


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
1. PIP的定位
企业ABAC中访问控制机制的部署实施有几个重要的功能“点”,用于检索和管理策略的服务节点,其中包含了用于处理策略上下文或工作流、以及检索和评估属性的一些逻辑组件。下图给出了这些功能点:策略执行点(PEP)、策略决策点(PDP)、策略信息点(PIP)和策略管理点(PAP)。这些组件处于同一环境中,相互配合以实现访问控制决策和策略执行。
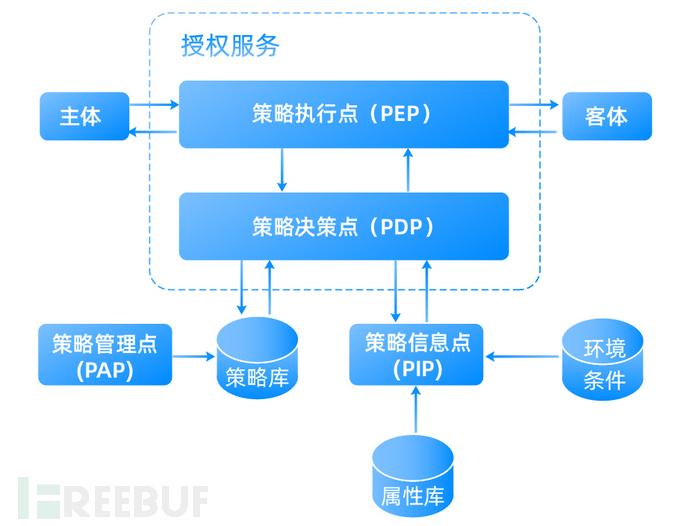
策略决策点(PDP):通过评估适用的DP和MP来计算访问决策。PDP的主要功能之一是根据MP调节或消除DP间的冲突。
PEP执行PDP做出的策略决策:
策略执行点(PEP):以执行策略决策的方式响应主体对受保护客体的访问请求;访问控制决策由PDP生成。
PDP和PEP功能可以是分布式的或集中式的,并且可以在物理和逻辑上彼此分离。例如,企业可以建立一个集中控制的企业决策服务,该服务评估属性和策略,生成策略决策并传递给PEP。这种方式方便对主体属性和策略进行集中管理和控制。或者,企业内的本地组织可以利用集中的DP存储库,实现独立的PDP。ACM组件的设计和部署需要一个管理单元来协调ABAC的各组件功能。
要计算策略决策,PDP必须具有有关属性的信息,这些信息由PIP提供。本文件中的PIP定义为:
策略信息点(PIP):作为属性或策略评估所需数据的检索源,提供PDP做出决策所需的信息。
在执行这些策略决策之前,必须对它们进行彻底的测试和评估,以确保它们满足预期的需要,这些功能由PAP执行。PAP可定义为:
策略管理点(PAP):提供一个用户接口,用于创建、管理、测试和调试DP和MP,并将这些策略存储在适当的策略库中。
2. PIP的定位及关键点思考
- PIP应属于支撑平台的一个组件,不直接面向客户
- PIP能统一的处理各方面的数据,当数据源和PIP对接时,尽量减少数据源的改动,降低对数据源的要求,而把主要工作负荷都放到PIP里
- PIP的工作不是简单的收集存储数据源的属性,而应该具备数据清洗,关联,统计分析并产生新的属性的能力
- 数据源和PIP的分工边界:数据源需要上报只有其才可以拿到的固有属性,比如:账号,IP,设备码,运行的软件,打开的端口等,不建议让数据源上报复杂的统计分析类属性,比如:1小时登录的次数,是否运行了违规软件,登录过的地点等。PIP在接收数据源上报的基础属性以后,可以对属性进行加工,关联,并通过运算产生如上新的属性
- 未来PIP占用系统资源数量级会远超系统其他模块
3. 典型流程
PIP系统处理流程等同于典型的ETL数据处理流程,先从各种数据源收集各种数据,再通过统一的数据处理流程,将多维度的数据统一过滤整合,最后统一存储,一个标准的流程架构(PIP)如下图:
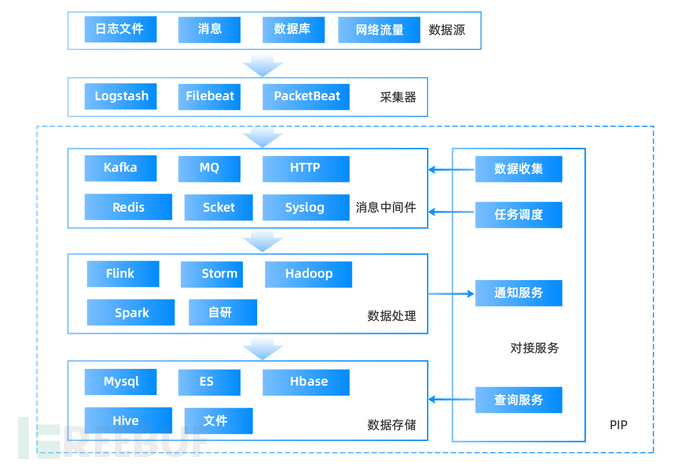
- 其中消息中间件,数据处理,数据存储均可以分离部署,并均可采用分布式部署。
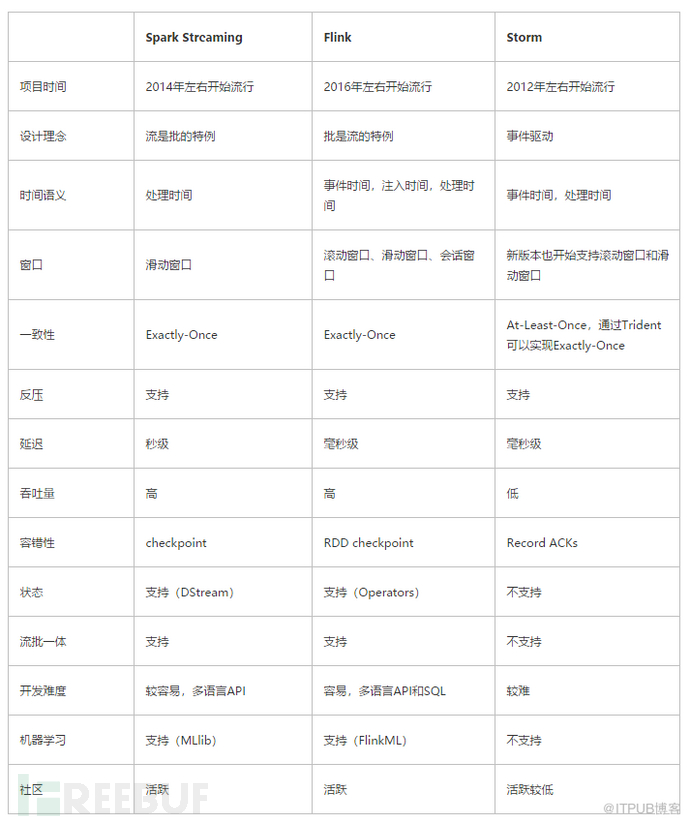
- 数据处理部分通常是根据不同的业务选用不同的处理方式,目前业界综合使用最多的是基于Flink的流式处理。目前基于文件的处理框架(比如hadoop+hbase)不太流行了,流式处理框架里主流的flink相对比storm具备更好的吞吐量(也就是性能更好),并且自身支持批处理及状态记录,这些优势导致其目前成为流式处理的主流框架,具体如下图(比较重要指标是:延迟,滑动窗口,吞吐量,状态,流批一体)
- 数据存储方面,目前业界综合使用最多的是ES,或ES结合某个列式存储数据库比如Hbase,或文档数据库比如mangoDB。Es结合其他数据库的方式只用于海量数据的查询检索,如果数据量未到该量级(比如单次查询的数据量约小于1亿条记录)则无需这么做
4. PDP和PIP对接
PDP和PIP对接可以采用2种对接方案,如下图:
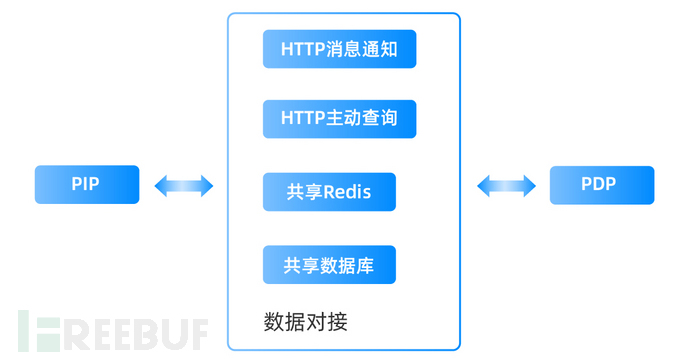
- HTTP主动通知结合HTTP主动查询,即PIP计算出最新的数据后主动通知PDP,或PDP需要用到某些属性时主动找PIP查询。该方式实时性较好,但会严重降低PDP乃至整个系统的性能,不推荐。
- 共享Redis结合共享数据库,PIP运行时会把数据在数据库和Redis里都存放一份,数据库和Redis均为异步更新,数据库更新周期远大于Redis。PDP启动后从数据库或Redis加载数据到自己内存,并周期性从Redis更新数据到内存,决策过程中只读内存。该方案优势在于性能较高,但PDP实时性会降低,推荐该方案。
5. 总结
- 基于目前的资源分配情况及需要处理的数据量,暂时无需额外引入其他开源框架(比如flink或其他文档数据库),这些开源框架本身也要占用系统资源,在数据量并不大的情况下反而会导致资源占用不均衡(比如框架占用了4g内存,本身处理只占用2g内存)
- 该方案内所涉及功能组件已经在实际使用,经过了长期运行证明可以适应目前的业务,而从零开发性价比太低并且没有任何业务驱动。
- 该方案已经实现了数据的统一收集,过滤,分析统计,存储等一系列流程,并且可以实现灵活配置处理规则(业界大多数做法都是写死的)实现了和pdp的闭环对接,在数据量并不大的情况下无需引入新的流程。
- 未来如果数据量大到一定程度则可以在该架构上持续改造(比如把flink结合进来)
注意,这种改造的好处是可以将PDP和PIP分离,分不同的进程甚至部署到不同的服务器上,但在目前硬件资源有限的情况下没有实际意义,这么配置会带来2方面负面作用:
A,虽然PDP的资源占用大幅减少,但其一大半工作被PIP分担,PIP同样会占用硬件资源,启动2个服务肯定比单个服务占用更多的资源,同时增加了额外的数据交互开销(比如原来用户信息和设备信息等直接通过登录请求携带过来,但流程分离后需要在PIP里单独开启用户和设备数据同步流程)。
B,本来PDP和PIP在一个进程全部读写内存效率最高,分离后至少也要用Redis做数据同步,处理性能和实时性两者必有一个会严重下降。
综合评估,大数据处理是建立在大量硬件资源的前提上,采用硬件换取效率,在资源不够的情况下,整个系统还是交互越少效率越高。
- 0 文章数
- 0 关注者