


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
随机生成的输入虽好,但是大多数在语法上是不成立的,因此很快就会被处理程序拒绝掉。为了能让模糊测试有效的进行下去,我们必须增加获得有效输入的几率。基于变异的模糊测试就是这样的一种方法,即对现有输入进行小的更改,这些更改可能仍使输入保持有效,但仍会表现出某些新的行为。在本节中我们一起学习如何创建此类变异,以及如何使用流行的AFL核心概念来引导它们发现新的路径。
先决条件
读者需要对基本的模糊测试结构与过程有所了解(可向前翻看第二章)
基于变异的模糊测试引擎
2013年11月,发布了第一版的American Fuzzy Lop(AFL)。从那时起,AFL已成为最成功的模糊测试工具之一,并具有很多分支,例如AFLFast,AFLGo和AFLSmart(以后将进行讨论)。AFL使模糊测试成为自动漏洞检测的流行选择,它也是第一个被证明可以在许多对安全性要求很高的真实应用程序中,能够自动检测到漏洞的方法。
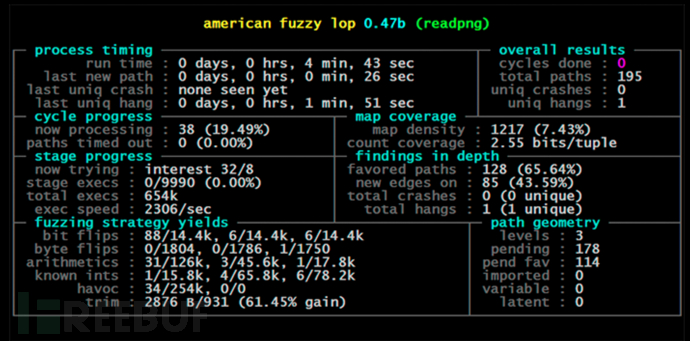
在本章中,我们将介绍变异模糊测试的基础,接下来的下一章将进一步展示如何将模糊测试引导到特定的代码目标。(定向型模糊测试)
对URL解析器进行模糊测试
许多应用程序限定其输入用非常固定的格式,这样才能正常执行后面的功能。例如让我们考虑一个接受URL地址(Web地址)的程序,其接受的url必定要采取有效的格式(即合规的url),以便程序可以正常的处理它。但如果我们采用前几章创建的完全随机生成输入的模糊测试引擎,我们能生成有效url的可能性有多大?
为了深入探讨这个问题,让我们一起探讨一下正常url的组成:
scheme://netloc/path?query#fragment
scheme:指的是所使用的协议,常见的包括http,https,ftp,file...
netloc:是要连接的主机的名称,例如www.google.com
path:是在目标主机上的路径,例如search
query:是键/值对的列表,例如q=fuzzing
fragment:是检索到的文档中某个位置的标记,例如#result
在Python中,我们可以使用该urlparse()函数来解析URL并将其分解为各个部分。
import bookutils
try:
from urlparse import urlparse # Python 2
except ImportError:
from urllib.parse import urlparse # Python 3
urlparse("http://www.google.com/search?q=fuzzing")
ParseResult(scheme='http', netloc='www.google.com', path='/search', params='', query='q=fuzzing', fragment='')
我们将看到结果如何将URL的各个部分编码为不同的属性。
现在让我们假设有一个使用URL作为输入的程序。为简化起见,我们不会让它有太多功能。我们只是让它检查传递的URL的有效性。如果URL有效,则返回True;否则,将引发异常。
def http_program(url):
supported_schemes = ["http", "https"]
result = urlparse(url)
if result.scheme not in supported_schemes:
raise ValueError("Scheme must be one of " + repr(supported_schemes))
if result.netloc == '':
raise ValueError("Host must be non-empty")
# Do something with the URL
return True
现在让我们开始对http_program()进行模糊测试。为了模糊,我们使用全系打印的ASCII字符,这样:,/和小写字母都包括在内。
from Fuzzer import fuzzer
fuzzer(char_start=32, char_range=96)
'"N&+slk%h\x7fyp5o\'@[3(rW*M5W]tMFPU4\\P@tz%[X?uo\\1?b4T;1bDeYtHx #UJ5w}pMmPodJM,_'
让我们尝试对1000个随机输入进行模糊测试,看看我们能否取得成功。
for i in range(1000):
try:
url = fuzzer()
result = http_program(url)
print("Success!")
except ValueError:
pass
获取实际有效的url概率有多大?我们需要以http://或者https://开头的字符串。先来看一下http://的情况:这是七个确定的字符,随机产生这七个字符(字符范围为96个不同字符)的概率是96的7次方分之一,或者表示成
96 ** 7
75144747810816
产生https://的概率更加糟糕,是96的8次方分之一:
96 ** 8
7213895789838336
这样综合一下可能性就是
likelihood = 1 / (96 ** 7) + 1 / (96 ** 8) likelihood
1.344627131107667e-14
那我们平均每产生一条符合上述条件的合格的url所需运行次数就是
1 / likelihood
74370059689055.02
我们来简单衡量一下运行http_program()一次需要多长时间
from Timer import Timer
trials = 1000
with Timer() as t:
for i in range(trials):
try:
url = fuzzer()
result = http_program(url)
print("Success!")
except ValueError:
pass
duration_per_run_in_seconds = t.elapsed_time() / trials
duration_per_run_in_seconds
6.241764600008537e-05
看起来非常的快,不是吗?不幸的是,算上可能的运行次数,结果就比较惊人了。
seconds_until_success = duration_per_run_in_seconds * (1 / likelihood) seconds_until_success
4642004058.676655
转化为
hours_until_success = seconds_until_success / 3600 days_until_success = hours_until_success / 24 years_until_success = days_until_success / 365.25 years_until_success
147.09623224442464
即使我们并行并发,我们仍需要等待数月至数年的时间,就为获得一次成功的样例生成,这基本上和空跑没什么区别。
只要我们不能产生有效的输入,我们就无法达到任何更深层次的功能,也更谈不上测试功能性和安全性了。
变异的输入
与从头开始生成随机字符串的方法不同,变异是指从给定的有效输入开始,然后对其进行变异操作(突变)。一个突变,在这种情况下是一个简单的字符串操作:比如,插入一个(随机)字符、删除字符,或一个字符的表示翻转了一下。这被称为变异模糊测试**-与之前讨论的生成模糊测试技术相反。
以下是一些可以帮助入门的变异方法:
import random
def delete_random_character(s):
"""Returns s with a random character deleted"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
# print("Deleting", repr(s[pos]), "at", pos)
return s[:pos] + s[pos + 1:]
seed_input = "A quick brown fox"
for i in range(10):
x = delete_random_character(seed_input)
print(repr(x))
'A uick brown fox' 'A quic brown fox' 'A quick brown fo' 'A quic brown fox' 'A quick bown fox' 'A quick bown fox' 'A quick brown fx' 'A quick brown ox' 'A quick brow fox' 'A quic brown fox'
def insert_random_character(s):
"""Returns s with a random character inserted"""
pos = random.randint(0, len(s))
random_character = chr(random.randrange(32, 127))
# print("Inserting", repr(random_character), "at", pos)
return s[:pos] + random_character + s[pos:]
for i in range(10):
print(repr(insert_random_character(seed_input)))
'A quick brvown fox' 'A quwick brown fox' 'A qBuick brown fox' 'A quick broSwn fox' 'A quick brown fvox' 'A quick brown 3fox' 'A quick brNown fox' 'A quick brow4n fox' 'A quick brown fox8' 'A equick brown fox'
def flip_random_character(s):
"""Returns s with a random bit flipped in a random position"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
c = s[pos]
bit = 1 << random.randint(0, 6)
new_c = chr(ord(c) ^ bit)
# print("Flipping", bit, "in", repr(c) + ", giving", repr(new_c))
return s[:pos] + new_c + s[pos + 1:]
for i in range(10):
print(repr(flip_random_character(seed_input)))
'A quick bRown fox' 'A quici brown fox' 'A"quick brown fox' 'A quick brown$fox' 'A quick bpown fox' 'A quick brown!fox' 'A 1uick brown fox' '@ quick brown fox' 'A quic+ brown fox' 'A quick bsown fox'
现在让我们创建一个随机变异器,它随机选择要应用的变异规则:
def mutate(s):
"""Return s with a random mutation applied"""
mutators = [
delete_random_character,
insert_random_character,
flip_random_character
]
mutator = random.choice(mutators)
# print(mutator)
return mutator(s)
for i in range(10):
print(repr(mutate("A quick brown fox")))
'A qzuick brown fox' ' quick brown fox' 'A quick Brown fox' 'A qMuick brown fox' 'A qu_ick brown fox' 'A quick bXrown fox' 'A quick brown fx' 'A quick!brown fox' 'A! quick brown fox' 'A quick brownfox'
现在的想法是,只要开始时有一些有效输入,则可以通过应用上述突变之一来创建更多输入候选,让我们回到URL上。
URLs变异
现在让我们回到我们的URL解析问题,创建一个函数is_valid_url()来检查http_program()是否接受输入。
def is_valid_url(url):
try:
result = http_program(url)
return True
except ValueError:
return False
assert is_valid_url("http://www.google.com/search?q=fuzzing")
assert not is_valid_url("xyzzy")
现在让我们在给定的URL上应用该函数mutate(),并查看获得了多少有效输入。
seed_input = "http://www.google.com/search?q=fuzzing"
valid_inputs = set()
trials = 20
for i in range(trials):
inp = mutate(seed_input)
if is_valid_url(inp):
valid_inputs.add(inp)
现在我们可以观察到,通过对原始输入进行变异可以得到很大一部分的有效输入:
len(valid_inputs) / trials
0.8
通过变异http:样本种子输入来产生https:前缀的几率是多少?我们必须在正确的位置(1:l)插入 (1:3)正确的字符‘s’(1:96),平均下来概率需要运行的次数应该是
trials = 3 * 96 * len(seed_input) trials
10944
这个运行的量级我们应该可以承担,我们试试吧:
from Timer import Timer
trials = 0
with Timer() as t:
while True:
trials += 1
inp = mutate(seed_input)
if inp.startswith("https://"):
print(
"Success after",
trials,
"trials in",
t.elapsed_time(),
"seconds")
break
Success after 3656 trials in 0.011846093000258406 seconds
当然,如果我们想获得一个"ftp://"前缀,我们将需要更多的变异和更多的运行次数—但最重要的还是需要应用多个变异。
多种变异
到目前为止,我们仅对样本字符串应用了一个突变。但是,我们也可以应用多个突变,以进一步对其进行更改。例如,如果我们在样本字符串上应用20个突变,会发生什么情况?
seed_input = "http://www.google.com/search?q=fuzzing" mutations = 50
inp = seed_input
for i in range(mutations):
if i % 5 == 0:
print(i, "mutations:", repr(inp))
inp = mutate(inp)
0 mutations: 'http://www.google.com/search?q=fuzzing' 5 mutations: 'http:/L/www.googlej.com/seaRchq=fuz:ing' 10 mutations: 'http:/L/www.ggoWglej.com/seaRchqfu:in' 15 mutations: 'http:/L/wwggoWglej.com/seaR3hqf,u:in' 20 mutations: 'htt://wwggoVgle"j.som/seaR3hqf,u:in' 25 mutations: 'htt://fwggoVgle"j.som/eaRd3hqf,u^:in' 30 mutations: 'htv://>fwggoVgle"j.qom/ea0Rd3hqf,u^:i' 35 mutations: 'htv://>fwggozVle"Bj.qom/eapRd[3hqf,u^:i' 40 mutations: 'htv://>fwgeo6zTle"Bj.\'qom/eapRd[3hqf,tu^:i' 45 mutations: 'htv://>fwgeo]6zTle"BjM.\'qom/eaR[3hqf,tu^:i'
如您所见,原始种子输入几乎无法识别。通过一次又一次地改变输入,我们得到了更高的输入多样性。
为了在单个程序包中实现这样的多个变异,让我们建一个MutationFuzzer类。它需要种子(字符串列表)以及最小和最大数量的突变。
from Fuzzer import Fuzzer
class MutationFuzzer(Fuzzer):
def __init__(self, seed, min_mutations=2, max_mutations=10):
self.seed = seed
self.min_mutations = min_mutations
self.max_mutations = max_mutations
self.reset()
def reset(self):
self.population = self.seed
self.seed_index = 0
下面让我们通过添加更多方法来进一步开发MutationFuzzer。Python语言要求我们将整个方法定义为单个连续单元;但是,我们想介绍一种方法,每当我们想向某个类引入新方法C时,我们都使用构造:
class C(C):
def new_method(self, args):
pass
这使我们得到的是C带有new_method()方法的类,这正是我们想要的。
使用此技巧,我们现在可以添加一个mutate()
class MutationFuzzer(MutationFuzzer):
def mutate(self, inp):
return mutate(inp)
让我们回到我们的策略,最大程度地扩大我们样例的覆盖范围。首先,让我们创建一个方法create_candidate(),该方法从当前(self.population)中随机选择一些输入,然后在min_mutations和max_mutations之间变异步骤应用,返回最终结果:
class MutationFuzzer(MutationFuzzer):
def create_candidate(self):
candidate = random.choice(self.population)
trials = random.randint(self.min_mutations, self.max_mutations)
for i in range(trials):
candidate = self.mutate(candidate)
return candidate
该fuzz()方法设置为首先使用seed;当这些用完后,我们进行变异:
class MutationFuzzer(MutationFuzzer):
def fuzz(self):
if self.seed_index < len(self.seed):
# Still seeding
self.inp = self.seed[self.seed_index]
self.seed_index += 1
else:
# Mutating
self.inp = self.create_candidate()
return self.inp
seed_input = "http://www.google.com/search?q=fuzzing" mutation_fuzzer = MutationFuzzer(seed=[seed_input]) mutation_fuzzer.fuzz()
'http://www.google.com/search?q=fuzzing'
mutation_fuzzer.fuzz()
'http://www.gogl9ecom/earch?qfuzzing'
mutation_fuzzer.fuzz()
'htotq:/www.googleom/yseach?q=fzzijg'
每次调用新的fuzz(),我们都会得到另一个不同的应用了多个变异的变体样本。但是,输入的多样性变高同时也会增加输入无效的风险。成功的关键在于指导这些变异的想法,即如何保持那些特别有价值的变异*。*
使用覆盖率引导
为了覆盖尽可能多的功能,可以依靠之前覆盖率一章中讨论的功能。现在,我们将假设待测试的程序可以利用其结构来指导新测试样例的生成。
问题是:我们如何利用覆盖率来指导测试样例的产生?
在著名模糊器中一种特别成功的想法实现了,该模糊器名为American Fuzzy lop,简称AFL。就像上面的示例一样,AFL会生成有效的测试用例—但是对于AFL而言,“有效”意味着在程序执行过程中寻找新的途径。这样,AFL可以继续变异到目前为止已经找到新路径的输入;如果输入找到另一条路径,它也会保留该路径。
让我们来尝试一下,首先介绍一个Runner类,该类捕获给定功能的覆盖范围。第一步。FunctionRunner的类:
from Fuzzer import Runner
class FunctionRunner(Runner):
def __init__(self, function):
"""Initialize. `function` is a function to be executed"""
self.function = function
def run_function(self, inp):
return self.function(inp)
def run(self, inp):
try:
result = self.run_function(inp)
outcome = self.PASS
except Exception:
result = None
outcome = self.FAIL
return result, outcome
http_runner = FunctionRunner(http_program)
http_runner.run("https://foo.bar/")
(True, 'PASS')
现在,我们可以扩展FunctionRunner该类,以便它也可以测量覆盖率。调用run()之后,该coverage()方法将返回上次运行时获得的覆盖率。
from Coverage import Coverage, population_coverage
class FunctionCoverageRunner(FunctionRunner):
def run_function(self, inp):
with Coverage() as cov:
try:
result = super().run_function(inp)
except Exception as exc:
self._coverage = cov.coverage()
raise exc
self._coverage = cov.coverage()
return result
def coverage(self):
return self._coverage
http_runner = FunctionCoverageRunner(http_program)
http_runner.run("https://foo.bar/")
(True, 'PASS')
以下是前五个被覆盖到的位置:
print(list(http_runner.coverage())[:5])
[('http_program', 2), ('__new__', 14), ('urlparse', 368), ('_coerce_args', 119), ('urlsplit', 421)]
现在是主要的class类了。我们维护了数量,并且已经实现了一系列覆盖范围(coverages_seen)。该fuzz()辅助函数接受一个输入和运行给定的function()就可以了。如果其覆盖范围是新的(即,不在中coverages_seen),则将输入添加到population,并将覆盖范围添加到coverages_seen。
class MutationCoverageFuzzer(MutationFuzzer):
def reset(self):
super().reset()
self.coverages_seen = set()
# Now empty; we fill this with seed in the first fuzz runs
self.population = []
def run(self, runner):
"""Run function(inp) while tracking coverage.
If we reach new coverage,
add inp to population and its coverage to population_coverage
"""
result, outcome = super().run(runner)
new_coverage = frozenset(runner.coverage())
if outcome == Runner.PASS and new_coverage not in self.coverages_seen:
# We have new coverage
self.population.append(self.inp)
self.coverages_seen.add(new_coverage)
return result
现在让我们使用它:
seed_input = "http://www.google.com/search?q=fuzzing" mutation_fuzzer = MutationCoverageFuzzer(seed=[seed_input]) mutation_fuzzer.runs(http_runner, trials=10000) mutation_fuzzer.population
['http://www.google.com/search?q=fuzzing',
'http://www.goog.com/search;q=fuzzilng',
'http://ww.6goog\x0eoomosearch;/q=f}zzilng',
'http://uv.Lboo.comoseakrch;q=fuzilng',
"http://www.oogle.com/search?q=fuzzin'",
'http://ww.6goog\x0eo/mosarch;/q=f}z{il~g',
'Http://www.g/ogle.com/earchq=fuzzing',
"httP://www.o/gle.coM-search?q=fuzzin'",
'Http://wwv.gogle.com/kea;rchzq=fuzz',
'Http://wwv.wogle.comkea;rahzq=fuzz',
'Http://wwv.wgle.#omke;rahzq=fuzz',
'hTtp://ww.6gogg\x0eo/mksarch;/u=f}zshl|g',
'htTP://www.o/gle.coMR$search?q=fuzrin#',
'hTtp://ww.6eogg\x0eo/mksarch;/u=fzsl|g',
'htTP://ww.o/gle.hcoMR$search?q=fuzrin#',
'http://ww.6goo#f\x0eo/mosarch;/q=f}z{il~g',
'Http://w7wBv.wogle.comkea;rahq=uzz',
'http://fww.6go\x0eo\x7f/mosrch;/q=f}z{cil~g',
'htTP://www.o/gle.coMR$sear#h?q=fuzrij#',
'http://www.goog.comll/search;Jq=fuzzi,g',
'http://www.goog\x0eom/sea7rch;#q=fuezzi-mog',
'http://ww.6googC\x0eoomos@earch;/q=f}zzilng',
"hTtp://2ww.6eogg\x0eo/mks\\ach\x1b'u=fzsl|g",
'http://ww.6g8mo#\x0eo/m%osarch;/q=f}z{il~g',
"httP://ww(wao/gleR.coM-search?q=uz)n'T",
'http://fww6go\x0eo\x7f/moqsrsh;/q<fx}z{ci?~g',
'http://fw6go\x0eo\x7f/oqs\\rsh;Ea<fx}z{ci?~g',
'htTp://www./gle.coMR$se;a>rchq=fuzrin#',
'http://fww6go\x0eo\x7f/m/qsrs;oq<fx}z{ci?~g',
'http://wwgoog\x0eom/sea7rch;#q=fuezzi-mog',
'hTtp://ww.6ggogg\x0eo/mksach;/u=f}?zshl|g',
'htTp://www./gle.co$se;a>rkhq=fuzrin#',
'hTtp://ww.6gog\x0eo/mksrch;e=fzshl|g',
'hTtp://ww.6ggoPgg\x0eo/m0ksach;+u9}?zshl|g',
'hTtp://ww.6ggogg\x0eo/msch;/u=f}?zshth|g',
'http://fw36go\x0eo/moqsRZh;/q<fx}~[ci?~g',
'http://www.kgle.com/serch?q=fOuzzi#',
'http://wwgoo\x0eoM/se7rch;/#q=ruezzi-mog',
'http://ww.6oog\x0eoomos@garch;2q=f}zzilng',
'hTtp://ww.6ggoPgge\x0eo/M9ksacoh;+u9}?zshl|g',
'htTp://www./gle.wco$se;?a>rkhq=buzrin#',
'htTp://www./g,e.wco$s;?sa>rkhqbuzri.#',
'hTtp://ww.6gogg\x0eo/mksarh;/u=v}zsh#l|g',
"hTtp://ww.6gogg\x0eo/mks'arh;/u=v>s`#l|g"]
成功!在我们的数量中,每个输入现在都是有效的,并且覆盖范围不同,覆盖范围来自各种组合。
all_coverage, cumulative_coverage = population_coverage(
mutation_fuzzer.population, http_program)
import matplotlib.pyplot as plt
plt.plot(cumulative_coverage)
plt.title('Coverage of urlparse() with random inputs')
plt.xlabel('# of inputs')
plt.ylabel('lines covered');
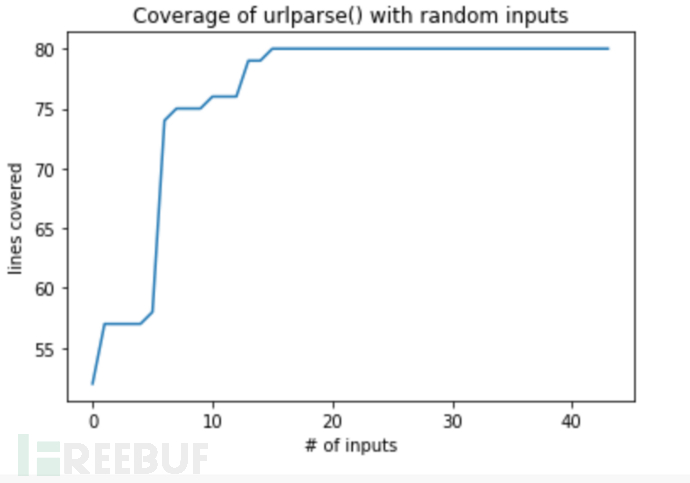
这种策略的好处是,将其应用于较大的程序后,将很乐于探索路径,即一条接一条地进行。
总结
随机生成的输入通常是无效的,因此需要输入处理功能。
在有效输入上的变异具有较高的成功概率。
- 0 文章数
- 0 关注者