


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
写在前面
这是Hyper-V安全研究系列的第一篇。
初次接触虚拟化的安全研究者,如果要想对Hyper-V漏洞进行深入的分析利用或漏洞挖掘,首先需要对Hyper-V的体系结构有个清晰的认识,这样才能从宏观层面把握其通信过程、攻击面和漏洞成因等问题。但如果不了解虚拟化架构的技术发展过程,直接看Hyper-V体系结构的话,又很有可能一头雾水、没有头绪。
因此对于初学者而言,比较合适的学习路线是:虚拟化架构-->Hyper-V体系架构-->Hyper-V功能组件与技术实现-->漏洞分析与利用。
本篇先对虚拟化架构的技术发展进行全面总结,以便在后续研究中能快速熟悉Hyper-V的技术设计原理。
1.1 虚拟化的两种实现方式
之前一直对虚拟化的各种产品架构、容器等概念云里雾里,本质上是对虚拟化实现技术的理解还存在很大偏差。因此要想深入学习虚拟化架构,必须先把虚拟化理论层面的东西捋清楚。
首先要理解的一个概念就是,虚拟化是用来解决什么问题的?
虚拟化的本质就是解决如何充分利用硬件资源的问题。
我们都知道,操作系统的作用就是实现了对硬件资源的透明封装。如果想要运行某个应用程序,传统方法需要在一套硬件上部署一个操作系统,然后在操作系统中运行需要的应用程序。但如果想要批量运行多个不能在同一操作系统共存的程序,那就得需要部署多套硬件、安装多个操作系统。
对企业来说,上述传统方案的运维成本、时间成本都难以让人接受。并且随着近些年硬件性能的大幅提高,这种传统方式也对硬件资源造成了极大浪费。
迫于这种急切的现实需求,虚拟化技术应运而生。
那如何解决硬件资源浪费的问题呢?
首先就有人就提出:能否在一套硬件上面部署多个操作系统,然后在每个操作系统运行需要的应用程序呢?在这个思路下就逐渐产生了Hypervisor技术。
但也有人觉得,既然我们的最终需求是在同一套硬件上按需运行多个程序,而Hypervisor技术必须强制为每个程序另外多安装一个庞大的操作系统。很明显,通常情况下操作系统要比单个应用程序对硬件资源的性能消耗要大得多。那有没有可能在一个操作系统中直接按需运行多个本来不能共存的程序呢?在这种思路下就逐渐产生了容器技术。我们常说的Docker则是新一代容器技术解决方案的代名词。
注:传统的容器技术没有成为主流的原因是因为其未能提供标准化的应用运行时环境,而以Docker为代表的新一代容器技术则从一开始就以提供标准化的运行时环境为目标,真正做到“build once, run anywhere”,可以将同一个构建版本用于开发、测试、预发布、生产等任何环境,并且做到了与底层操作系统的解耦。
简而言之,为了解决同一个问题,Hypervisor采用的是硬件资源虚拟化的方法将硬件资源分配给不同的操作系统使用,而容器采用的则是操作系统虚拟化的方式实现了对程序运行环境和访问资源在操作系统内部的隔离。下图是Hypervisor和容器的技术栈对比:
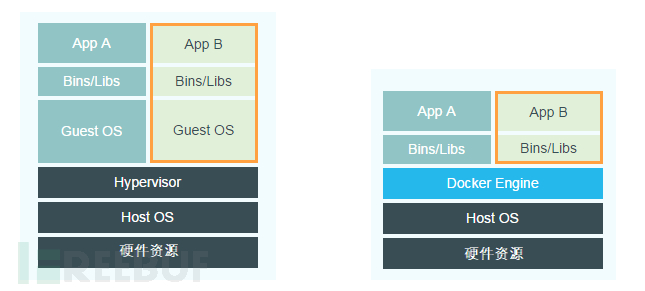
备注:Hypervisor、Host OS和硬件资源的层级关系并不一定是上图这种关系,后面会详细介绍。
显然Docker相比Hypervisor来说更加轻量化。但Docker的不同容器之间共用一个底层的操作系统,而Hypervisor的每个虚拟机都是一个完整的操作系统,因此Hypervisor相比容器来说对环境隔离得更彻底。
无论哪种虚拟化技术,从本质上来说,目的都是为了将应用程序所需的执行环境和资源隔离起来建立一个相互独立的虚拟环境。
1.2 Docker的技术原理
在学习Hypervisor技术之前,先简单讲解一下Docker的技术原理。相对于Hypervisor利用虚拟机实现运行环境和资源隔离的方案,Docker的解决方案就显得十分简洁。
Docker Engine可以简单地看成是基于 Linux 中的Namespace 、CGroups 和Union File System等技术实现的对进程运行环境和资源进行隔离的轻量级虚拟化方案。
备注:Docker For Windows实际上是运行在Linux虚拟机中,Windows并没有类似于Linux Namespace的原生隔离机制。
Docker采用的核心技术包括:
1.2.1 Namespace
Linux内置的Namespace机制实现了对进程可访问资源的隔离。它的主要目的就是实现轻量级虚拟化(容器)服务。在同一个 namespace下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,认为自己置身于一个独立的系统中,从而达到隔离的目的。
目前实现的Namespace包括:Control Group(CPU、块设备输入输出的隔离)、UTS(主机名和域名的隔离)、IPC(信号量、消息队列和共享内存的隔离)、PID(进程ID号命名空间的隔离)、Network(网络设备、网络栈、端口等的隔离)、Mount(文件系统的隔离)、User(用户和用户组的隔离)。
1.2.2 CGroups
上述Namespace只能为容器提供隔离功能,但是如果要实现对容器内进程的启停和物理资源的使用限制,就需要使用CGroups机制了。
简单来说,Namespace解决的是用什么的问题,CGroups解决的是用多少的问题。
CGroups全称Control Groups,是Linux下用来控制进程对CPU、内存、块设备I/O、网络等资源使用限制的机制。通过使用CGroups,可以实现为进程组设置内存上限、配置文件系统缓存、调节CPU使用率和磁盘IO吞吐率等功能,以及对进程组进行快照或者重启等功能。具体的资源控制器由不同的子系统完成:
cpuset:分配单独的CPU和内存。
cpu、cpuacct:CPU调度控制。
memory:设置内存限制。
devices:对访问设备的管控。
blkio:设置块设备的输入/输出。
net_cls、net_prio:标记网络数据包并设置网络接口的优先级。
freezer:实现进程组的暂停和恢复。
1.2.3 Union File System
Union File System主要是为了解决Docker镜像管理和存储的问题,核心是分层的概念。下面举个简单的例子来说明。
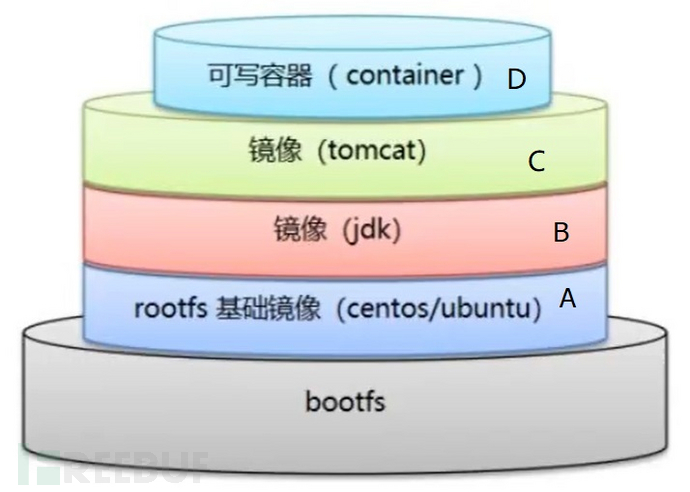
比如要为容器中的镜像B增加Tomcat变成镜像C,又基于镜像C创建了多个可读写的容器D1、D2...Dn。对于使用某个容器Dn的用户而言,Union File System就可以把A、B、C、D四者的不同文件系统和目录整合为一个统一的虚拟文件系统视图展示给使用者。
假设镜像B的bin文件夹中存在b.ini文件,镜像C在bin文件夹中增加了c.ini文件,那用户最终看到的bin文件夹就会同时存在b.ini和c.ini两个文件。
UFS中包含的具体技术与实现还包括:子镜像相对于父镜像的存储方式(增量存储)、Docker中的只读镜像和可读写容器之间的通信(写时复制CoW和用时配置)、Linux中的bootfs和rootfs、分多层AUFS还是分两层Overlay(只读层和读写层)或者块存储DeviceMapper等等。感兴趣的读者可以深入研究,这里不再赘述。
1.3 Hypervisor虚拟化技术
与驱动程序的设计有很多类似,传统的驱动程序解决的是不同进程访问同一硬件设备的问题,而Hypervisor解决的是不同OS访问同一硬件设备的问题。当然这中间还有许多细节需要考虑。
Hypervisor可以简单地理解为一个实现硬件资源虚拟化、负责虚拟机创建和配置的管理程序,也称之为Virtual Machine Monitor,简称VMM。其中硬件资源的虚拟化,本质上实现的是对CPU、内存和I/O设备(存储、网络、显示、输入等外设)三种硬件资源的虚拟化。
目前市面上主流Hypervisor虚拟化产品采用架构的不同,核心在于它们针对CPU、内存和I/O设备虚拟化技术实现方式的不同。因此我们首先看一下针对上述三种硬件资源的虚拟化发展过程。
从本质上来说:CPU虚拟化解决的是特权指令执行的问题,内存虚拟化解决的是虚拟地址与物理地址之间转换的问题,IO设备虚拟化解决的是物理设备访问的问题。
既然要访问硬件,就需要提供类似于驱动程序的硬件访问接口。这里就存在一个实现上的问题:Hypervisor管理程序是在自己的代码中集成驱动程序呢,还是直接使用原有操作系统内核本来就自带的驱动程序呢?如果选择直接使用现有操作系统中的驱动程序的话,Hypervisor就要提供虚拟机Guest OS访问宿主机Host OS驱动程序的通信机制。
类似上述问题的提出,也逐渐出现了不同的解决方法,最终也慢慢影响了Hypervisor的技术发展走向。简单来看,对CPU、内存、IO设备这三种硬件资源的虚拟化技术,大致都经历了纯软件全虚拟化、纯软件半虚拟化和硬件辅助虚拟化三个发展过程。
备注:这个描述不太精确,但能让读者对三种硬件虚拟化技术的发展有个全局性的认识。由于不同虚拟化产品对自身使用场景、兼容性等定位的不同,目前不同的虚拟化产品中针对每种硬件资源的全虚拟化、半虚拟化、硬件辅助虚拟化技术都或多或少有所体现,并不能理解为简单的前后替代关系。
下面具体来看一下CPU、内存和IO设备三种硬件资源虚拟化的实现方式。
1.3.1 CPU虚拟化
1. 纯软件全/半虚拟化
我们都知道,计算机的体系结构是基于分层设计的。为了减轻应用程序的负担,操作系统通过驱动程序的方式负责了对硬件资源的直接访问。应用程序只能通过系统调用告诉操作系统自己想要访问哪个硬件,而由操作系统内核的驱动程序发起真正的硬件访问。
硬件访问本质上是硬件中断请求。对硬件来说,操作系统和应用程序在自己眼里都是访问者而已。硬件只关心是谁发送了硬件中断请求到自己的接口上,而不关心到底是操作系统还是应用程序发出的。那如何控制只让操作系统访问硬件,而不让应用程序直接访问呢?也就是如何控制硬件的访问权限呢?在CPU体系结构中,人们提出了CPU指令特权级别的概念来解决这个问题。具体我们通过Intel的CPU体系结构来讲解一下。
Intel在设计上将CPU运行级别分为4个特权级别:Ring0、Ring1、Ring2、Ring3。常见的Windows/Linux操作系统在实现上只使用其中的Ring0和Ring3两个级别。操作系统内核运行在Ring0,应用程序运行在Ring3。
简单来说,只有Ring0特权级别的指令可以直接访问硬件资源,而Ring3不行(Ring3的应用程序直接发起硬件访问指令就会导致CPU异常)。如果Ring3的应用程序想访问某个硬件,就要通过使用Ring0的操作系统提供给Ring3应用程序的系统调用,使得CPU的运行级别从Ring3切换为Ring0,然后由Ring0内核代码完成对硬件的访问。访问完成后再由Ring0切换为Ring3,将结果返回给Ring3的应用程序。这就是用户态和内核态之间切换的本质。
设置特权级别的本质目的就是,控制不同的访问者(应用程序和操作系统)对硬件资源的访问。同样,Hypervisor本质上也是为了解决不同的访问者(虚拟机和Hypervisor管理程序)对硬件资源访问权限的问题,因此虚拟化的实现本质上也使用了特权级别的思想。
从实现上来说,最理想的方式就是,将Hypervisor管理程序作为一个对硬件资源具有直接访问权的小型化操作系统,由其负责对硬件资源的直接访问,上层的虚拟机不能直接访问硬件资源,而只能通过调用接口或CPU异常的方式告诉Hypervisor管理程序。
这里可以简单地理解为Hypervisor管理程序(VMM)运行在Ring0特权级别,而上层的虚拟机运行在Ring3特权级别。虚拟机Guest OS在VMM眼里只是个应用程序而已,它的权限等价于原本宿主机的Ring3应用程序。但我们都知道,虚拟机Guest OS本身就是个操作系统,它自己也分为内核和用户层两个级别。为了方便理解,我们这里把虚拟机的两个特权级别称之为Ring3'和Ring0'。由于虚拟机整体都是只拥有Ring3权限而已,虚拟机内核的Ring0'以为自己是高权限的Ring0,但实际上自己只是个Ring3。
因此CPU虚拟化的本质就是,解决Ring3层虚拟机操作系统(包含Ring3'和Ring0')到Ring0特权级别切换的问题。具体来看又涉及到Ring3'和Ring0’两个特权级别的分别处理,下面我们来逐步分析一下如何实现Ring3'和Ring0'的虚拟化。
这里根据上层的虚拟机指令架构与底层Hypervisor管理程序指令架构的不同,需要分为宿主机指令架构和虚拟机指令架构相同(比如都是x86或都是ARM架构)和宿主机指令架构和虚拟机指令架构不同(比如宿主机是x86架构而虚拟机时ARM架构)两种情况。指令架构不同时,只能通过类似于指令翻译的方式将上层指令架构翻译为底层指令架构,这里不再详述。下面具体看一下指令架构相同的情况。
Ⅰ. 指令模拟
这里分别看一下虚拟机中的Ring3'和Ring0'两个特权级别的运行情况。
Ring3':如果宿主机指令架构和虚拟机指令架构相同的话,由于虚拟机本身就运行在Ring3级别,因此Ring3'指令的运行权限本质上和Ring3没有任何区别,直接将这部分指令交由CPU执行即可。
Ring0':由于Ring0'的真实权限是Ring3,因此这时候Ring0'直接访问硬件资源的特权指令就会出现问题了。由于Ring0'访问硬件资源的特权指令自身权限不对,在Ring3特权级别下直接使用Ring0特权级别的指令,产生了指令越权,此时CPU就会产生一个指令异常。
我们都知道,Hypervisor管理程序(VMM)运行在Ring0特权级别。因此VMM要做的就是,截获(intercept)这个CPU异常,然后在自己这一层(真正的Ring0权限)模拟(virtualize)这条越权指令的运行。也就是说,你Ring0'想执行特权指令,但你实际上没有Ring0权限。而我VMM有Ring0的权限。我就可以等CPU产生异常后,帮你把特权指令执行了。整个过程对于Ring3级别的Ring0'是透明的,它还以为是自己真正执行的。这个过程就有点类似于异常消息处理机制。
这就是最初实现CPU虚拟化的思路:指令模拟。也叫做Trap-and-Emulation。
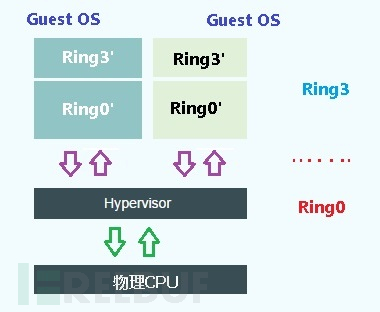
Ⅱ. 特殊敏感指令的处理
按照常规理解,访问硬件资源的敏感指令都应该只允许在Ring0中运行,这部分也叫做特权指令,比如MIPS、PowerPC的架构就是这样设计的。对于上述架构特权指令的虚拟化,我们只需要让虚拟机执行特权指令从而产生CPU异常,然后在VMM捕获模拟执行,最后返回结果就可以了。
但x86架构在设计上比较“坑”,有部分访问敏感资源的指令在Ring3的权限下就能执行,也就是说这部分指令在执行的时候并不会触发CPU异常。因此对于这部分特殊敏感指令的虚拟化,没法通过Trap机制被Hypervisor管理程序捕获,也就没法通过指令模拟的方式执行了。
而在虚拟机架构下,又不能直接运行这部分特殊的敏感指令在Ring3'特权级别下直接执行,否则多个虚拟机同时运行同一个访问资源的敏感指令,如果不加以限制,肯定会出问题的。
那怎么解决这个问题呢?个人认为解决这个问题的关键在于,首先要理解产生问题的根源。问题的根源就是,x86架构中有部分特殊的敏感指令可以直接在Ring3特权级别下执行,而PowerPC或MIPS就没有这类特殊的敏感指令,也就不存在这个问题。因此解决问题的核心就在于,想办法让VMM能够捕获到这类特殊的敏感指令。要么让这类特殊的敏感指令直接进入到Ring0级别执行(改变执行环境),要么想办法在执行前就修改这类特殊的敏感指令使其能够被VMM捕获模拟(改变指令逻辑)。上述两种方法最终都是为了解决x86架构中普通指令、特殊敏感指令、特权指令和Ring3、Ring0两种特权级别之间不一一对应的问题。
各大厂商就这个问题各自提出了自己的解决方案。
改变指令逻辑:VMWare公司提出了一种Binary Translation二进制代码翻译的转换技术,它可以提前发现这类特殊的敏感指令并通过插入特殊的断点来截获,然后交由VMM来解释执行。
改变执行环境:Xen提出了另外一种全新的思路来解决这个问题,也就是著名的Hypercall。直接修改虚拟机操作系统,将包含特权指令和特殊敏感指令在内的所有敏感指令都改为通过系统调用的方式切换到VMM直接处理。Hypercall本质上是为虚拟机提供了直接进入Ring0特权级别的系统接口,可以简单地理解为使得虚拟机内部的特权指令和特殊敏感指令具备了真实的Ring0权限。VMM提供给上层虚拟机的接口就叫做Hypercall API,它类似于操作系统中的系统调用概念,本质上都是为了实现Ring3与Ring0特权级别之间的切换。
通常把Trap-and-Emulation指令模拟称之为纯软件全虚拟化,Hypercall API调用称之为纯软件半虚拟化。
根据实现原理可以看出,Hypercall半虚拟化省略了VMM程序捕获和模拟的过程,更接近于物理执行效率,因此要比指令模拟全虚拟化效率上快很多。
纯软件全虚拟化技术中又根据针对虚拟机和宿主机架构是否相同,分为解释执行(全部指令都模拟)、代码扫描与修复(只模拟特权指令,其它指令交给CPU直接执行)等。
Hypercall机制的出现,不仅使x86架构指令的全虚拟化得以实现,也为后续内存虚拟化和I/O设备虚拟化提供了全新的实现思路,后面会详细描述。
2. 硬件辅助虚拟化
通过上面CPU虚拟化的技术发展可以看出,由于操作系统在实现上内核直接运行在Ring0特权级别,而虚拟化架构下理论上只能让Hypervisor管理程序运行在Ring0特权级别,这就导致虚拟机内核与Hypervisor管理程序的特权级别产生了冲突。因此才需要采用指令模拟的方式,由Hypervisor管理程序帮助虚拟机内核执行特权指令。另外,由于x86架构存在的虚拟化缺陷,允许部分敏感指令在Ring3特权级别下执行,导致指令模拟并不能捕获到所有的敏感指令,虚拟化厂商只能通过程序修补的方式才能实现x86指令的全虚拟化。
是不是感觉很混乱?这种混乱的本质在于,虚拟机的操作系统内核在设计上默认自己肯定会运行在Ring0特权级别上。但是在虚拟机架构下,正确的特权级别从底层到上层应该是:VMM-->虚拟机内核态-->虚拟机用户态。我们都知道,操作系统的Ring0和Ring3是通过2bit的I/O Privilege Level特权级别标志位(IOPL)来实现的(共0、1、2、3四个标志),并且二者分别占据了0和3两个极端标志位,这就导致了根本没办法从硬件标志位上来标记VMM的存在。
那怎么解决虚拟化架构下权限等级的问题呢?既然没空余的了,那只能另起炉灶再增加一个标志位了。因此Intel和AMD就通过增加一个1bit硬件标志位的方式来支持虚拟化功能,这个标志位称之为虚拟化标志位。其中,数值0是root根模式,代表自身处于物理机状态;数值1是non-root非根模式,代表自身处于虚拟化状态。
由此可知,正是由于IOPL特权级别标志位和虚拟化标志位的共存,才使得root和non-root模式下都可以运行操作系统,也就是大家常说的每种模式都有ring0-3四个特权级别。
在硬件辅助虚拟化中,只有root模式才能执行涉及全局的敏感指令,non-root模式下执行特权指令和特殊敏感指令都会触发一个VM-EXIT操作,使得CPU切换到root模式,此时VMM就可以进行处理。由此可以看出,原本Trap陷入的概念实际上被硬件所支持的VM-EXIT操作取代了,它表示了从非根模式退出进入到根模式。
硬件辅助虚拟化为每个虚拟机提供了一个或者多个虚拟CPU(简称vCPU)的抽象。每个vCPU分时复用物理CPU。在任意时刻一个物理CPU只能被一个vCPU使用,VMM要在整个过程中合理分配时间片以及维护所有vCPU的状态。这里所说的vCPU状态维护其实就是vCPU的上下文切换,而vCPU的环境结构主要由硬件和软件两部分组成。
软件部分主要由VMM控制,主要包括vCPU的状态信息、浮点寄存器等。硬件部分指的是Intel和AMD用来描述和保存vCPU状态信息的内存空间,它们分别存放在被称为虚拟机控制结构VMCS(Virtual-Machine Control Structure)和虚拟机控制块VMCB(Virtual-Machine Control Block)的数据域中,VMCS和VMCB都是最大不超过4KB的内存块。
在进行vCPU上下文切换的时候,要涉及硬件部分和软件部分两方面。
简单来说,原本需要Trap陷入的软件操作变成了由硬件支持的VM-Exit操作,然后再由VMM管理程序配合硬件芯片组完成特权指令的执行。当然,虚拟机控制结构中也标记了哪些指令能够触发VM-Exit操作。因此,之前那些无法触发CPU异常的特殊敏感指令也能够通过VM-Exit进入根模式了。
也就是说,x86架构下CPU的硬件辅助虚拟化本质上解决了两个问题:①特权指令的捕获交给硬件来实现;②特殊的敏感指令也可以直接被硬件捕获。加入硬件虚拟化的VMM处理逻辑更加简洁,执行效率大大提高。这种用硬件方式的解决思路就是现在我们耳熟能详的Intel VT-x和AMD-V技术的由来。
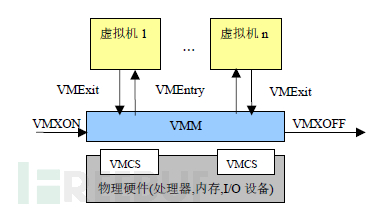
Intel实现的基于x86架构的硬件虚拟化辅助技术Intel VT其实包括CPU、内存和IO三方面的虚拟化技术。针对CPU的技术具体包括安腾架构的VT-i和x86架构的VT-x。具体的实现细节包括:VMM可以通过Intel增加的VMXON、VMXOFF指令控制硬件辅助虚拟化技术的开关。虚拟机从非root模式进入root模式称之为VMExit,反之称之为VMEntry,并且用VMCS数据结构保存了每个虚拟机的状态信息和控制信息。AMD的硬件辅助虚拟化与之类似。
个人觉得,无论是软件虚拟化还是硬件辅助虚拟化,搞懂CPU虚拟化的关键在于,理解所有敏感指令(包括特权指令)必须要在Ring0特权级别(或根模式)下执行这一本质要求。
1.3.2 内存虚拟化
传统操作系统的内存管理,解决的是虚拟地址(Host Virtual Address)到物理地址(Host Physical Address)转换的问题(避免了不同进程之间内存访问冲突),这个内存管理单元就叫做MMU。而在虚拟化架构下,Guest OS可以简单地理解为宿主机Host OS中的一个进程,它使用的所有内存地址本质上都是宿主机的虚拟地址(Host Virtual Address)。
我们都知道,Guest OS也是一个完整的操作系统,它的内部同样存在虚拟地址(Guest Virtual Address)和物理地址(Guest Physical Address)。当然,二者本质上都只是宿主机的虚拟地址。
上面这种出现的内存现状和CPU虚拟化中的Ring3'和Ring0'十分类似。因此,内存虚拟化本质上就是要解决虚拟机中的虚拟地址GVA到宿主机中的物理地址HPA转换的问题。
按照常规思路,要想实现GVA到HPA的转换,简单来说,就要经过GVA-->GPA-->HVA-->HPA的三步转换。在一个虚拟机启动以后,它自身就以宿主机的一个进程存在。因此上述转换中的GPA和HVA在虚拟机启动时就完全确定了,因此上面的过程就可以简化为GVA-->GPA-->HPA的两步转换。
如何实现这两步转换呢?根据采用软件实现还是硬件实现的不同,就出现了下面两种解决思路。
1. Shadow Page Table
我们都知道,CPU的MMU内存管理单元维护着操作系统某个进程的HVA到HPA的映射表。由于GPA实际上就是HVA,因此这个表也就可以作为GPA到HPA的映射表。
在GVA-->GPA-->HPA三者的两步转换中,后面的GPA-->HPA可以直接通过MMU硬件单元实现。这时候就有人想,既然MMU本质上存储的就是一个内存地址到另一个内存地址的映射关系,那能否一步到位,直接建立一张GVA到HPA的映射表存储到MMU单元中呢?这就是影子页表技术Shadow Page Table。
影子页表建立好后,直接将GVA-->GPA-->HPA两步转换变成了GVA-->HPA一步转换。这个技术实现的关键在于,需要提前计算出GVA到HPA的映射关系(GVA到HPA需要经过多层转换)并存储到MMU中,这个过程由VMM管理程序具体负责。
具体的实现过程如下:
起初,在MMU存储的GVA到HPA的映射表是空的。当Guest OS想通过MMU单元把GVA地址转换为HPA地址时,由于找不到HPA就会产生缺页异常。此时VMM就会intercept(截获)这个虚拟机产生的内存访问异常,然后通过软件算法将GVA经过多层转换得到HPA物理地址,并将GVA到HPA的映射表存入MMU中。下次Guest OS再访问这个GVA虚拟内存时,就可以直接从MMU中读取得到对应的物理地址HPA了。
由于Guest中的每个进程都有自己的虚拟地址空间,这就意味着VMM要为Guest中的每个进程都维护一套对应的影子页表。当 Guest中的进程访问内存时,才能将该进程的影子页表装入MMU单元,完成地址转换。
因此,虽然这种方式减少了地址转换的次数,但本质上还是需要VMM经过复杂的多层转换才能实现,VMM承担了太多影子页表的维护工作,效率受到了很大的影响。
有人可能会有疑问,上面的影子页表不就是把GVA和HPA的映射表存入MMU,这不就是硬件的实现方式吗?这种片面的理解是没有意识到GVA是动态产生的这一本质。Guest OS的内存寻址过程绝大多数时间实际都消耗在了VMM把GVA转换为HPA这一软件实现过程上了。
为了改善这个问题,就有人提出了基于硬件实现的内存虚拟化方案,将上述这些繁琐的工作都交给硬件来完成。这就是著名的EPT技术。
2. Extened Page Table
既然内存虚拟化的本质是GVA-->GPA-->HPA的两步转换,操作系统在实现上,本来就会把第一步的GVA到GPA的映射表存入到MMU内存管理单元,那再想办法把GPA到HPA的映射表存入MMU中,到具体的内存寻址时,只需要在硬件逻辑上实现这两种表的关联就可以了。这就是EPT技术的实现原理。
由于每个Guest OS虚拟机启动时自身的GPA到HPA的映射关系就确定了,因此直接可以把GPA到HPA的映射表载入到MMU中,然后当Guest OS的每个进程启动时再把GVA到GPA的映射表载入到MMU。这里GVA到GPA的映射称之为CR3页表,GPA到HPA的映射称之为EPT页表。
具体实现上还包括:最初EPT表为空时,先产生缺页异常由VMM捕获,然后VMM为GPA分配一个HPA地址再更新EPT表等细节,有兴趣的同学可以详细了解。
由上可知,EPT页表将GVA-->GPA-->HPA两步转换都变成了硬件实现,效率比影子页表大大提升。可以看出,内存虚拟化的技术发展也经历了由软件辅助虚拟化SPT技术到硬件辅助虚拟化EPT技术的进化,效率也越来越高。
1.3.3 IO设备虚拟化
I/O 虚拟化在虚拟化技术中算是比较复杂,也是最重要的一部分。从整体上看,I/O 虚拟化也包括基于软件的虚拟化和硬件辅助的虚拟化。软件虚拟化又可以分为全虚拟化和半虚拟化。如果根据设备类型再细分的话,又可以分为字符设备 I/O 虚拟化(键盘、鼠标、显示器)、块设备 I/O 虚拟化(磁盘、光盘)和网络设备 I/O 虚拟化(网卡)等。
与CPU和内存虚拟化类似,要想弄懂IO虚拟化的原理,也需要从根源上了解IO设备虚拟化碰到的实际问题。
首先看一下,在没有虚拟化的情况下,操作系统是如何进行IO 设备请求的。
我们都知道,根据分层设计的思想,操作系统通过驱动程序的方式控制了对所有硬件资源的直接访问。如果某个用户态进程要想访问某个硬件,只能通过调用内核提供的驱动程序接口,由驱动程序将具体的硬件中断请求发送给相应的设备,最后再将结果返回给用户态进程。
那在虚拟化架构下,上述过程又是怎样的呢?虚拟机的用户态进程发起驱动程序接口的调用后,虚拟机内核的驱动程序理论上此时也会发出具体的硬件中断请求。但问题就在这里,硬件中断请求本质上是一个进行IO读写的特权指令,而虚拟机本质上只是一个Ring3权限的进程,特权级别的不匹配就会导致CPU异常。另外,如果同时有两个虚拟机发出对同一硬件的IO指令,这也会出现同步的相关问题。
如果你已经熟悉了CPU虚拟化的本质,可以看出,IO设备虚拟化遇到的问题,本质上也是虚拟机内核在实现上的Ring0特权级别与实际具备的Ring3特权级别不匹配的问题。解决的思路也很简单,就是需要提供在虚拟化架构下Ring3特权级别到Ring0特权级别切换的方法。
1. 纯软件全虚拟化
参考CPU虚拟化的做法,最简单的方法就是,由VMM管理程序截获虚拟机的IO设备请求,然后在Ring0特权级别下的Hypervisor层模拟完成硬件设备的访问就可以了。这也保证了只有Hypervisor层可以对所有硬件资源进行直接访问。
但这里会存在一个十分棘手的问题,访问硬件设备是需要驱动程序支持的,如果想要让Hypervisor做到对所有硬件资源的直接访问,就需要在Hypervisor层为每一种硬件设备都实现对应的驱动程序。这种在Hypervisor层加入驱动程序的方式无疑会大大增加Hypervsior管理程序的代码量,维护成本未免也有些太高了。不过,生活总是一分为二的。VMWare ESXi就是这么实现的,把需要的所有驱动程序都封装进了Hypervisor管理程序。
那有人就想,既然现在设备驱动程序都已经很成熟了,能否让Hypervisor层直接复用宿主机上的驱动程序呢?VMM截获虚拟机的IO设备请求后,将其直接转发给宿主机的驱动程序接口。这种在虚拟机和宿主机驱动程序之间充当桥梁的设备仿真方式,也称之为设备模型。
上面两种方法的区别在于,直接访问IO设备的驱动程序到底运行在哪个层级。直接运行在Hypervisor层,避免了与宿主机之间的中转,性能较好,但需要维护大量的第三方驱动程序;如果运行在宿主机操作系统,Hypervisor代码会大大减少,但需要将硬件中断请求转发至宿主机操作系统,上下文切换必然带来性能的降低。
当然,二者的共同点在于都是通过截获的方式来处理虚拟机的IO指令的,因此它们都称之为IO设备的软件全虚拟化。下面着重看一下通过设备模型的IO虚拟化示意图。
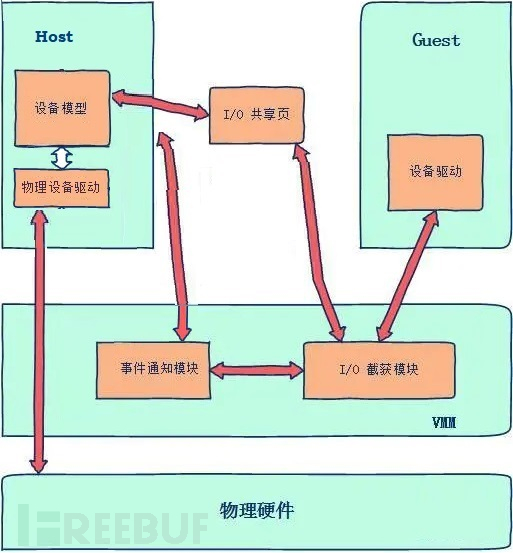
备注:在很多全虚拟化的实现中,VMM是作为宿主机的一个内核模块存在的。因此上图的Host实际上很可能包含VMM层,这里只是为了清晰地表达中转流程,才将它们拆分表示。
由于设备模拟的复杂性,为降低VMM内核模块的复杂性,设备模型通常在用户层实现。
VMM管理程序在截获虚拟机的硬件访问请求后,会通过事件通知模块提交给用户层的设备模型进程进行处理。设备模型可以直接模拟后返回结果,也可以调用宿主机的设备驱动接口,发起对硬件的访问。
可以看出,这种软件全虚拟化的方式,需要为虚拟机中的每个IO设备提供对应的设备模型。
优点:完全不需要修改虚拟机操作系统。虚拟机认为自己在“直接”使用物理I/O设备,但实际上全是虚拟化出来的。
缺点:设备模拟和转换过程需要经过多次不同特权级别之间的上下文切换,造成了巨大的性能开销。
2. 纯软件半虚拟化
既然我们的本质目的是将虚拟机的硬件访问请求发送到宿主机中的设备驱动,而全虚拟化的上下文切换会造成了巨大的性能开销,那能否设计出一种直接让虚拟机和宿主机直接通信的数据传输机制呢?这种思路就产生了IO设备半虚拟化技术。
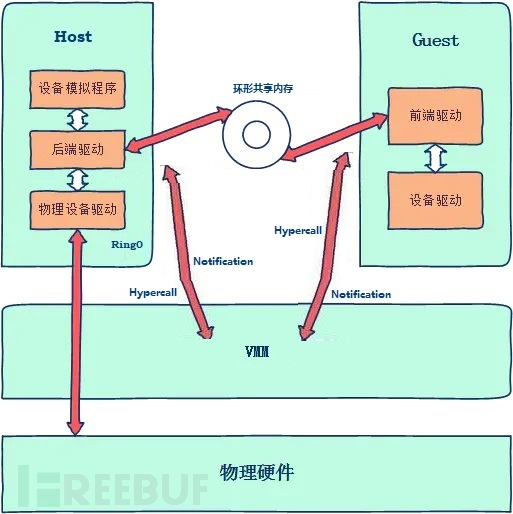
半虚拟化的主要改进在于:①虚拟机和宿主机直接通过环形内存的方式实现内存共享,避免了数据在虚拟机、VMM和宿主机之间的多次中转;②利用Hypercall API和中断机制将硬件访问请求从虚拟机传递给宿主机,避免了基于捕获模拟的多次上下文切换。
要想实现Hypercall和中断机制,就必须对虚拟机和宿主机的代码进行修改。具体的做法是,在虚拟机增加前端驱动模块、在宿主机增加后端驱动模块。
前端驱动:将虚拟机驱动程序发起的硬件访问请求更改为Hypercall调用接口,将硬件访问所需的数据写入到环形共享内存后通过Hypercall告诉VMM管理程序,由VMM管理程序通过中断机制通知宿主机。
后端驱动:接收到虚拟机发送过来的硬件访问请求,读取环形共享内存的数据,然后调用真正的驱动程序接口,最后再利用Hypercall的方式由VMM来通知虚拟机本次设备请求已完成。
由于半虚拟化的方式能够避免VMM截获模拟造成的多次特权级别上下文切换,相比全虚拟化来说性能有了很大的提升。但这种方式需要修改虚拟机内核,为IO设备(网卡、硬盘、键盘等)分别提供一对前端驱动和后端驱动。目前一个比较好的开源实现就是virtio,从Linux 2.6.30 版本开始就被集成到了 Linux 内核。Hyper-V也实现了类似的半虚拟化机制。
注意:一开始误以为半虚拟化是在虚拟机和宿主机之间直接通过某种进程间的传输机制进行通信的,完全不需要VMM管理程序的参与,这是十分错误的理解。
半虚拟化架构下的虚拟机和宿主机也不能直接进行交互,必须经过VMM的控制,否则会出现平行越权的问题。这也是为什么存在Hypercall的缘故。
理解半虚拟化的关键在于,搞清楚控制消息和数据内容二者不同的通信流程。VMM管理程序负责的是Control,环形内存负责的是data。后面在Hyper-V中会详细介绍这一点。
3. 硬件辅助虚拟化
虽然半虚拟化相比全虚拟化性能有了很大的提升,但终归还是软件实现的方式,性能上还是和直接访问物理 I/O 设备有很大的差距。因此在虚拟化的发展过程中,就逐渐出现了通过硬件辅助解决设备虚拟化问题的解决方案。根据不同虚拟机之间是否可以共享同一个设备的区别,这里主要介绍Passthrough和PCIe IO-V两种思路。
Ⅰ. Passthrough
最初人们想到的方法是,如果能够让某个虚拟机独占一个物理设备(比如显卡),就像宿主机一样使用物理设备,这种方式的性能无疑是最好的。这就是设备直通Device Passthrough技术。
设备直通要求VMM管理程序为不同的虚拟机按需分配物理设备,并在该虚拟机使用期间提供对其它虚拟机的隔离,也就是阻止其它虚拟机对该设备的访问。
可以采用的方法是,在拥有设备的guest VM加载对应的驱动程序前,先给要分配出去的设备加载一个伪驱动作为占位符。由于没有真正的驱动程序,这个设备对于其他的guest VM来说就相当于是隐藏的了。
但由于虚拟机必须独占设备的特性,也暴露了device passthrough存在的一个问题,就是同一个I/O设备通常无法在不同的guest VM之间实现共享和动态迁移。
另外,Passthrough在实现上还需要考虑内存地址转换的问题。
对于一个外设而言,外界对它的操作从本质上来说无非就是以下两点:①把外设的数据读入内存;②或者把内存的数据传送到外设。也就是外设和内存之间的数据传输问题。
最传统的解决方法是,CPU先将外设的内容拷贝寄存器,再由寄存器存储到内存中。这个过程导致CPU一直被占用着。因此人们就设计了DMA机制。通过在在外设和内存之间直接架设DMA硬件通道,使得外设和内存可以直接进行数据传输,而不需要CPU的介入,节约了CPU时间。
这在传统操作系统中没有什么问题,但由于DMA机制中外设和内存的地址都是使用的HPA物理地址,而Guest OS中的驱动程序去操作外设时使用的是GPA地址。因此在硬件辅助的设备虚拟化中,还需要解决外设和内存各自的GPA到HPA的地址转换问题。
外设对操作系统而言本质上也是一段内存地址。通过前面内存虚拟化的介绍,我们可以采用EPT技术来解决外设GPA-->HPA的转换问题。当然也可以采用EPT技术来解决内存地址GPA-->HPA的转换问题。但我们要注意的是,在DMA架构中,是由外设通过DMA engine发起对内存的访问,而不是由CPU发起的。因此此时针对CPU的MMU内存管理单元在硬件设计上就需要有所调整,因此就出现了IOMMU内存管理单元。
IOMMU单元是架设在DMA和内存之间的内存管理单元,主要解决的是将外设发起访问的虚拟内存地址转换为物理内存地址的问题。
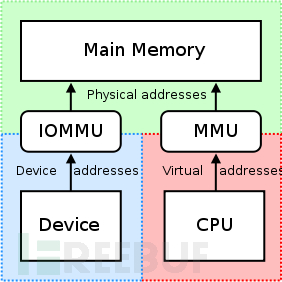
Intel将这种硬件辅助的 I/O 虚拟化技术叫做 VT-d(Virtualization Technology for Direct I/O),AMD叫做IOMMU。后起之秀的 ARM 自然也不甘示弱,推出了对应的SMMU(System MMU)。
总结来看,Passthrough的实现难点在于:①设备独占;②内存地址转换。Passthrough本质上是通过硬件辅助的方式为Guest OS提供了直接进行敏感资源访问的能力(可以简单地理解为Ring3的虚拟机直接具备了Ring0的部分权限)。因此实现不当很有可能出现严重的越权问题。
这里举个例子。
如果某个虚拟机Guest OS独占了某个自身带有固件的SSD硬盘或显卡设备,就可以利用Passthrough技术直接从虚拟机内部为设备升级一个自定义的恶意固件。后续如果这个设备被其它虚拟机使用,那后果可想而知。
再进一步想,如果这个设备具备DMA功能,那设备内部的固件理论上就具备了直接操作物理内存的能力,也就可以通过DMA直接修改宿主机上的内存,这就很有可能造成严重的虚拟机逃逸。
因此IOMMU还要解决对内存资源访问的隔离,防止DMA随意操作物理内存。这就是IOMMU中的DMA remapping技术。
DMA Remapping:通过IOMMU页表方式将直通设备对内存的访问限制在特定的虚拟机domain范围,提高IO性能的同时完成了直通设备的隔离,保证了直通设备DMA的安全性。
另外设备直通还需要考虑中断如何处理的问题。如果外设产生一个中断,如何告诉虚拟机呢?有人可能会问,既然虚拟机都独占设备了,设备的中断不能直通到虚拟机内部吗?当然不行,因为中断是Ring0特权级别,虚拟机是Ring3特权级别。要解决直通设备的中断处理问题,人们就提出了Interrupt remapping和Interrupt posting两种方法。
Interrupt remapping:将中断先发送给宿主机再由宿主机转发给虚拟机。由IOMMU截获硬件中断,先将中断映射到host的某个中断上,然后再由VMM投递重定向到Guest内部。
Interrupt posting:在Interrupt Remapping的基础上进一步提升了直通设备的中断处理效率。使用Posting模式时,vCPU可以直接在non-root模式下处理中断而不会被vm-exit到VMM管理程序。
尽管 Passthrough 直通技术消除了虚拟机 I/O 中 VMM 干预引起的额外开销,但在 I/O 操作中 I/O 设备会产生大量的中断。出于安全等因素的考虑,虚拟机无法直接处理中断,因此中断请求需要由VMM路由至合适的虚拟机。所以在实际使用过程中,Passthrough都是软硬件虚拟化方式结合实现的。
Ⅱ. SR-IOV
Passthrough技术固然提高了性能,但同时只能一个虚拟机独占一个硬件设备,虚拟机之间无法共享。对于大规模虚拟化来说,这是个很大的问题。那能否像CPU虚拟化提出的虚拟vCPU一样提出vDevice的概念,让每个虚拟机可以分时复用物理设备呢?
为了解决这个问题,使一个物理设备能被更多的虚拟机所共享,学术界和工业界都对此作了大量的改进。
PCI-SIG协会发布了 SR-IOV (Single Root I/O Virtualizmion) 规范,详细阐述了硬件供应商在多个虚拟机中共享单个 I/O 设备硬件的标准。SR-IOV 标准定义了设备原生共享所需的软硬件支持。
硬件支持包括:芯片组对 SR-IOV 设备的识别,为保证对设备的安全、隔离访问,还需要北桥芯片的 VT-d 支持。为保证虚拟机有独立的内存空间,要支持IOMMU。
软件支持包括:VMM将驱动管理权限交给Guest,Guest操作系统必须支持SR-IOV功能接口。
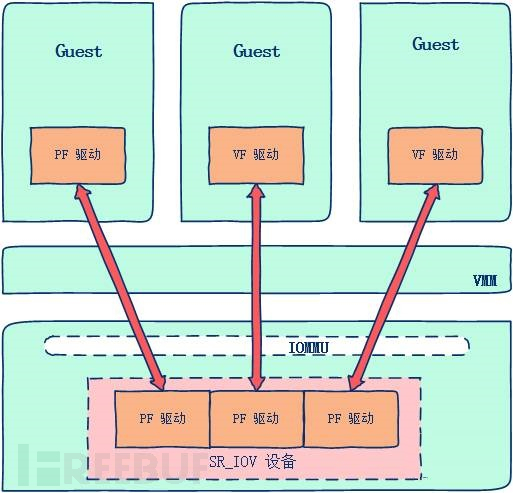
SR-IOV 单独引入了两种软件实体功能:
PF(physical function):包含轻量级的 PCIe 功能,负责管理 SR-IOV设备的特殊驱动,其主要功能是为 Guest 提供设备访问功能和全局贡献资源配置的功能。
VF(virtual function):包含轻量级的 PCIe 功能。其功能包含三个方面:向虚拟机操作系统提供的接口;数据的发送、接收功能;与 PF 进行通信,完成全局相关操作。
每个SR-IOV设备都有一个物理功能PF,并且每个PF最多可有64000个与其关联的虚拟功能VF。
Guest 通过物理功能 PF 驱动发现设备的 SR-IOV 功能后,将包括发送、接收队列在内的物理资源依据 VF 数目划分成多个子集,然后 PF 驱动将这些资源子集抽象成 VF 设备。这样,VF 设备就可以通过某种通信机制分配给虚拟机了。
简单来说,SR-IOV标准使得物理设备可以按需划分为多个虚拟vDev设备供上层虚拟机使用(通过VF接口),底层的PF驱动保证了逻辑上对物理设备的分时复用。
1.4 Hypervisor主流产品架构
通过上面的介绍,相信大家对Hypervisor虚拟化技术有了大概的了解。下面我们依托这些技术原理看一下市面上主流虚拟化产品的主要架构。
1.4.1 架构分类
目前主流的虚拟化产品包括VMWare ESXi、KVM、Xen、Hyper-V、Virtualbox、VMWare Workstation等,可以从多个维度对这些产品进行分类。
| 分类标准 | 分类 |
|---|---|
| 虚拟化层次 | 软件虚拟化、硬件辅助虚拟化 |
| 是否修改虚拟机操作系统 | 全虚拟化、半虚拟化 |
| 宿主平台 | 裸金属架构、宿主架构、混合型架构 |
| 应用领域 | 服务器虚拟化、网络虚拟化、存储虚拟化、应用程序虚拟化等 |
这些分类没有严格的界定,一个优秀的虚拟化产品往往融合了多项技术。这里着重需要了解的是,根据Hypervisor所依赖的宿主机平台的不同,虚拟机架构主要分为裸金属架构(Ⅰ型)和宿主架构(Ⅱ型)两种类型。
1. 裸金属架构
作为Hypervisor层的VMM虚拟机管理程序直接运行在物理硬件之上。
Hypervisor 将负责管理所有的硬件资源和虚拟环境支持。无论是宿主机还是虚拟机操作系统,都是作为Hypervisor上层的虚拟机存在的。
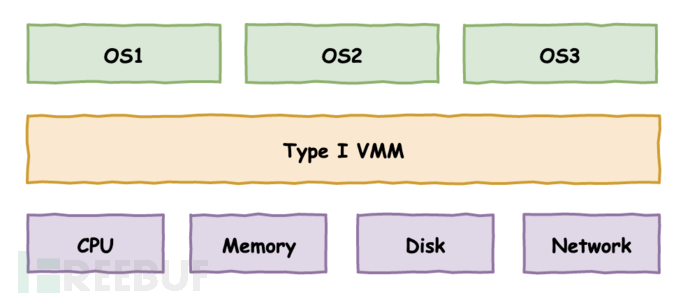
在该架构中,VMM可以看作一个为虚拟化而生的微型操作系统,掌控所有的物理资源(CPU、内存、I/O 设备)。VMM向下承担了管理物理资源的重任,向上负责为虚拟机提供资源的使用。
裸金属架构最特别的一点是,需要负责硬件设备的管理,说简单点就是VMM需要为硬件提供驱动程序。那怎么提供呢?通过前面对IO设备半虚拟化技术的讨论,我们知道,根据驱动程序所在层级的不同,出现了两种解决方法:
① 把驱动程序直接封装在VMM层。VMM完全是一种单内核的操作系统,称之为monolithic。由于硬件设备多种多样,VMM不可能把所有的设备驱动程序都封装进来,所以这种方法只支持有限的设备。
② 仍旧调用宿主机操作系统的驱动程序接口。VMM提供专门的前后端驱动作为Host OS和其它Guest OS的桥梁。设备访问由宿主机的驱动程序负责,VMM只负责CPU和内存的虚拟化。VMM以一种精简的微内核方式存在,称之为microkernelized。
2. 宿主架构
Hypervisor层的VMM管理程序是宿主机操作系统的一部分,通常作为内核的一个独立模块存在(具体实现还包含一些用户态进程,比如负责 I/O 虚拟化的用户态设备模型等)。
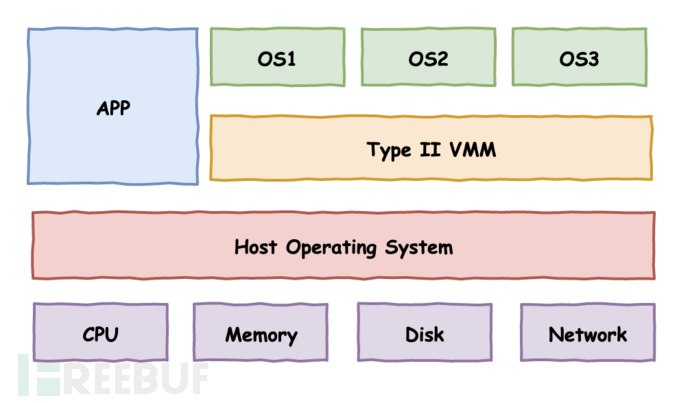
在这种架构下,物理资源由Host OS直接管理。实际的虚拟化功能由VMM提供。VMM 通过调用 Host OS 的服务来获得资源,从而实现CPU、内存和IO设备的虚拟化。通常VMM创建的每个虚拟机,分别作为宿主机的一个进程参与调度。
具体来说,VMM 模块负责 CPU 和内存虚拟化,硬件请求会发送给Host OS的设备驱动来实现 I/O 设备的虚拟化。这样就可以充分利用现有宿主机的设备驱动程序,轻松实现 I/O 设备的虚拟化。但因物理资源受 Host OS 控制,VMM 需调用 Host OS 的服务来获取资源进行虚拟化,其效率会受到一定的影响。
3. 混合型架构
在区分裸金属架构和宿主架构时,可能有人认为VMM直接访问硬件设备的应该属于裸金属架构,由宿主机操作系统负责设备访问的应该属于宿主架构。
VMM负责CPU、内存和IO设备的虚拟化。但有的VMM在实现上,VMM只负责 CPU 和内存的虚拟化,I/O 设备的虚拟化由 VMM 和特权 OS 共同完成。也有人把这种架构称之为混合型架构。
其实也不用纠结分类的问题。分类就是个给人看的东西,理解不同产品的具体实现才是关键。
下面从技术实现上大致介绍一下几款主流虚拟化产品的主要架构。
1.4.2 主流产品
1. VMWare ESXi
VMWare ESXi是单内核的裸金属架构。设备启动后,先加载hypervisor组件VMKernel,由它负责所有的硬件资源和后续的虚拟机调度。
其中,CPU和内存的虚拟化直接在VMKernel内部实现。CPU虚拟化借助了Intel的VT-x和AMD的AMD-V硬件辅助虚拟化,内存虚拟化借助了Intel EPT和AMD NPT的硬件辅助虚拟化。
对于I/O设备的访问,则支持多种方式。
① 利用IOMMU硬件辅助虚拟化(Intel VT-d和AMD-Vi)的Passthrough技术,使得虚拟机可以直接访问硬件设备,从而减少了CPU的开销。
② 利用半虚拟化的方式。设备的物理驱动封装在VMKernel中,虚拟机中装载设备的虚拟驱动,通过二者配对实现物理设备的访问,与设备模型相比有着较高的效率。半虚拟化设备的安装是由虚拟机中的 VMware tool来实现的。
ESXi的物理驱动是内置在Hypervisor中的,所有设备驱动均是由VMware预植入的。因此,ESXi对硬件有严格的兼容性列表,不在列表中的硬件,ESXi将拒绝在其上面安装。
2. Hyper-V
Hyper-V是微内核的裸金属架构。下面是它的体系架构示意图。
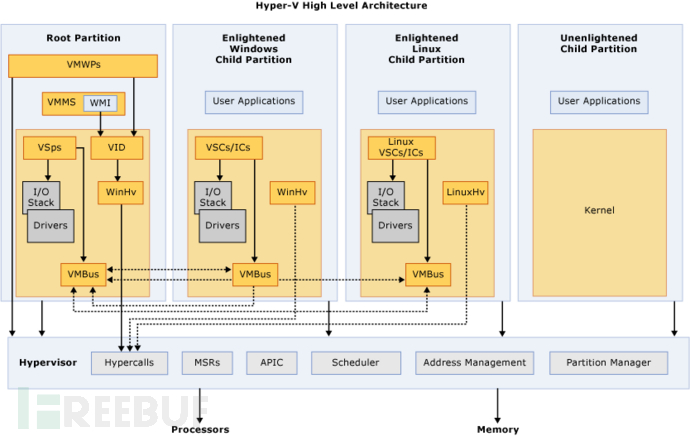
服务器启动后,Hyper-V的Hypervisor就接管了对整个硬件设备的控制权。先前的宿主机也成为了Hyper-V的首个虚拟机,称为父分区root partition,负责其它子分区child partition虚拟机的创建和I/O设备的管理。
Hyper-V要求CPU必须具备硬件辅助虚拟化。Hypervisor层的VMM管理程序仅实现了CPU的调度和内存的分配,而由父分区操作系统控制着I/O设备的实际访问。因此,父分区的操作系统实际上是一个具备特权的虚拟机,被Hypervisor完全信任。
Hyper-V同时支持IO设备的全虚拟化和半虚拟化方式。在半虚拟化的实现上,Hyper-V通过为子分区虚拟机增加了一种虚拟化服务客户端VSC的前端驱动、为父分区操作系统增加了一种虚拟化服务提供者VSP的后端驱动,并设计了一种VMBus虚拟总线通道机制,实现了子分区虚拟机和父分区操作系统之间的数据传输。
大致过程如下:如果子分区虚拟机要访问I/O设备,需要先通过虚拟机内核的VSC组件发起访问请求。VSC请求经由VMBus虚拟总线(通过一种环形内存的共享机制)传递给父分区的VSP组件,再由VSP将请求重定向到真实的物理驱动实现硬件的访问。
半虚拟化模式下的每一种IO设备均需要有一对对应的VSC和VSP模块,如存储、网络、视频和输入设备等。微软为虚拟机提供的VSC模块叫做集成服务,比如为Linux虚拟机提供的LIS集成服务。
但如果子分区的操作系统没有安装或者无法支持 Hyper-V集成服务包(比如较旧的操作系统),那这个子分区就只能运行在全虚拟化状态下。微软把这种支持半虚拟化驱动的操作系统称之为Enlightened,把不支持的称之为Unenlightened。Unenlightened的虚拟机只能通过VMM管理程序捕获和模拟的全虚拟化方式实现IO设备的虚拟化。
3. Xen
另外单独提一下Xen开源架构。可以说Hyper-V的设计思路有很大一部分来自于Xen。
Xen也是微内核的裸金属架构,它比Hyper-V支持更广泛的CPU架构。Xen的半虚拟化不需要强制开启硬件辅助虚拟化的要求,并且半虚拟化在实现上也是提供了一种XenBus的通信机制。Xen的Hypervisor层代码也非常少,不包含任何物理驱动,物理驱动全部放在Dom 0的特权虚拟机中。
但由于IO设备的半虚拟化需要修改虚拟机内核,因此在早期,Windows虚拟机不能再Xen架构下以半虚拟化的方式运行,只能以效率较低的全虚拟化方式运行。这也为后来Windows的Hyper-V发力赶超Xen埋下了伏笔。
Hyper-V相比Xen支持Windows虚拟机的IO设备半虚拟化,而KVM又比Xen更加精简且被纳入到了Linux内核。正是由于Hyper-V和KVM的双重冲击,才最终导致了Xen的日渐没落。
3. KVM
KVM是基于Linux内核的宿主架构。
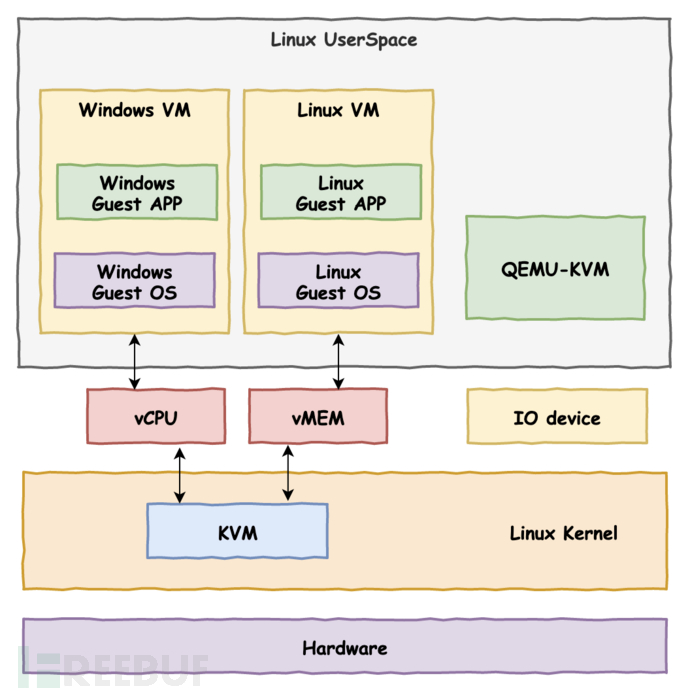
KVM作为一个 Hypervisor,只是以一个内核模块kvm.ko的方式存在于Linux内核。它自身只负责CPU调度和内存管理两方面,而将IO设备的虚拟化交给了Linux内核和用户态的QEMU来完成。
KVM支持广泛的CPU架构,它充分利用了CPU的硬件辅助虚拟化能力,并重用了Linux内核的诸多功能来实现虚拟化调度。因此KVM的代码量非常小。可以简单理解为,KVM把整个Linux内核转换成了一个底层的裸金属Hypervisor操作系统。因此,也有人称它为半裸金属架构。
KVM架构包含两部分:
① kvm内核模块,负责CPU和内存的虚拟化、虚拟机的管理。
② QEMU用户层模块,用于模拟虚拟机的用户空间组件,提供IO设备模型负责IO设备的虚拟化。
一个普通的 Linux 内核有两种执行模式:内核模式(Kernel)和用户模式 (User)。为了支持带有虚拟化功能的 CPU,KVM 向 Linux内核增加了第三种模式即客户机模式(Guest),该模式对应于CPU的non-root mode。Linux本身运行于内核模式,主机进程运行于用户模式,虚拟机则运行于客户模式。使得转变后的Linux内核可以将主机、进程和虚拟机三者进行统一的管理和调度。
KVM利用修改的用户态的QEMU为虚拟机提供了BIOS、显卡、网络、磁盘控制器等的仿真,但对于IO设备(主要指网卡和磁盘控制器)来说,这种全虚拟化的方式必然带来性能低下的问题。因此,KVM也引入了半虚拟化的设备驱动。通过虚拟机操作系统中的虚拟驱动与主机Linux内核中的物理驱动相互配合,可以提供近似原生设备的访问性能。从这里也可以看出,KVM所支持的物理设备也就是Linux能够支持的物理设备。
由于KVM架构的精简,很快就被纳入了linux内核原生支持。目前很多云产品都以KVM做底层架构,发展也越来越迅速。
目前主流的云厂商中,AWS底层主要使用的是KVM,微软Azure使用的是Hyper-V,VMWare使用的是ESXi,Google主要使用的是KVM和基于容器技术的Kubernetes。国内的华为云、腾讯云和阿里云则都是分别基于Openstack(底层是Xen和KVM)架构根据需求自行改进的。
1.5 总结
前后大约花了一周多的时间,才把这些虚拟化架构的理论知识梳理完,有一种豁然开朗的感觉。
之前看Hyper-V体系架构时,一直不知所云,无法深入理解VMBus为何要这样设计。现在回想来看,问题就出在对Hypervisor虚拟化技术的原理没有做到真正的融会贯通。
虽然花费了大量时间,但经过这些内容的铺垫,对后续学习Hyper-V的体系架构提供了坚实的理论基础。
参考
本篇内容参考了公众号cloud_dev《虚拟化基础系列》相关文章和下列网络资源:
《云虚拟化安全攻防实践》
完。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者