


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
Hadoop环境搭建
一、基本配置
1、首先需要的环境:Centos7-版本不限,克隆三台配置好的机子、hadoop、jdk安装包、Xftp软件(缺一不可)
二、任务部署
1、安装VMware虚拟机
2、安装Centos7版本的虚拟机
3、准备3台配置完毕的虚拟机
4、搭建3台节点的Hadoop集群
三、Hadoop搭建的安装包
1、链接: https://pan.baidu.com/s/1gWpQ7Dh5dgXyjKfHUYuC5Q
提取码:k2q8
四、知识讲解
简单说明:
在搭建的过程中,小伙伴们统一保持和博主一样的配置
VMware版本:
VMware建议使用博主给的安装包里面都有
关于VMware的安装,我已经把安装包放在了链接大家自取就行,里面是包含了VMware版本密钥的
linux版本:
linux版本我就直接放这大家自取就行
若链接失效请找博主索要镜像
1、linux系统的安装:
1、安装VMware
呃,博主这安装过了
vmware安装链接: https://blog.csdn.net/Alger_/article/details/111193639
配置
处理器数量:1
处理器的内核数量2
网络配置:NAT
虚拟机的内存:4096(4GB)
磁盘容量:40,将虚拟机磁盘存储为单个文件
软件安装:最小安装,除智能卡取消其他全选
KDUMP:取消勾选
Root密码:123123
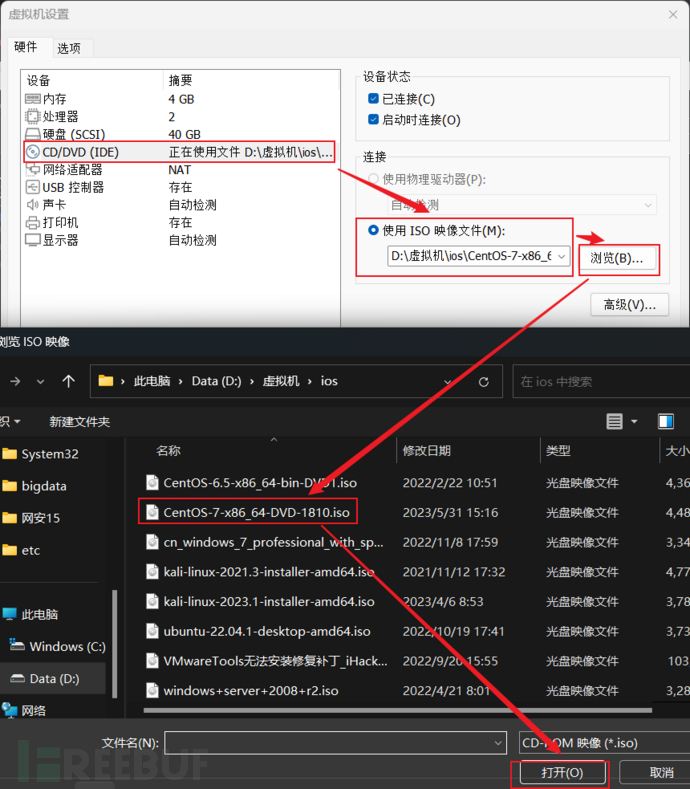
2、linux虚拟机配置ios
1:通过设置来配置ios镜像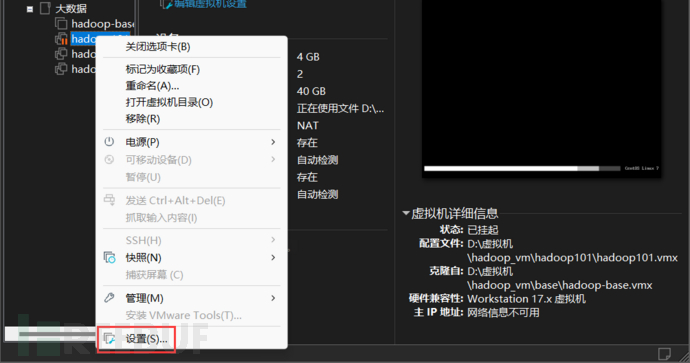
3、linux虚拟机设置网络配置
1、设置虚拟机的虚拟网络配置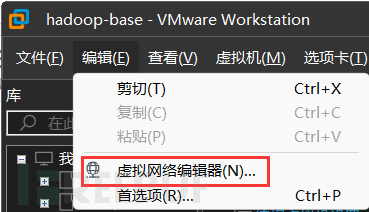
2、查看NAT的默认网关、ip地址以及子网掩码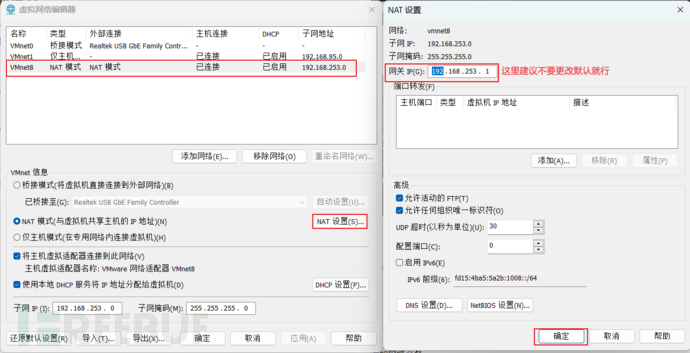
3、设置windwos的VMNet8网络地址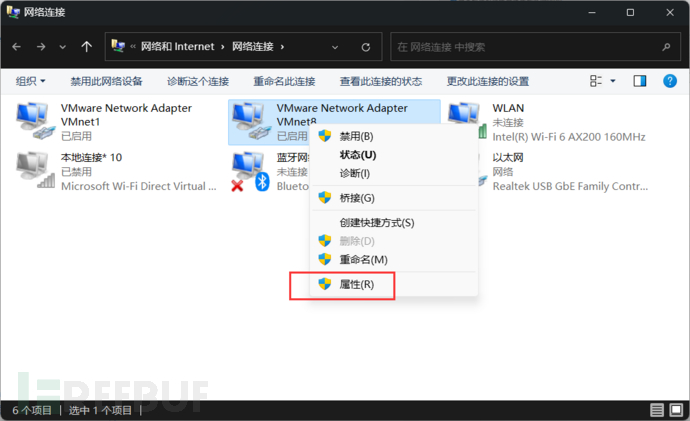
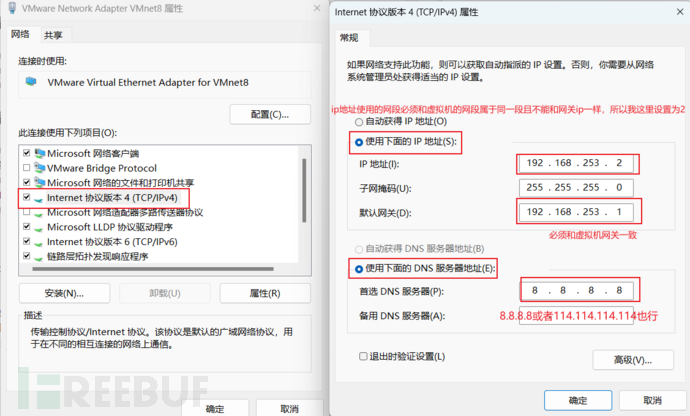
4、linux设置网络配置
网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
添加网络必备
IPADDR=192.168.253.100 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
编辑静态IP和开机自启
BOOTPROTO=static
NOBOOT=yes
重启网络服务
systemctl restart network
安装vim和常用软件
yum -y install vim
yum -y install net-tools
4、克隆虚拟机
反复创建虚拟机很难受,直接克隆最干脆
克隆搭建好的虚拟机的快照即可
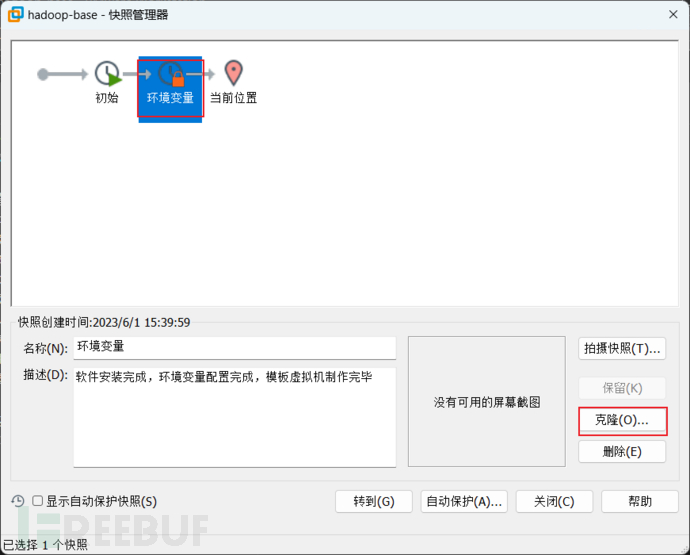
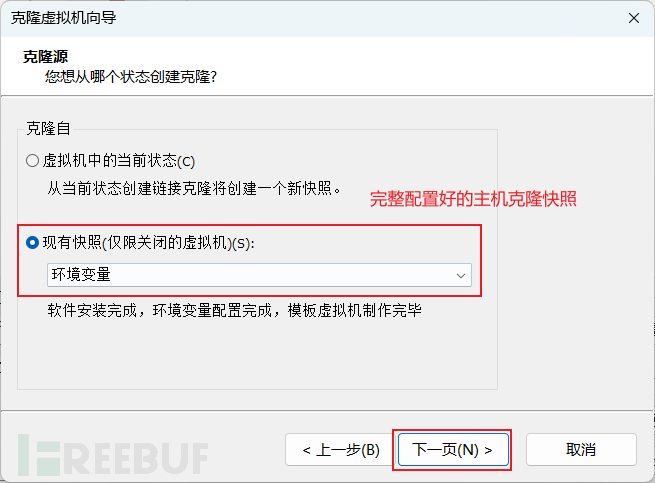
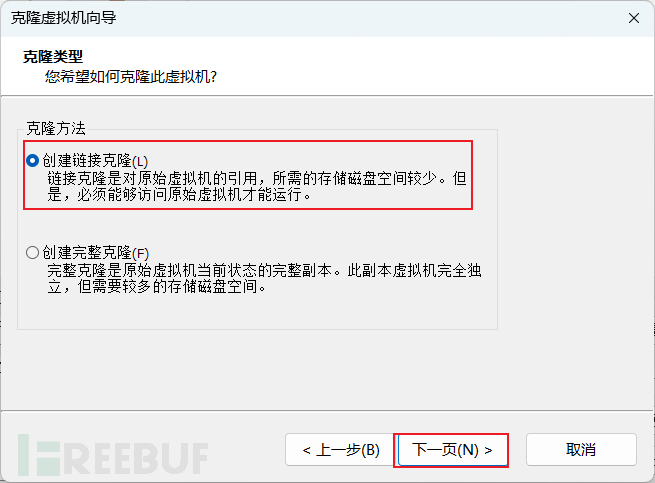
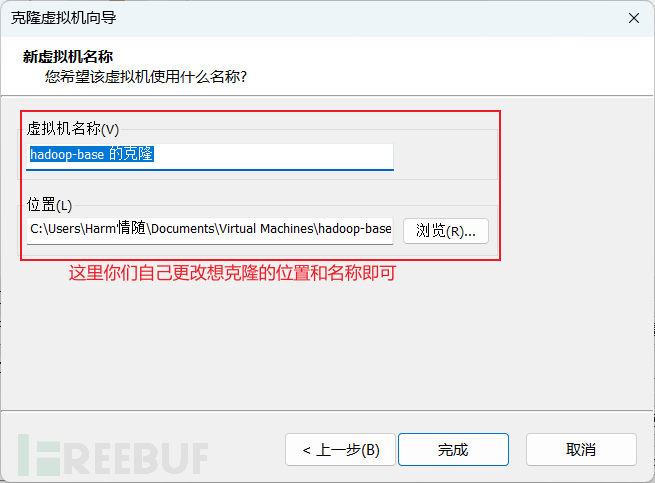
反复克隆出三台机子就够用了
5、克隆机更改ip地址
三台克隆机ip地址分别为:192.168.253.101、192.168.253.102、192.168.253.103
名称分别为:hadoop101、hadoop102、hadoop103
因克隆的虚拟机ip地址都相同,更改ip地址即可,其他可不要更改
启动虚拟机,用户为root,密码为123123
更改ip地址配置文件
hadoop101
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.253.101 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
hadoop102
IPADDR=192.168.253.102 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
hadoop103
IPADDR=192.168.253.103 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
2、安装大数据集群环境基本配置
1、三台虚拟机关闭防火墙
systemctl status firewalld
若呈现绿色字样及未关闭
若现呈黑色字样及为关闭
systemctl stop firewalld
systemctl disable firewalld
2、三台虚拟机更改主机名
vim /etc/hostname
克隆机1
hadoop101
克隆机2
hadoop102
克隆机3
hadoop103
3、三台虚拟机更改主机名与ip映射地址
vim /etc/hosts
192.168.253.100 hadoop-base
192.168.253.101 hadoop101
192.168.253.102 hadoop102
192.168.253.103 hadoop103
192.168.253.104 hadoop104
192.168.253.105 hadoop105
4、三台虚拟机添加普通用户
三台虚拟机统一添加普通用户user001,并给予sudo权限,用于以后所有的大数据安装(避免root执行危险的操作)
普通用户密码为123123
useradd user001
passwd user001
5、三台虚拟机为普通用户添加sudo权限
vim /etc/sudoers
添加如下内容
user001 ALL=ALL(ALL) NOPASSWD:ALL
6、三台虚拟机在根目录统一目录
三台克隆机在根目录下创建bigdata目录—project、software
目录权限更改为user001
chown user001:user001 project/ software/
三台克隆机通过su命令切换user001用户
su user001
123123
7、三台虚拟机普通用户免密登录
先重启三台虚拟机使主机名生效
重启命令:reboot
ssh免密登录方式
hadoop101:
ssh-keygen
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop101
hadoop102:
ssh-keygen
ssh-copy-id hadoop101
ssh-copy-id hadoop103
ssh-copy-id hadoop102
hadoop103:
ssh-keygen
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
8、通过Xftp传输hadoop、jdk软件包
使用方法
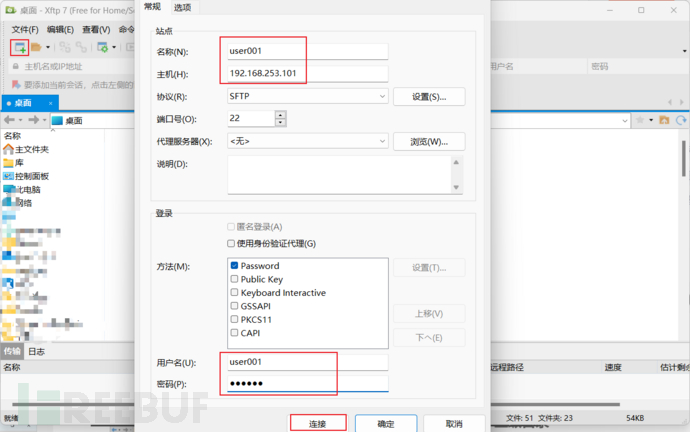
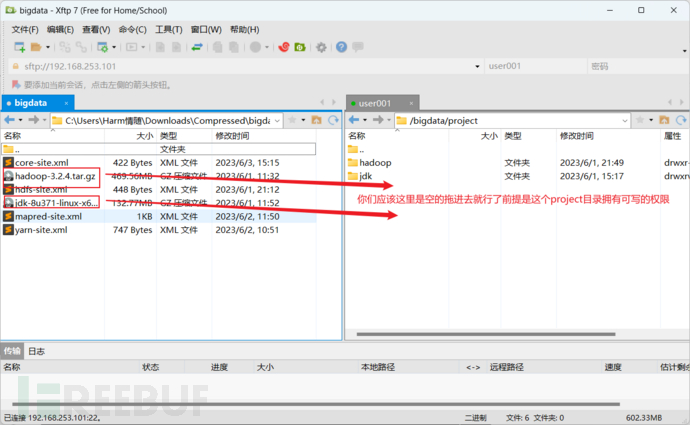
9、三台虚拟机安装jdk
使用user001来重新连接三台机器,使用user001来安装jdk软件
上传压缩包到第一台服务器的/bigdata/project/下面,进行解压,配置环境变量即可,三台都依次安装即可
cd //bigdata/project
cd ..
cd /software
ll:tarX2(hadoop\jak)
tar -zxvf jdk----------------------.tar.gz -C /bigdata/project
tar -zxvf hadoop-------------------.tar.gz -C /bigdata/project
cd /project
mv hadoop---- /hadoop
mv jdk------- /jdk
配置jdk和hadoop环境变量
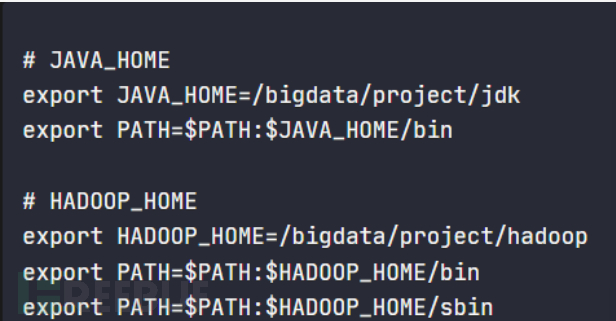
sudo vim /etc/profile.d/my_env.sh
内容:
JAVA_HOME
export JAVA_HOME=/bigdata/project/jdk
export PATH=$PATH:$JAVA_HOME/bin
HADOOP_HOME
export HADOOP_HOME=/bigdata/project/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile 更新源
建议三台克隆机都拍个快照
3、hadoop集群的安装
1、上传压缩包并解压
cd //bigdata/software
tar -zxvf hadoop-------------------.tar.gz -C /bigdata/project
2、修改hadoop配置文件
修改core-site.xml
第一台克隆机执行以下命令
vim core-site.xml
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/project/hadoop/data</value>
</property>
</configuration>
修改hdfs-site.xml
第一台克隆机执行以下命令
vim hdfs-site.xml
hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn wen段访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
修改mapred-site.xml
第一台克隆机执行以下命令
vim mapred-site.xml
mapred-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
第一台克隆机执行以下命令
vim yarn-site.xml
yarn-site.xml:
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
修改workers文件
第一台克隆机执行以下命令
vim workers
替换
hadoop101
hadoop102
hadoop103
Xftp覆盖配置文件
把core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这四个配置文件通过xftp覆盖到/bigdata/project/hadoop/etc/hadoop/下面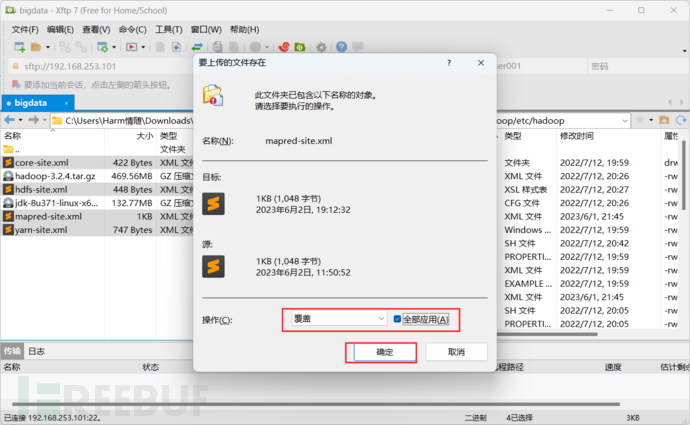
分发rsync
分发101配置文件给102和103的克隆机
hint:前提是要在/bigdata/project/Hadoop/etc/hadoop目录下
rsync -a -v ./ hadoop102:/bigdata/project/hadoop/etc/hadoop
rsync -a -v ./ hadoop103:/bigdata/project/hadoop/etc/hadoop
执行完之后在/bigdata/project/hadoop目录执行
hdfs namenode -format (对namenode进行格式化)=(对hdfs文件系统格式化)
没有报错则格式成功
4、Hadoop集群环境启动
101克隆机:hadoop的根目录下执行:sbin/start-dfs.sh 启动hdfs
102克隆机:hadoop的根目录下执行:sbin/start-yarn.sh 启动yarn
在浏览器上访问:
hadoop101:9870或ip+:9870
hadoop102:8088或ip+:8088
关闭服务
hadoop根目录下执行:stop-dfs.sh
hadoop根目录下执行:stop-yarn.sh
ps 制作文章实属不易如帮助到你,请你给我个关注谢谢
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者