


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一 前言
服务性能是指服务在特定条件下的响应速度、吞吐量和资源利用率等方面的表现。据统计,性能优化方面的精力投入,通常占软件开发周期的 10% 到 25% 左右,当然这和应用的性质和规模有关。性能对提高用户体验,保证系统可靠性,降低资源使用率,甚至增强市场竞争力等方面,都有着很大的影响。
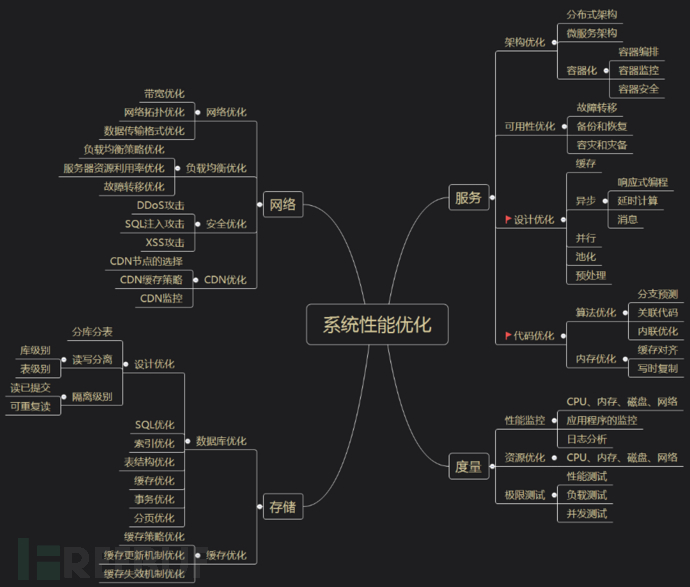
性能优化是个系统性工程,宏观上可分为网络,服务,存储几个方向,每个方向又可以细分为架构,设计,代码,可用性,度量等多个子项。本文将重点从代码和设计两个子项展开,谈谈那些提升性能的知识点。当然,很多性能提升策略都是有代价的,适用于某些特定场景,大家在学习和使用的时候,最好带着批判的思维,决策前,做好利弊权衡。
先简单罗列一下性能优化方向:
二 代码优化
2.1 关联代码
关联代码优化是通过预加载相关代码,避免在运行时加载目标代码,造成运行时负担。我们知道 Java 有两个类加载器:Bootstrap class loader 和 Application class loader。Bootstrap class loader 负责加载 Java API 中包含的核心类,而 Application class loader 则负责加载自定义类。关联代码优化可以通过以下几种方式来实现。
预加载关联
预加载关联类是指在程序启动时预先加载目标与关联类,以避免在运行时加载。可以通过静态代码块来实现预加载,如下所示:
public class MainClass {
static {
// 预加载MyClass,其实现了相关功能
Class.forName("com.example.MyClass");
}
// 运行相关功能的代码
// ...
}
使用线程池
线程池可以让多个任务使用同一个线程池中的线程,从而减少线程的创建和销毁成本。使用线程池时,可以在程序启动时创建线程池,并在主线程中预加载相关代码。然后以异步方式使用线程池中的线程来执行相关代码,可以提高程序的性能。
使用静态变量
可以使用静态变量来缓存与关联代码有关的对象和数据。在程序启动时,可以预先加载关联代码,并将对象或数据存储在静态变量中。然后在程序运行时使用静态变量中缓存的对象或数据,以避免重复加载和生成。这种方式可以有效地提高程序的性能,但需要注意静态变量的使用,确保它们在多线程环境中的安全性。
2.2 缓存对齐
在介绍缓存对齐之前,需要先普及一些 CPU 指令执行的相关知识。
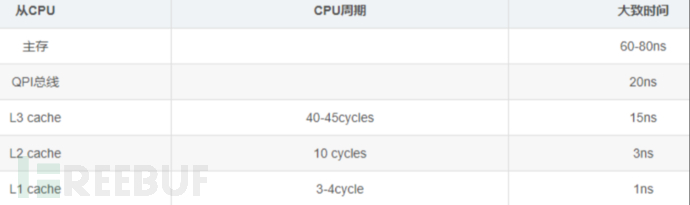
- 缓存行(Cache line) :CPU 读取内存数据时并非一次只读一个字节,一般是会读一段 64 字节(硬件决定)长度的连续的内存块 (chunks of memory),这些块我们称之为缓存行。
- 伪共享(False Sharing):当运行在两个不同 CPU 上的两个线程写入两个不同的变量时,如果这两个变量恰好存储在同一个 CPU 缓存行中,就会发生伪共享(False Sharing)。即当第一个线程修改缓存行中其中一个变量时,其他引用此缓存行变量的线程的缓存行将会无效。如果 CPU 需要读取失效的缓存行,它必须等待缓存行刷新,这会导致性能下降。
- CPU 停止运转(stall):当一个核心需要等待另一个核心重新加载缓存行时(出现伪共享时),它无法继续执行下一条指令,只能停止运转等待,这被称之为 stall。减少伪共享也就意味着减少了 stall 的发生。
- IPC(instructions per cycle):它表示平均每个 CPU 周期执行的指令数量,很显然该数值越大性能越好。可以基于 IPC 指标(比如:阈值 1.0)来简单判断程序是属于访问密集型还是计算密集型。Linux 系统中可以通过 tiptop 命令来查看每个进程的 CPU 硬件数据:

如何简单来区分访存密集型和计算密集型程序?
如果 IPC < 1.0, 很可能是 Memory stall 占主导,多半意味着访存密集型。
如果 IPC > 1.0, 很可能是计算密集型的程序。
- CPU 利用率:是指系统中 CPU 处于忙碌状态的时间与总时间的比例。忙碌状态时间又可以进一步拆分为指令(instruction)执行消耗周期 cycle (% INS) 和 stalled 的周期 cycle (% STL)。perf 采集了 10 秒内全部 CPU 的运行状态:
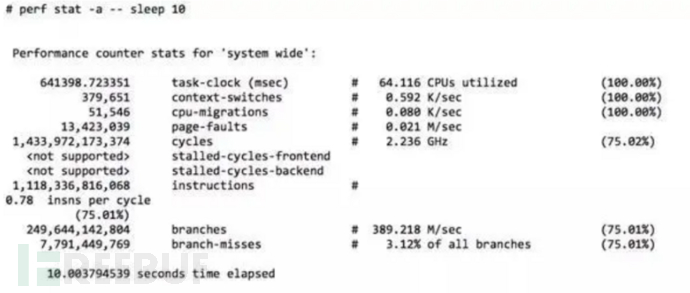
IPC计算
IPC = instructions/cycles
上图中,可以计算出结果为:0.79
现代处理器一般有多条流水线(比如:4核心),运行 perf 的那台机器,IPC的理论值可达到4.0。
如果我们从 IPC的角度来看,这台机器只运行到其处理器最高速度的 19.7%(0.79 / 4.0)。
总之,通过 Top 命令,看到 CPU 使用率之后,可以进一步分析指令执行消耗周期和 stalled 周期,有这些更详细的指标之后,就能够知道该如何更好地对应用和系统进行调优。
- 缓存对齐:是通过调整数据在内存中的分布,让数据在被缓存时,更有利于 CPU 从缓存中读取,从而避免了频繁的内存读取,提高了数据访问的速度。
缓存填充 (Padding)
减少伪共享也就意味着减少了 stall 的发生,其中一个手段就是通过填充 (Padding) 数据的形式,即在适当的距离处插入一些对齐的空间来填充缓存行,从而使每个线程的修改不会脏污同一个缓存行。
/**
* 缓存行填充测试
*
* @author liuhuiqing
* @date 2023年04月28日
*/
public class FalseSharingTest {
private static final int LOOP_NUM = 1000000000;
public static void main(String[] args) throws InterruptedException {
Struct struct = new Struct();
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < LOOP_NUM; i++) {
struct.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < LOOP_NUM; i++) {
struct.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost time [" + (System.currentTimeMillis() - start) + "] ms");
}
static class Struct {
// 共享变量
volatile long x;
// 一个long占用8个字节,此处定义7个填充数据,来保证业务数据x和y分布在不同的缓存行中
long p1, p2, p3, p4, p5, p6, p7;
// long[] paddings = new long[7];// 使用数组代替不会生效,思考一下,为什么?
// 共享变量
volatile long y;
}
}
经过本地测试,这种以空间换时间的方式,即实现了缓存行数据对齐的方式,在执行效率方面,比没有对齐之前,提高了 5 倍!
@Contended 注解
在 Java 8 中,引入了 @Contended 注解,该注解可以用来告诉 JVM 对字段进行缓存对齐(将字段放入不同的缓存行),从而提高程序的性能。使用 @Contended 注解时,需要在 JVM 启动时添加参数 - XX:-RestrictContended,实现如下所示:
import sun.misc.Contended;
public class ContendedTest {
@Contended
volatile long a;
@Contended
volatile long b;
public static void main(String[] args) throws InterruptedException {
ContendedTest c = new ContendedTest();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000_0000L; i++) {
c.a = i;
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000_0000L; i++) {
c.b = i;
}
});
final long start = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
对齐内存与本地变量
缓存填充是解决 CPU 伪共享问题的解决方案之一,在实际应用中,是否还有其它方案来解决这一问题呢?答案是有的:即对齐内存和本地变量。
- 对齐内存:内存行的大小一般为 64 个字节,这个大小是硬件决定的,但大多数编译器默认情况下都以 4 字节的边界对齐,通过将变量按照内存行的大小对齐,可以避免伪共享问题;
- 本地变量:在不同线程之间使用不同的变量存储数据,避免不同的线程之间共享同一块内存,Java 中的 ThreadLocal 就是一种典型的实现方式;
2.3 分支预测
分支预测是 CPU 动态执行技术中的主要内容,是通过猜测程序中的分支语句(如 if-else 语句或者循环语句)的执行路径来提高 CPU 执行效率的技术。其原理是根据之前的历史记录和统计数据,预测程序下一步要执行的指令是分支跳转指令还是顺序执行指令,从而提前加载相关数据,减少 CPU 等待指令执行的空闲时间。预测准确率越高,CPU 的性能提升就越高。那么如何提高预测的准确率呢?
- 关注圈复杂度
过多的条件语句和嵌套的条件语句会导致分支的预测难度大幅上升,从而降低分支预测的准确率和效率。一般来说,可以通过优化代码逻辑结构、减少冗余等方式来避免过多的条件语句和嵌套的条件语句。
- 优先处理常用路径
在编写代码时,应该优先处理常用路径,以减少 CPU 对分支的预测,提高预测准确率和效率。例如,在 if-else 语句中,应该将常用的路径放在 if 语句中,而将不常用的路径放在 else 语句中。
2.4 写时复制
Copy-On-Write (COW) 是一种内存管理机制,也被称为写时复制。其主要思想是在需要写入数据时,先进行数据拷贝,然后再进行操作,从而避免了对数据进行不必要的复制和操作。COW 机制可以有效地降低内存使用率,提高程序的性能。
在创建进程或线程的时候,操作系统为其分配内存时,不是复制一个完整的物理地址空间,而是创建一个指向父进程 / 线程物理地址空间的虚拟地址空间,并为它们的所有页面设置 "只读" 标志。当子进程 / 线程需要修改页面时,会触发一个缺页异常,并将涉及到的页面进行数据的复制,并为复制的页面重新分配内存。子进程 / 线程只能够操作复制后的地址空间,父进程 / 线程的原始内存空间则被保留。
由于 COW 机制在写入之前进行数据拷贝,所以可以有效地避免频繁的内存拷贝和分配操作,降低了内存的占用率,提高了程序的性能。并且,COW 机制也避免了数据的不必要复制,从而减少了内存的消耗和内存碎片的产生,提高了系统中可用内存的数量。
ArrayList 类可以使用 Copy-On-Write 机制来提高性能。
// 初始化数组
private List<String> list = new CopyOnWriteArrayList<>();
// 向数组中添加元素
list.add("value");
需要注意的是,Copy-On-Write 机制适用于读操作比写操作多的情况,因为它假定写操作的频率较低,从而可以通过牺牲复制的开销来减少锁的操作和内存分配的消耗。
2.5 内联优化
在 Java 中,每次调用方法都需要进行一些额外的操作,例如创建堆栈帧、保存寄存器状态等,这些额外的操作会消耗一定的时间和内存资源。内联优化是一种编译器优化技术,Java 虚拟机通常使用即时编译器(JIT)来进行方法内联,用于提高程序的性能。内联优化的目标是将函数的调用替换成函数本身的代码,以减少函数调用的开销,从而提高程序的运行效率。
需要注意的是,方法内联并不是在所有情况下都能够提高程序的运行效率。如果方法内联导致代码复杂度增加或者内存占用增加,反而会降低程序的性能。因此,在使用方法内联时需要根据具体情况进行权衡和优化。
final 修饰符
final 修饰符可以使方法成为不可重写的方法。因为不可重写,所以在编译器优化时可以将它们的代码嵌入到调用它们的代码中,从而避免函数调用的开销。使用 final 修饰符可以在一定程度上提高程序的性能,但同时也减弱了代码的可扩展性。
限制方法长度
方法的长度会影响其在编译时能否被内联。通常情况下,长度较小的方法更容易被内联。因此,可以在设计中将代码分解和重构为更小的函数。这种方式并不是 100%确保可以内联,但至少提高了实现此优化的机会。内联调优参数,如下表格:
| JVM 参数 | 默认值 (JDK 8, Linux x86_64) | 参数说明 |
|---|---|---|
| -XX:MaxInlineSize=<n> | 35 字节码 | 内联方法大小上限 |
| -XX:FreqInlineSize=<n> | 325 字节码 | 内联热方法的最大值 |
| -XX:InlineSmallCode=<n> | 1000 字节的原生代码(非分层) 2000 字节的原生代码(分层编译) | 如果最后一层的的分层编译代码量已经超过这个值,就不进行内联编译 |
| -XX:MaxInlineLevel=<n> | 9 | 调用层级比这个值深的话,就不进行内联 |
内联注解
在 Java 5 之后,引入了内联注解 @inline,使用此注解可以在编译时通知编译器,将该方法内联到它的调用处。注解 @inline 在 Java 9 之后已经被弃用,可以使用 @ForceInline 注释来替代,同时设置 JVM 参数:
-XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:+JVMCICompiler
@ForceInline
public static int add(int a, int b) {
return a + b;
}
2.6 编码优化
反射机制
Java 反射在一定程度上会影响性能,因为它需要在运行时进行类型检查转换和方法查找,这比直接调用方法会更耗时。此外,反射也不会受到编译器的优化,因此可能会导致更慢的代码执行速度。
要解决这个问题有以下几种方式:
- 尽可能使用原生方法调用,而不是通过反射调用;
- 尽可能缓存反射调用结果,避免重复调用。例如,可以将反射结果缓存到静态变量中,以便下次使用时直接获取,而不必再次使用反射;
- 使用字节码增强技术;
下面着重介绍一下反射结果缓存和字节码增强两种方案。
- 反射结果缓存可以大幅减少反射过程中的类型检查,类型转换和方法查找等动作,是降低反射对程序执行效率影响的一种优化策略。
/**
* 反射工具类
*
* @author liuhuiqing
* @date 2023年5月7日
*/
public abstract class BeanUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(BeanUtils.class);
private static final Field[] NO_FIELDS = {};
private static final Map<Class<?>, Field[]> DECLARED_FIELDS_CACHE = new ConcurrentReferenceHashMap<Class<?>, Field[]>(256);
private static final Map<Class<?>, Field[]> FIELDS_CACHE = new ConcurrentReferenceHashMap<Class<?>, Field[]>(256);
/**
* 获取当前类及其父类的属性数组
*
* @param clazz
* @return
*/
public static Field[] getFields(Class<?> clazz) {
if (clazz == null) {
throw new IllegalArgumentException("Class must not be null");
}
Field[] result = FIELDS_CACHE.get(clazz);
if (result == null) {
Field[] fields = NO_FIELDS;
Class<?> searchType = clazz;
while (Object.class != searchType && searchType != null) {
Field[] tempFields = getDeclaredFields(searchType);
fields = mergeArray(fields, tempFields);
searchType = searchType.getSuperclass();
}
result = fields;
FIELDS_CACHE.put(clazz, (result.length == 0 ? NO_FIELDS : result));
}
return result;
}
/**
* 获取当前类属性数组(不包含父类的属性)
*
* @param clazz
* @return
*/
public static Field[] getDeclaredFields(Class<?> clazz) {
if (clazz == null) {
throw new IllegalArgumentException("Class must not be null");
}
Field[] result = DECLARED_FIELDS_CACHE.get(clazz);
if (result == null) {
result = clazz.getDeclaredFields();
DECLARED_FIELDS_CACHE.put(clazz, (result.length == 0 ? NO_FIELDS : result));
}
return result;
}
/**
* 数组合并
*
* @param array1
* @param array2
* @param <T>
* @return
*/
public static <T> T[] mergeArray(final T[] array1, final T... array2) {
if (array1 == null || array1.length < 1) {
return array2;
}
if (array2 == null || array2.length < 1) {
return array1;
}
Class<?> compType = array1.getClass().getComponentType();
int newArrLength = array1.length + array2.length;
T[] newArr = (T[]) Array.newInstance(compType, newArrLength);
int firstArrayLen = array1.length;
System.arraycopy(array1, 0, newArr, 0, firstArrayLen);
try {
System.arraycopy(array2, 0, newArr, firstArrayLen, array2.length);
} catch (ArrayStoreException ase) {
final Class<?> type2 = array2.getClass().getComponentType();
if (!compType.isAssignableFrom(type2)) {
throw new IllegalArgumentException("Cannot store " + type2.getName() + " in an array of "
+ compType.getName(), ase);
}
throw ase;
}
return newArr;
}
}
- 字节码增强技术,一般使用第三方库来实现,例如 Javassist 或 Byte Buddy,在运行时生成字节码,从而避免使用反射。
为什么动态字节码生成方式相比反射也可以提高执行效率呢?
- 动态字节码生成的方式在编译期就已经将类型信息确定下来,无需进行类型检查和转换;
- 动态字节码生成的方式可以直接调用方法,无需查找,提高了执行效率;
- 动态字节码生成的方式只需要在生成字节码时获取一次 Method 对象,多次调用时可以直接使用,避免了重复获取 Method 对象的开销;
这里就不再举例说明了,感兴趣的同学可以自行查阅资料进行深入学习。
异常处理
有效的处理异常可以保证程序的稳定性和可靠性。但异常的处理对性能还是有一定的影响的,这一点常常被人忽视。影响性能的具体表现为:
- 响应延迟:当异常被抛出时,Java 虚拟机需要查找并执行相应的异常处理程序,这会导致一定的延迟。如果程序中存在大量的异常处理,这些延迟可能会累积,导致程序的整体性能下降。
- 内存占用:异常处理需要在堆栈中创建异常对象,这些对象需要占用内存。如果程序中存在大量的异常处理,这些异常对象可能会占用大量的内存,导致程序的整体内存占用量增加。
- CPU 占用:异常处理需要执行额外的代码,这会导致 CPU 占用率增加。如果程序中存在大量的异常处理,这些额外的代码可能会导致 CPU 占用率过高,导致程序的整体性能下降。
一些基准测试显示,异常处理可能会导致程序的性能下降几个百分点。在 Java 虚拟机规范中提到,在没有异常发生的情况下,基于堆栈的方法调用可能比基于异常的方法调用快 2-3 倍。此外,一些实验表明,在异常处理程序中使用大量的 try-catch 语句,可能会导致性能下降 10 倍以上。
为避免这些问题,在编写代码时谨慎地使用异常处理机制,并确保对异常进行适当的记录和报告,避免过度使用异常处理机制。
日志处理
先看以下代码:
LOGGER.info("result:" + JsonUtil.write2JsonStr(contextAdContains) + ", logid = " + DigitThreadLocal.getLogId());
以上示例代码中,类似的日志打印方式很常见,难道有什么问题吗?
- 性能问题:每次使用 + 进行字符串拼接时,都会创建一个新的字符串对象,这可能会导致内存分配和垃圾回收的开销增加;
- 可读性问题:使用 + 进行字符串拼接时,代码可能会变得难以阅读和理解,特别是在需要连接多个字符串时;
- 如果日志级别调整到 ERROR 模式,我们希望日志的字符串内容不需要进行加工计算,但这种写法,即使日志处于不需要打印的模式,日志内容也进行了无效计算;
特别实在请求量和日志打印量比较高的场景下,日志内容的序列化和写文件操作,对服务的耗时影响可以达到 10%,甚至更多。
临时对象
临时对象通常是指在方法内部创建的对象。大量创建临时对象会导致 Java 虚拟机频繁进行垃圾回收,从而影响程序的性能。也会占用大量的内存空间,从而导致程序崩溃或者出现内存泄漏等问题。
为了避免大量创建临时对象,在编码时,可以采取以下措施:
- 字符串拼接中,使用 StringBuilder 或 StringBuffer 进行字符串拼接,避免使用连接符,每次都创建新的字符串对象;
- 在集合操作中,尽量使用批量操作,如 addAll、removeAll 等,避免频繁的 add、remove 操作,触发数组的扩容或者缩容;
- 在正则表达式中,可以使用 Pattern.compile () 方法预编译正则表达式,避免每次都创建新的 Matcher 对象;
- 尽量使用基本数据类型,避免使用包装类,因为包装类的创建和销毁都会产生临时对象;
- 尽量使用对象池的方式创建和管理对象,比如使用静态工厂方法创建对象,避免使用 new 关键字创建对象,因为静态工厂方法可以重用对象,避免创建新的临时对象;
临时对象的生命周期应该尽可能短,以便及时释放内存资源。临时对象的生命周期过长通常是由以下原因引起的:
- 对象未被正确地释放:如果在方法执行完毕后,临时对象没有被正确地释放,就会导致内存泄漏风险;
- 对象过度共享:如果临时对象被过度共享,就可能会导致多个线程同时访问同一个对象,从而导致线程安全问题和性能问题;
- 对象创建过于频繁:如果在方法内部频繁地创建临时对象,就会导致内存开销过大,可能会引起性能甚至内存溢出问题;
为避免临时对象的生命周期过长,建议采取以下措施:
- 及时释放对象:在方法执行完毕后,应该及时释放临时对象(比如主动将对象设置为 null),以便回收内存资源;
- 避免过度共享:在多线程环境下,应该避免过度共享临时对象,可以使用局部变量或 ThreadLocal 等方式来避免共享问题;
- 对象池技术:使用对象池技术可以避免频繁创建临时对象,从而降低内存开销。对象池可以预先创建一定数量的对象,并在需要时从池中获取对象,使用完毕后再将对象放回池中;
小结
正所谓:“不积跬步,无以至千里;不积小流,无以成江海”。以上列举的编码细节,都会直接或间接的影响服务的执行效率,只是影响多少的问题。现实中,有时候我们不必过于苛求,但它们有一个共同的注脚:极客精神。
三 设计优化
3.1 缓存
合理使用缓存可以有效提高应用程序的性能,缩短数据访问时间,降低对数据源的依赖性。缓存可以进行多层级的设计,举例,为了提高运行效率,CPU 就设计了 L1-L3 三级缓存。在应用设计的时候,我们也可以按照业务诉求进行层设计。常见的分层设计有本地缓存(L1),远程分布式缓存(L2)两级。
本地缓存可以减少网络请求、节约计算资源、减少高负载数据源访问等优势,进而提高应用程序的响应速度和吞吐量。常见的本地缓存中间件有:Caffeine、Guava Cache、Ehcache。当然你也可以在使用类似 Map 容器,在应用程序中构建自己的缓存结构。 分布式缓存相比本地缓存的优势是可以保证数据一致性、只保留一份数据,减少数据冗余、可以实现数据分片,实现大容量数据的存储。常见的分布式缓存有:Redis、Memcached。
实现一个简单的 LRU 本地缓存示例如下:
/**
* Least recently used 内存缓存过期策略:最近最少使用
* Title: 带容量的<b>线程不安全的</b>最近访问排序的Hashmap
* Description: 最后访问的元素在最后面。<br>
* 如果要线程安全,请使用<pre>Collections.synchronizedMap(new LRUHashMap(123));</pre> <br>
*
* @author: liuhuiqing
* @date: 20123/4/27
*/
public class LRUHashMap<K, V> extends LinkedHashMap<K, V> {
/**
* The Size.
*/
private final int maxSize;
/**
* 初始化一个最大值, 按访问顺序排序
*
* @param maxSize the max size
*/
public LRUHashMap(int maxSize) {
//0.75是默认值,true表示按访问顺序排序
super(maxSize, 0.75f, true);
this.maxSize = maxSize;
}
/**
* 初始化一个最大值, 按指定顺序排序
*
* @param maxSize 最大值
* @param accessOrder true表示按访问顺序排序,false为插入顺序
*/
public LRUHashMap(int maxSize, boolean accessOrder) {
//0.75是默认值,true表示按访问顺序排序,false为插入顺序
super(maxSize, 0.75f, accessOrder);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > maxSize;
}
}
3.2 异步
异步可以提高程序的性能和响应能力,使其能更高效地处理大规模数据或并发请求。其底层原理涉及到操作系统的多线程、事件循环、任务队列以及回调函数等关键技术,除此之外,异步的思想在应用架构设计方面也有广泛的应用。常规的多线程,消息队列,响应式编程等异步处理方案这里就不再展开介绍了,这里介绍两个大家可能容易忽视但实用技能:非阻塞 IO 和 协程。
非阻塞 IO
Java Servlet 3.0 规范中引入了异步 Servlet 的概念,可以帮助开发者提高应用程序的性能和并发处理能力,其原理是非阻塞 IO 使用单线程同时处理多个请求,避免了线程切换和阻塞的开销,特别是在读取大文件或者进行复杂耗时计算场景时,可以避免阻塞其他请求的处理。Spring MVC 框架中也提供了相应的异步处理方案。
・使用 Callable 方式实现异步处理
@GetMapping("/async/callable")
public WebAsyncTask<String> asyncCallable() {
Callable<String> callable = () -> {
// 执行异步操作
return "异步任务已完成";
};
return new WebAsyncTask<>(10000, callable);
}
・使用 DeferredResult 方式实现异步处理
@GetMapping("/async/deferredresult")
public DeferredResult<String> asyncDeferredResult() {
DeferredResult<String> deferredResult = new DeferredResult<>(10000L);
// 异步处理完成后设置结果
deferredResult.setResult("DeferredResult异步任务已完成");
return deferredResult;
}
协程
我们知道线程的创建、销毁都十分消耗系统资源,所以有了线程池,但这还不够,因为线程的数量是有限的(千级别),线程会阻塞操作系统线程,无法尽可能的提高吞吐量。因为使用线程的成本很高,所以才会有了虚拟线程,它是用户态线程,成本是相当低廉的,调度也完全由用户进行控制(JDK 中的调度器),它同样可以进行阻塞,但不用阻塞操作系统线程,充分提高了硬件利用率,高并发也上了一个量级。
很长一段时间,协程概念并非作为 JVM 内置的功能,而是通过第三方库或框架实现的。目前比较常用的协程实现库有 Quasar、Kilim 等。但在 Java19 版本中,引入了虚拟线程(Virtual Threads )的支持(处于 Preview 阶段)。
虚拟线程是 java.lang.Thread 的一个实现,可以使用 java.lang.Thread.Builder 接口创建
Thread thread = Thread.ofVirtual()
.name("Virtual Threads")
.unstarted(runnable);
也可以通过一个线程工厂类进行创建:
ThreadFactory factory = Thread.ofVirtual().factory();
虚拟线程运行的载体必须是线程,同一个线程中可以运行多个虚拟线程实例。
3.3 并行
并行处理的思想在大数据,多任务,流水线处理,模型训练等各个方面发挥着重要作用,包括前面介绍的异步(多线程,协程,消息等),也是建立在并行的基础上。在应用层面,典型的场景有:
- 分布式计算框架中的 MapReduce 就是采用一种分而治之的思想设计出来的,将复杂或计算量大的任务,切分成一个个小的任务,小任务分别在不同的线程或服务器上并行的执行,最终再汇总每个小任务的结果。
- 边缘计算(Edge Computing)是一种分布式计算范式,它将计算、存储和网络服务的部分功能从云数据中心延伸至离数据源更近的地方,即网络的边缘。这种计算方式能够实现低延迟、节省带宽、提高数据安全性以及实时处理与分析等优势。
在代码实现方面,做好解耦设计,接下来就可以进行并行设计了,比如:
- 多个请求可以通过多线程并行处理,每个请求的不同处理阶段;
- 如查询阶段,可以采用协程并行执行;
- 存储阶段,可以采用消息订阅发布的方式进行处理;
- 监控统计阶段,就可以采用 NIO 异步的方式进行指标数据文件的写入;
- 请求 / 响应采用非阻塞 IO 模式;
3.4 池化
池化就是初始预设资源,降低每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。典型的场景就是线程池,数据库连接池,业务处理结果缓存池等。
以数据库连接池为例,其本质是一个 socket 的连接。为每个请求打开和维护数据库连接,尤其是动态数据库驱动的应用程序的请求,既昂贵又浪费资源。为什么这么说呢?以 MySQL 数据库建立连接(TCP 协议)为例,建立连接总共分三步:
- 建立 TCP 连接,通过三次握手实现;
- 服务器发送给客户端「握手信息」 ,客户端响应该握手消息;
- 客户端「发送认证包」 ,用于用户验证,验证成功后,服务器返回 OK 响应,之后开始执行命令;
简单粗略统计,完成一次数据库连接,客户端和服务器之间需要至少往返 7 次,总计平均耗时大约在 200ms 左右,这对于很对 C 端服务来说,几乎是不能接受的。
落实到代码编写层面,也可以借助这一思想来优化我们的程序执行性能。
- 公用的数据可以全局只定义一份,比如使用枚举,static 修饰的容器对象等;
- 根据实际情况,提前设置 List,Map 等容器对象的初始化容量大小,防止后面的扩容,对性能的影响;
- 亨元设计模式的应用等;
3.5 预处理
一般需要池化的内容,都是需要预处理的,比如为了保证服务的稳定性,线程池和数据库连接池等需要池化的内容在 JVM 容器启动时,处理真正请求之前,对这些池化内容进行预处理,等到真正的业务处理请求过来时,可以正常的快速处理。除此之外,预处理还可以体现在系统架构层面。
- 为了提高响应性能,将部分业务数据提前预加载到内存中;
- 为了减轻 CPU 压力,将计算逻辑提前执行,直接将计算后的结果数据保存下来,直接供调用方使用;
- 为了降低网络带宽成本,将传输数据通过压缩算法进行压缩处理,到了目标服务,在进行解压,获得原始数据;
- Myibatis 为了提高 SQL 语句的安全性和执行效率,也引入了预处理的概念;
四 总结
性能优化是程序开发过程中绕不过去一个课题,本文聚焦代码和设计两个方面,从 CPU 硬件到 JVM 容器,从缓存设计到数据预处理,全面的展现了性能优化的实施方向和落地细节。阐述的过程没有追求各个方向的面面俱到,但都给到了一些场景化案例,来辅助理解和思考,起到抛砖引玉的效果。
作者:京东零售 刘慧卿
内容来源:京东云开发者社区
- 0 文章数
- 0 关注者