


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
这次属于趁热打铁,学完unlink以后,我们会发现unlink并不是完美的。而且unlink也在一步一步的完善,我们就来看一下基于unlink的堆溢出漏洞
远古版本的unlink
我们需要了解一下远古版本的unlink和如今的unlink有什么不一样
// 由于 P 已经在双向链表中,所以有两个地方记录其大小,所以检查一下其大小是否一致(size检查)
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) \
malloc_printerr ("corrupted size vs. prev_size"); \
// 检查 fd 和 bk 指针(双向链表完整性检查)
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
// largebin 中 next_size 双向链表完整性检查
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr (check_action, \
"corrupted double-linked list (not small)", \
P, AV);
引用了一下CTFwiki上面的代码。我们可以发现比较重要的几个:chunksize(P) != prev_size (next_chunk(P)FD->bk != P || BK->fd != PP->fd_nextsize->bk_nextsize != P||P->bk_nextsize->fd_nextsize != P
这就是现如今的unlink使用的检查,但是远古版本没有这样的检查。那么我们再看一下unlink使用了什么样的操作,用一张图一目了然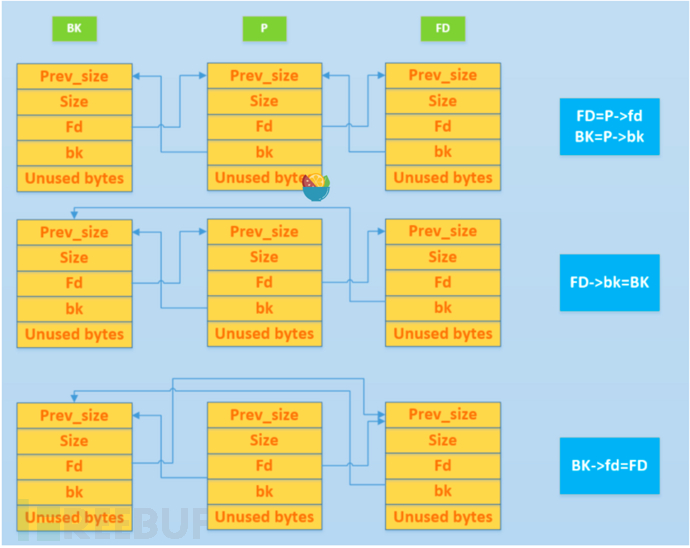
我们假设脱链的chunk被称为P,用代码表示脱链过程很简单:P->fd->bk=P->bk,P->bk->fd=p->fd
但是如果存在堆溢出漏洞,我们又可以做什么手脚呢?先上图
先解释一下,chunkQ是使用中的chunk,并且存在溢出漏洞,而P是free状态下的chunk,当我们使用free释放chunkQ,chunkQ会检查它的高地址相邻的chunk,也就是P(这里默认都是smallchunk),发现P处于free状态,就会进行合并。合并的时候会先将P脱链,然后与Q合并。那么此时我们的Q有堆溢出,我们填写数据一直溢出到P的fd和bk指针,并且将两个指针进行改写。
我们可以看到,chunkP的fd指针已经被改为addr-12,bk指针改写为了except value。这是两个最重要的地方
注:addr指你想往哪里写入内容,except value表示你想写入什么内容
那么现在脱链的时候就变成了P->addr-12->bk=p->bk,P->except value->fd=P->addr-12
那么问题来了,为什么要减12?而且addr-12并不一定是chunk头,为什么也会有指针?
解释:这里我们假设它是一个32位操作系统(举一反三,64位就是减去24)。我们人看来addr-12并不一定是chunk头,但是对于计算机来说,一个fd指针指的地方它就是chunk头。而且在底层方面,不存在指针这个东西,指针是C语言的,而编译为计算机能看懂的语言后,指针本质上就是偏移。那么我们就能知道了,P->fd->bk本质上就是寻找P的高地址chunk头,并且向高地址再偏移3个标准字长就是bk了。也就是说P的nextchunk的bk指针在计算机看来就是P->addr-12+12。这下就知道为什么要使用addr-12了
然后我们继续,根据上面的解释,我们就可以直接进行一波等量代换:P->addr=except value,P->except value+8=P->addr-12。很明显,except value+8地址需要写入内容,所以需要excrpt+8地址是可写的,否则程序就会崩溃。
这样我们通过堆溢出实现了任意地址写
现代版本的unlink
现在的unlink宏添加了检查语句P->fd->bk != P || P->bk->fd != P(后面的检查是基于largechunk,其实一个道理,这里我们先不考虑)
添加了这一句话以后我们看一下之前的那个溢出P->fd=addr-12,P->bk=except value,很明显这个就过不去检查语句了P->addr!=except value,P->except value+8!=P->addr-12。但是这个真的是天衣无缝的吗?其实并不是,正所谓上有政策下有对策,通过检查语句的源码我们也可以想到如何欺骗检查。我们只要构造的值比较精妙,就可以绕过这个检查了。
首先我们看这个检查语句的真正含义就是想让我们P->fd->bk==P&&P->bk->fd==P。那么我们现在想出这么一种方式P->fd->bk=*(addr-12+12)=P&&P->bk->fd=*(except value+8)=P。然后我们就可以得出了P的fd和bk指针分别应该赋予什么值了:addr=&P-12&&except vlaue=&P-8=addr-8。这样我们成功绕过了检查,但是很明显我们这就不属于任意地址写了,并且我们构造的地址还需要可写权限。这样虽然加了很多限制,但是至少在一定程度上依旧可以通过栈溢出改写一些内容。
这是基于堆溢出的unlink漏洞,在现在的unlink有检查的情况下,只有某些时候可以利用,当然我们主要是学习这么一个思想,还有就是要在计算机的角度上思考一个问题
- 0 文章数
- 0 关注者