


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
一、前言
本次文章只用于技术讨论,学习,切勿用于非法用途,用于非法用途与本人无关!
所有环境均为本地环境分析,且在本机进行学习。
这章写的比较简单,主要就是对整数、浮点数、字符串、地址、指针、引用赋值进行了分析。作者:rkabyss
二、数据类型分析
1、整数类型
C/C++提供的整数数据类型有三种∶int、long、short。int 类型与 long类型在内存中都占4个字节,short 类型在内存中占两个字节。 由于二进制数不方便显示和阅读,因此内存中的数据采用十六进制数显示。一个字节由两个十六进制数组成,在进制转换中,一个十六进制数可用 4 个二进制数表示,每个二进制数表示1位,因此一个字节在内存中占8位。
(1)short短整型分析
X86
#include <stdio.h>
#include <stdlib.h>
int main()
{
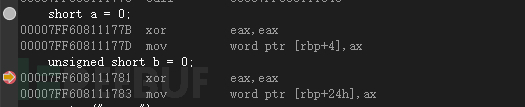
short a = 0;
unsigned short b = 0;
system("pause");
return 0;
}short短整型,宽度2个字节16位,unsigned用来标识数据类型为无符号类型,不带unsigned默认为带符号数据类型。xor eax,eax命令(异或:如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0。)eax跟eax值一样,所以eax异或eax,是在做清空操作。
看到word ptr [ebp-8],ax跟word ptr [ebp-14h],ax,大家有没有疑惑,不是short是2个字节,但是为什么0赋值给a跟b的地址空间差了4个字节?因为数据宽度和地址长度是没有关系的,在32位程序中地址长度就是32位,数据类型虽然是2字节但是地址空间使用的是4字节,在64位程序中同理。但是他保存的值是有区别的,short a = 0虽然内存地址占了32位,但是a还是只有16位。ax为eax的低16位赋值给ebp-8并且接收宽度为word,也可以看出数据长度为两字节。

关于有符号与无符号,其实在内存中short他还是就2字节,要是在内存中光看是没什么的,只是在执行的时候结果会有所区别。有符号只是在最高位多了一个符号位,以至于当最高位为1即为负数,0为整数,所以有符号数会比无符号数短一截。

X64
在64位程序中,除了地址宽度变长了之外,其他的跟32位程序没有区别。
(2)int整数分析
X86
#include <stdio.h>
#include <stdlib.h>
int main()
{
int a = 0;
unsigned int b = 0;
system("pause");
return 0;
}可以看到,整型宽度为4字节,用dword来存储数据,其他没什么区别。

X64
整型也是相同,除了地址宽度变长了之外,其他的跟32位程序没有区别。

(3)long长整型分析
X86
#include <stdio.h>
#include <stdlib.h>
int main()
{
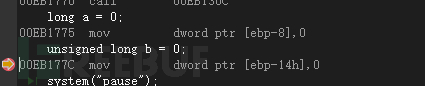
long a = 0;
unsigned long b = 0;
system("pause");
return 0;
}long类型也是4字节,用dword来存储数据,其他没什么区别。
#include <stdio.h>
#include <stdlib.h>
int main()
{
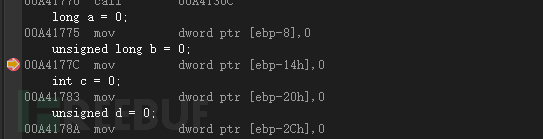
long a = 0;
unsigned long b = 0;
int c = 0;
unsigned d = 0;
system("pause");
return 0;
}通过long跟int进行比对,可以发现他们没有区别,所以在之后逆向中,看到一个数据是用dword类型接收,不一定就是int类型,他还有可能是long类型。
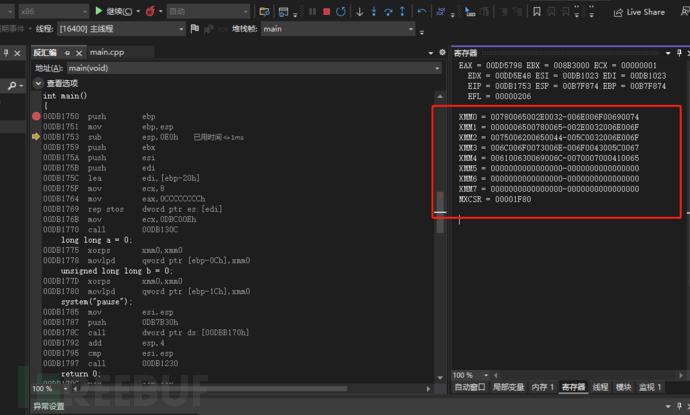
在定义中long型大小不低于int类型大小,但是没有明确说必须要大于int类型,在VC++跟VS中,long型只占4字节,我记得我高中第一个接触的语言VB中long类型就是8字节,java语言long类型也是8字节。C/C++声明64位长整型用long long声明。
#include <stdio.h>
#include <stdlib.h>
int main()
{
long long a = 0;
unsigned long long b = 0;
system("pause");
return 0;
}可以看到使用了一个xmm的寄存器,因为long long类型是64位,是从大的放入小的地方,所以超出了32位的四字节,使用了xmm寄存器作为转换。xorps跟xor功能一样都是异或,只是处理的寄存器不同,它们都是在清空处理器里面内容,movpd其实是一个通道指令,用来处理XMM和MM寄存器的。
movlpd qword ptr [ebp-0Ch],xmm0 //将低64位传入到ebp-0Ch内存中

XMM寄存器一共有8个,每个都是128位的寄存器。
X64
64位程序可以看见用qword接收,也没有使用xmm0寄存器来接收。

2、浮点数类型
#include <stdio.h>
#include <stdlib.h>
int main()
{
float a = 12.25; //占4字节
double b = 25.45; //占8字节
system("pause");
return 0;
}float a = 12.25;通过在内存中可以看到a的内容是00004441,因为它使用了一个IEEE编码。
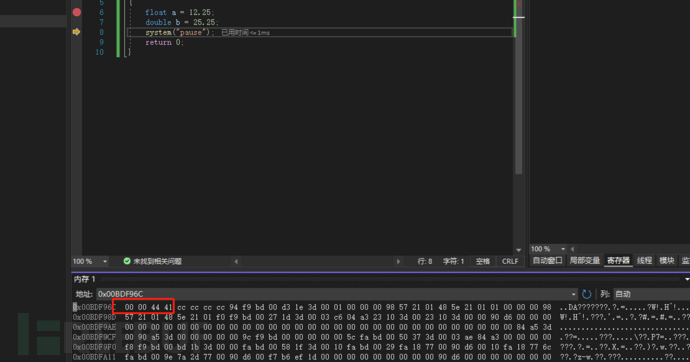
float 类型在内存中占4字节(32位)。最高位用于表示符号;在剩余的31位中,从右向左取8位用于表示指数,其余用于表示尾数。
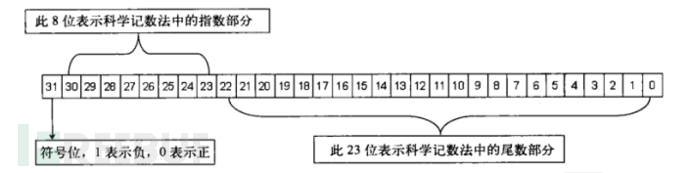
12.25如何转换成的00004441的呢,接下来就算一下。
首先算一下把他们都转换成二进制数,对于浮点数先将整数进行转换,以整数进行整除,因为要转成二进制所以除以2,最后倒着取就是1100
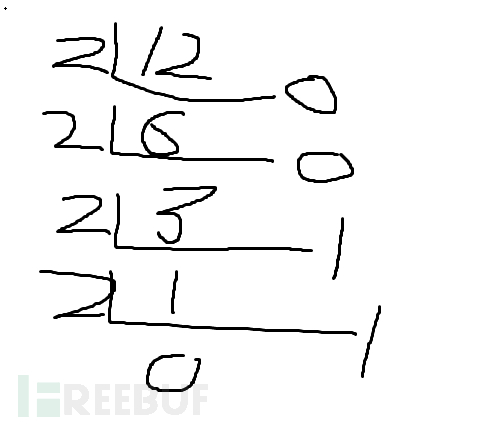
后面小数转二进制计算是,通过后面小数0.25乘要转的进制,不为整数就一直乘,乘到没有小数为止。最终小数部分二进制为01,所以12.25转二进制为1100.01
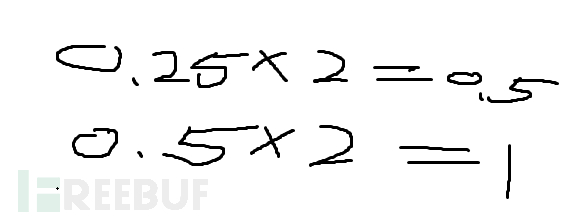
接下来二进制1100.01要进行移位,移到符号位的后面,也就是成1.10001,一共左移了三位,所以指数为3,再加上127,它是用来区分正负数的,大于就是整数,小于就是负数。所以最后指数部分就是10000010
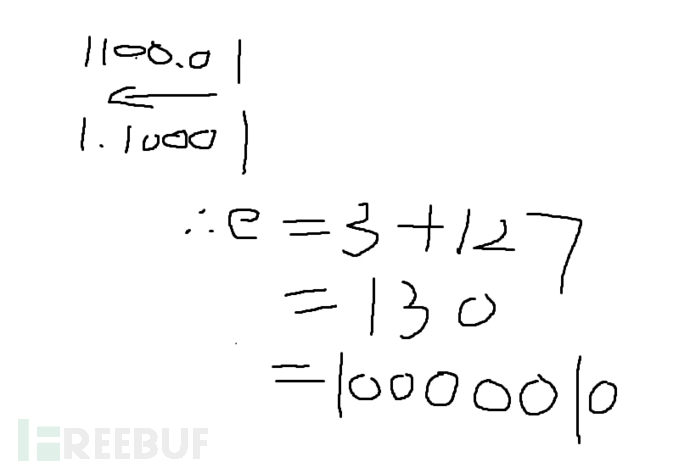
最后就是尾数部分,根据上一步移位之后是1.10001,尾数就是10001,因为float尾数部分一共有23位,所以将
10001后面填充0,知道满23位,即为10001000000000000000000
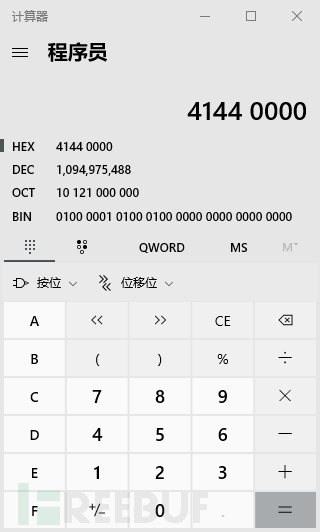
符号位:0 指数:10000010 尾数:10001000000000000000000 将三个合到一起:01000001010001000000000000000000
将01000001010001000000000000000000丢到计算器里可以看到这个值就是a在内存中的值。
3、字符和字符串
字符串是由多个字符按照一定排列顺序组成的,在C/C++中,以"0'作为字符串结束标记。每个字符都记录在一张表中,它们各自对应一个唯一编号,系统通过这些编号查找到对应的字符并显示。
(1)字符编码
在C++中,字符的编码格式分两种∶ASCI和 Unicode。Unicode是 ASCII的升级编码格式,它弥补了 ASCII 的不足,也是未来编码格式的趋势。ASCI编码在内存中占一个字节大小,由0~255之间的数字组成。每个数字表示一个符号,具体表示方式可查看 ASCI表。由于 ASCII 编码也是由数字组成的,故可以和整型互相转换,但整数不可超过 ASCII的最大表示范围,因为多余部分将被舍弃。 由于ASCII 原来的表示范围太小,只能表示英文的26个字母和常用符号。在亚洲,ASCI 的表示范围完全不够用。仅汉字就足够占满 ASCII编码。因此,占双字节、表示范围为0~65535的 Unicode 编码产生了。
ASCII使用GB2312-80,又叫汉字国标码,保存了6763个常用汉字编码,用两个字节来表示一个汉字。在GB2312-80中用区和位来定位,第一个字节保存每个区,共94个区;第二个字节保存每个区中的位,共94位。详细信息可查看GB2312-80 编码的说明。 Unicode 使用UCS-2编码格式,最多可存储 65536个字符。汉字博大精深,其中有简体字、繁体字,以及网络中流行的火星文,它们的总和远远超过了UCS-2的存储范围,所以UCS-2编码格式中只保存了常用字。为了将所有的汉字都容纳进来,Unicode 也采用了与ASCII类似的方式———用两个Unicode 编码解释一个汉字,称之为 UCS-4编码格式。UCS-2 编码表的使用和ASCII码表的使用是一样的。每个数字编号在表中对应一个汉字,从0x4E00到0x9520为汉字编码区。
(2)字符串类型分析
一共有两种赋值,一种赋值字符串,另一种是赋值字符,字符又可以直接赋值字符或编码值。
#include <stdio.h>
#include <stdlib.h>
#include <string>
int main()
{
char a = 'a';
char b = 65;
system("pause");
return 0;
}看到字符和字符编码都可以直接进行赋值。

赋值字符串
#include <stdio.h>
#include <stdlib.h>
#include <string>
int main()
{
char a[] = "rkabyss";
system("pause");
return 0;
}我把rkabyss字符串赋值给a,底层操作是把01017B30h和01017B34h两个的地址里的内容分别存放到了eax和ecx寄存器中,再将寄存器内容分别放到ebp-0Ch和ebp-8位置,a指向的就是rkabyss字符串的首地址,这样就达到了赋值的目的。

01017B30h内存地址存的是rkab

01017B34h内存地址存的是yss\0

在32位中所有寄存器都只有四字节,那么要是字符串正好四个字符,观察底层是如何做的。
操作其实跟上边是一样的,003C7B30h地址内容放到eax寄存器中,再将eax寄存器内容放到ebp-0Ch位置,唯一不同的是\0的处理方式,它使用一个16位CX寄存器的低8位寄存器来存放\0,并将其放到rkab字符后边。

003C7B30h内存地址存的是rkab

003C7B34h内存地址存的是\0

上边看到的都是短的字符赋值,那么如果是长字符串底层如何操作呢。看下图,首先他给ecx进行了赋值,这个赋的值是要循环的次数,然后引用了一个概念,就是源地址(esi)与目的地址(edi),将我们赋值的一大串字符串赋值给了源地址(esi)。第三行[ebp-24h]它是一个局部变量,他其实就是a指向的地方,目的地址(edi)获取[ebp-24h]的地址,其实就相当于edi指向的地址就是a的地址。rep movs他是将源地址内容拷贝到目的地址并进行循环,循环次数就是ecx里面的值,循环完也就把字符串全部赋值给了a。

397CD8h内存地址存的是赋值的一长串字符串。

4、布尔类型
布尔类型是用于判断执行结果的数据类型,它的判断比较值只有两种情况∶0与非0。C++中定义0为假,非0为真。使用bool定义布尔类型变量。布尔类型在内存中占1字节。由于布尔类型只比较两个结果值∶真、假,实际上任何一种数据类型都可以将其代替,如整型、字符型,甚至可以用位代替。在实际案例中也是难以将布尔类型数据还原成源码的,但是可以将其还原成等价代码。布尔类型出现的场合都是在做真假判断,有了这个特性,还原成等价代码还是相对简单的。
5、地址、指针和引用
地址:取一个变量的地址使用“&”符号,只有变量才存在内存地址,常量没有地址(不包括const定义的伪常量)。
指针 :指针的定义使用"TYPE*",TYPE 为数据类型,任何数据类型都可以定义指针。指针本身也是一种数据类型,它用于保存各种数据类型在内存中的地址。指针变量同样可以取出地址,所以会出现多级指针。
引用: 引用的定义使用"TYPE&",TYPE 为数据类型。在C++中是不可以单独定义的,并且在定义时就要进行初始化。引用表示一个变量的别名,对它的任何操作,本质上都是在操作它所表示的变量。
#include <stdio.h>
#include <stdlib.h>
#include <string>
int main()
{
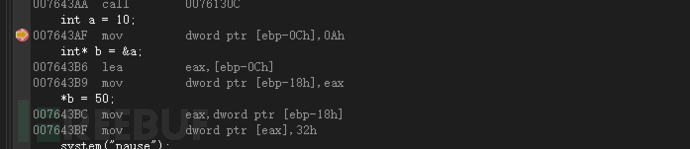
int a = 10;
int* b = a&;
*b = 50;
system("pause");
return 0;
}
这个就不多说了,实在没啥可说的,对比看一下就能明白了。
mov dword ptr [ebp-0Ch],0Ah //将16进制0Ah赋值给ebp-0Ch的地址 lea eax,[ebp-0Ch] //取ebp-0Ch地址放入到eax中 mov dword ptr [ebp-18h],eax //将 eax值放入到ebp-18h地址当中 mov eax,dword ptr [ebp-18h] //将ebp-18h地址中的内容放到eax寄存器中 mov dword ptr [eax],32h //将16进制32h放入到eax当中
引用类型跟指针的区别。
#include <stdio.h>
#include <stdlib.h>
#include <string>
int main()
{
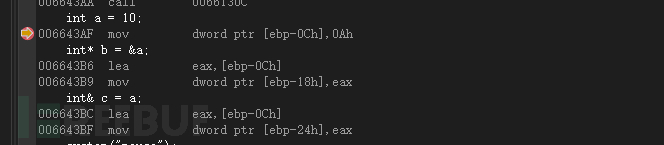
int a = 10;
int* b = &a;
int& c = a; //引用
system("pause");
return 0;
}可以看到指针是通过手动进行取地址,而引用它就是取地址,从汇编可以看没有区别,区别在于他们语法不一样,int* b = &a;是右边&取a的地址赋值给指针b,而引用是把一个变量传给了&c,但是&c引用时去取了变量a的地址。
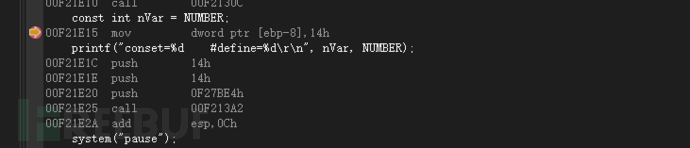
6、常量
#include <stdio.h>
#include <stdlib.h>
#define NUMBER 20
int main()
{
const int nVar = NUMBER;
printf("conset=%d #define=%d\r\n", nVar, NUMBER);
system("pause");
return 0;
}常量使用#define进行定义,下图可以看到在把常量赋值是直接将其值进行了赋值,它不像局部变量使用栈空间存放,在使用常量是它是直接调用地址。
#define与 const 的区别
#define | const |
编译期间查找替换 | 编译期间检查 const 修饰的变量是否被修改 |
由系统判断是否被修改 | 由编译器限制修改 |
字符串定义在文件只读数据区,数据常量编译为立即数寻址方式,成为二进制代码的一部分 | 根据作用域决定所在的内存位置和属性 |
三、总结
大家如果觉的哪里写的不好,或则哪里没写到,欢迎大家留言交流,互相进步。写这篇也是在进行总结,把会的知识点进行总结。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者