bool finalizable) {
if (finalizable) {
ZMarkBarrierOopClosure<true /* finalizable */> cl;
obj->oop_iterate(&cl);
} else {
ZMarkBarrierOopClosure<false /* finalizable */> cl;
obj->oop_iterate(&cl);
}
}这里根据 finalizable 分了两个分支,oop_iterate 看名字我们也能猜到这是做什么的,就是对对象里的指针进行迭代,但毕竟是猜测,具体还要看代码验证。
ZMarkBarrierOopClosure 这个看名字就是读屏障了,我们已经来到开头问题 3 的大门前了,只差临门一脚。 踹进读屏障的大门前,我们还得搬开挡在门口的一个大石头 oop_iterate 方法是怎么和 ZMarkBarrierOopClosure 联系上的。
2.2.2 对象迭代遍历
这一节将看 oop_iterate 内部逻辑,这个属于分支流程,暂不想了解的可以先跳过,直接看下一节 2.2.3 读屏障。
警告:抓紧扶手,下面车速开始加快了!
先把 cl 类型 ZMarkBarrierOopClosure 记录下来,我们记为 “记录点2”。
进入 oop_iterate 函数
template <typename OopClosureType>
void oopDesc::oop_iterate(OopClosureType* cl) {
OopIteratorClosureDispatch::oop_oop_iterate(cl, this, klass());
}再往下
template <typename OopClosureType>
void OopIteratorClosureDispatch::oop_oop_iterate(OopClosureType* cl, oop obj, Klass* klass, MemRegion mr) {
OopOopIterateBoundedDispatch<OopClosureType>::function(klass)(cl, obj, klass, mr);
}再往下
static FunctionType function(Klass* klass) {
return _table._function[klass->id()];
}function 方法在一个类中,_table 就是这个类的对象实例,_function 是个数组,我们看_function 怎么初始化值的。
public:
FunctionType _function[KLASS_ID_COUNT];
Table(){
set_init_function<InstanceKlass>();
set_init_function<InstanceRefKlass>();
set_init_function<InstanceMirrorKlass>();
set_init_function<InstanceClassLoaderKlass>();
set_init_function<ObjArrayKlass>();
set_init_function<TypeArrayKlass>();
}table 构造方法与 _function 定义
这里有多个 Klass 对象,我们只看第一个。我们把 InstanceKlass 暂记为“记录点3”,接着往下看 set_init_function。
template <typename KlassType>
void set_init_function() {
_function[KlassType::ID] = &init<KlassType>;
}往下看 init 函数
template <typename KlassType>
static void init(OopClosureType* cl, oop obj, Klass* k, MemRegion mr) {
OopOopIterateBoundedDispatch<OopClosureType>::_table.set_resolve_function_and_execute<KlassType>(cl, obj, k, mr);
}继续
template <typename KlassType>
void set_resolve_function_and_execute(OopClosureType* cl, oop obj, Klass* k, MemRegion mr) {
set_resolve_function<KlassType>();
_function[KlassType::ID](cl, obj, k, mr);
}继续跟 set_resolve_function
template <typename KlassType>
void set_resolve_function() {
if (UseCompressedOops) {
_function[KlassType::ID] = &oop_oop_iterate_bounded<KlassType, narrowOop>;
} else {
_function[KlassType::ID] = &oop_oop_iterate_bounded<KlassType, oop>;
}
}可以看到这里有个 UseCompressedOops,难道 ZGC 支持压缩指针了?感兴趣的同学可以深入研究下。
往下看 oop_oop_iterate_bounded
template <typename KlassType, typename T>
static void oop_oop_iterate_bounded(OopClosureType* cl, oop obj, Klass* k, MemRegion mr) {
((KlassType*)k)->KlassType::template oop_oop_iterate_bounded<T>(obj, cl, mr);
}这里可以看到调用了 KlassType 的 oop_oop_iterate_bounded 函数,KlassType 又是啥,这是一个泛型,其真实类型在这里其中之一就是记录点3的 InstanceKlass。
在 JVM 中一个普通的 Java 类是以一个 InstanceKlass 类型的 Klass 模型存在的。
以下就不属于 ZGC 的源码了,当然,仍然是 jvm 源码。
进入 InstanceKlass 的 oop_oop_iterate_bounded 函数
template <typename T, class OopClosureType>
ALWAYSINLINE void InstanceKlass::oop_oop_iterate_bounded(oop obj, OopClosureType* closure, MemRegion mr) {
if (Devirtualizer::do_metadata(closure)) {
if (mr.contains(obj)) {
Devirtualizer::do_klass(closure, this);
}
}
oop_oop_iterate_oop_maps_bounded<T>(obj, closure, mr);
}往下
template <typename T, class OopClosureType>
ALWAYSINLINE void InstanceKlass::oop_oop_iterate_oop_maps_bounded(oop obj, OopClosureType* closure, MemRegion mr) {
//非静态成员变量块起始位置
OopMapBlock* map = start_of_nonstatic_oop_maps();
//非静态成员变量块结束位置
OopMapBlock* const end_map = map + nonstatic_oop_map_count();
//对非静态成员变量块进行遍历
for (;map < end_map; ++map) {
oop_oop_iterate_oop_map_bounded<T>(map, obj, closure, mr);
}
}可以看到这里对一个对象的非静态成员变量块进行了迭代遍历。 继续往下
template <typename T, class OopClosureType>
ALWAYSINLINE void InstanceKlass::oop_oop_iterate_oop_map_bounded(OopMapBlock* map, oop obj, OopClosureType* closure, MemRegion mr) {
T* p = (T*)obj->obj_field_addr<T>(map->offset());
T* end = p + map->count();
T* const l = (T*)mr.start();
T* const h = (T*)mr.end();
assert(mask_bits((intptr_t)l, sizeof(T)-1) == 0 &&
mask_bits((intptr_t)h, sizeof(T)-1) == 0,
"bounded region must be properly aligned");
if (p < l) {
p = l;
}
if (end > h) {
end = h;
}
for (;p < end; ++p) {
Devirtualizer::do_oop(closure, p);
}
}这里继续对一个对象的非静态成员变量进行遍历。 继续看 Devirtualizer::do_oop
template <typename OopClosureType, typename T>
inline void Devirtualizer::do_oop(OopClosureType* closure, T* p) {
call_do_oop<T>(&OopClosureType::do_oop, &OopClosure::do_oop, closure, p);
}继续
template <typename T, typename Receiver, typename Base, typename OopClosureType>
static typename EnableIf<IsSame<Receiver, Base>::value, void>::type
call_do_oop(void (Receiver::*)(T*), void (Base::*)(T*), OopClosureType* closure, T* p) {
closure->do_oop(p);
}继续,但继续不动了,OopClosureType 是个模板类型,其真实类型是什么呢?一层层往上回溯,发现它就是记录点2的 ZMarkBarrierOopClosure 读屏障,这就又回到了 ZGC 主流程里了。
2.2.3 读屏障
进入 ZMarkBarrierOopClosure,由上一节可知,这个函数的入参 p 就是要标记对象的非静态成员变量的指针。
template <bool finalizable>
class ZMarkBarrierOopClosure : public ClaimMetadataVisitingOopIterateClosure {
public:
ZMarkBarrierOopClosure() :
ClaimMetadataVisitingOopIterateClosure(finalizable
? ClassLoaderData::_claim_finalizable
: ClassLoaderData::_claim_strong,
finalizable
? NULL
: ZHeap::heap()->reference_discoverer()) {}
virtual void do_oop(oop* p) {
ZBarrier::mark_barrier_on_oop_field(p, finalizable);
}
virtual void do_oop(narrowOop* p) {
ShouldNotReachHere();
}
};继续看 mark_barrier_on_oop_field
//
// Mark barrier
//
inline void ZBarrier::mark_barrier_on_oop_field(volatile oop* p, bool finalizable) {
const oop o = Atomic::load(p);
if (finalizable) {
barrier<is_marked_or_null_fast_path, mark_barrier_on_finalizable_oop_slow_path>(p, o);
} else {
const uintptr_t addr = ZOop::to_address(o);
if (ZAddress::is_good(addr)) {
// Mark through good oop
mark_barrier_on_oop_slow_path(addr);
} else {
// Mark through bad oop
barrier<is_good_or_null_fast_path, mark_barrier_on_oop_slow_path>(p, o);
}
}
}这里分了3个分支,finalizable先不看,根据指针是good还是bad有分了两个分支,这两个分支最终有都调用了 mark_barrier_on_oop_slow_path 慢路径处理方法。
这里直接看下面的第 2 个分支
template <ZBarrierFastPath fast_path, ZBarrierSlowPath slow_path>
inline oop ZBarrier::barrier(volatile oop* p, oop o) {
const uintptr_t addr = ZOop::to_address(o);
// Fast path
if (fast_path(addr)) {
return ZOop::from_address(addr);
}
// Slow path
const uintptr_t good_addr = slow_path(addr);
if (p != NULL) {
//指针自愈
self_heal<fast_path>(p, addr, good_addr);
}
return ZOop::from_address(good_addr);
}这是读屏障的核心逻辑代码,这里我们也看到了指针自愈。
从这段代码可以看到,首先执行快速路径检查,如果 fast_path(addr) 返回 true,则直接返回 addr 所对应的 oop 对象。 如果快速路径检查失败,则执行慢速路径检查,将 addr 传递给 slow_path 函数,并将返回值存储在 good_addr 变量中。 如果传入的指针 p 不为空,则调用 self_heal
这里的 slow_path 其实就是 mark_barrier_on_oop_slow_path 函数。
这里主要往下看两个函数,慢路径处理和指针自愈,慢路径处理流程比较长,我们先看指针自愈。
template <ZBarrierFastPath fast_path>
inline void ZBarrier::self_heal(volatile oop* p, uintptr_t addr, uintptr_t heal_addr) {
if (heal_addr == 0) {
// Never heal with null since it interacts badly with reference processing.
// A mutator clearing an oop would be similar to calling Reference.clear(),
// which would make the reference non-discoverable or silently dropped
// by the reference processor.
return;
}
assert(!fast_path(addr), "Invalid self heal");
assert(fast_path(heal_addr), "Invalid self heal");
for (;;) {
// Heal
const uintptr_t prev_addr = Atomic::cmpxchg((volatile uintptr_t*)p, addr, heal_addr);
if (prev_addr == addr) {
// Success
return;
}
if (fast_path(prev_addr)) {
// Must not self heal
return;
}
// The oop location was healed by another barrier, but still needs upgrading.
// Re-apply healing to make sure the oop is not left with weaker (remapped or
// finalizable) metadata bits than what this barrier tried to apply.
assert(ZAddress::offset(prev_addr) == ZAddress::offset(heal_addr), "Invalid offset");
addr = prev_addr;
}
}这个就比较简单了,类似 Java 的 cas 操作,把坏指针修改为好指针,然后执行快速路径。
好指针是上面执行慢路径返回的。
接下来看慢路径
//
// Mark barrier
//
uintptr_t ZBarrier::mark_barrier_on_oop_slow_path(uintptr_t addr) {
assert(during_mark(), "Invalid phase");
assert(ZThread::is_worker(), "Invalid thread");
// Mark
return mark<GCThread, Follow, Strong, Overflow>(addr);
}这里对进入读屏障的指针又进行了标记。
到这里,其实读屏障主要逻辑已经结束了,下面是读屏障触发的标记逻辑。
2.2.4 读屏障触发的标记逻辑
继续
template <bool gc_thread, bool follow, bool finalizable, bool publish>
uintptr_t ZBarrier::mark(uintptr_t addr) {
uintptr_t good_addr;
if (ZAddress::is_marked(addr)) {
// Already marked, but try to mark though anyway
good_addr = ZAddress::good(addr);
} else if (ZAddress::is_remapped(addr)) {
// Already remapped, but also needs to be marked
good_addr = ZAddress::good(addr);
} else {
// Needs to be both remapped and marked
good_addr = remap(addr);
}
// Mark
if (should_mark_through<finalizable>(addr)) {
ZHeap::heap()->mark_object<gc_thread, follow, finalizable, publish>(good_addr);
}
if (finalizable) {
// Make the oop finalizable marked/good, instead of normal marked/good.
// This is needed because an object might first becomes finalizable
// marked by the GC, and then loaded by a mutator thread. In this case,
// the mutator thread must be able to tell that the object needs to be
// strongly marked. The finalizable bit in the oop exists to make sure
// that a load of a finalizable marked oop will fall into the barrier
// slow path so that we can mark the object as strongly reachable.
return ZAddress::finalizable_good(good_addr);
}
return good_addr;
}这里要继续跟的函数有三个 ZAddress::good 、remap、ZHeap::heap()->mark_object。
ZHeap::heap()->mark_object 就是在堆中对对象进行标记。
先看下 ZAddress::good 的逻辑
inline uintptr_t ZAddress::offset(uintptr_t value) {
return value & ZAddressOffsetMask;
}
inline uintptr_t ZAddress::good(uintptr_t value) {
return offset(value) | ZAddressGoodMask;
}可以看到只是改变了下指针标记位,比较简单,也符合我们没读代码前对 ZGC 流程的认识。
2.2.5 重映射
继续看 remap 重映射方法,这里我们就找到了开头问题5【ZGC并发标记中的并发重映射过程】
uintptr_t ZBarrier::remap(uintptr_t addr) {
assert(!ZAddress::is_good(addr), "Should not be good");
assert(!ZAddress::is_weak_good(addr), "Should not be weak good");
return ZHeap::heap()->remap_object(addr);
}继续
inline uintptr_t ZHeap::relocate_object(uintptr_t addr) {
assert(ZGlobalPhase == ZPhaseRelocate, "Relocate not allowed");
ZForwarding* const forwarding = _forwarding_table.get(addr);
if (forwarding == NULL) {
// Not forwarding
return ZAddress::good(addr);
}
// Relocate object
return _relocate.relocate_object(forwarding, ZAddress::good(addr));
}可以看到这里先查转发表,转发表中不存在直接返回好指针,存在则执行重分配操作,再往下就是重分配的逻辑了,本文中就不详解了,在以后重分配文章中的详细介绍。
2.2.6 回到读屏障标记流程
然后,返回 2.2.4 开头,继续看 ZHeap::heap()->mark_object
template <bool gc_thread, bool follow, bool finalizable, bool publish>
inline void ZHeap::mark_object(uintptr_t addr) {
assert(ZGlobalPhase == ZPhaseMark, "Mark not allowed");
_mark.mark_object<gc_thread, follow, finalizable, publish>(addr);
}继续
template <bool gc_thread, bool follow, bool finalizable, bool publish>
inline void ZMark::mark_object(uintptr_t addr) {
assert(ZAddress::is_marked(addr), "Should be marked");
ZPage* const page = _page_table->get(addr);
if (page->is_allocating()) {
// Already implicitly marked
return;
}
const bool mark_before_push = gc_thread;
bool inc_live = false;
if (mark_before_push) {
// Try mark object
if (!page->mark_object(addr, finalizable, inc_live)) {
// Already marked
return;
}
} else {
// Don't push if already marked
if (page->is_object_marked<finalizable>(addr)) {
// Already marked
return;
}
}
// Push
ZMarkThreadLocalStacks* const stacks = ZThreadLocalData::stacks(Thread::current());
ZMarkStripe* const stripe = _stripes.stripe_for_addr(addr);
ZMarkStackEntry entry(addr, !mark_before_push, inc_live, follow, finalizable);
stacks->push(&_allocator, &_stripes, stripe, entry, publish);
}这里有两个重要逻辑,一是已经标记的不再进行 push,二是未标记过的 push 到栈里。
还记得前面的“记录点1”吗,push 指针 到栈里的地方就是这儿了,被 push 的指针将会在下次标记循环中被取出来。
到此,ZGC 三色标记的主流程就头尾相接了,完结撒花。
3、问题回顾
3.1 开头的问题
1.ZGC是如何在指针上标记的
2.ZGC三色标记的过程
3.ZGC只用了读屏障是如何防止漏标的
4.ZGC标记过程中的指针自愈过程
5.ZGC并发标记中的并发重映射过程
上面5个问题,1、2、4、5上面源码分析过程中都已经有了,问题3是要从整个流程上看。
3.2 ZGC只用了读屏障是如何防止漏标的
3.2.1 什么情况下会漏标
当以下两个情况同时发生时:
1.新增了一个从黑色对象到白色对象的新引用
2.删除了全部从灰色对象到该白色对象的引用
3.2.2 如何避免?
破坏条件1,这就是增量更新(Incremental Update)解决方案。
破坏条件2,这就是原始快照(Snapshot At The Beginning, SAT B )解决方案。
ZGC 采用的是增量更新解决方案。但是,增量更新不是新增吗,应该是写屏障啊,读屏障怎么做到呢?
其实新增一个引用时,之前肯定要从某处读到这个引用,那么这个读的操作便触发了读屏障。前面源码中,我们知道 ZGC 读屏障里有一个标记的过程,而且还会自动返回好指针,也就是说经过读屏障返回的指针中不存在白色对象,这就从根本上避免了条件1。
4、扩展思考
ZGC 标记是在指针上,而不是在对象上,当回收某个 region 时,对于此 region 里的某个对象,无法获得其他对象指向此对象的指针,那如何得知这对象是否存活呢?
这个问题需要我们将标记阶段和重分配阶段的代码连起来看才能得到答案了。
5、结束
对于ZGC并发标记的过程的源码分析就到这里了,如果觉得对您有启发或有帮助就多多点赞支持呀~
作者:京东物流 刘家存
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
- 0 文章数
- 0 关注者