


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
文件类型识别是文件内容还原以及后续的文件敏感信息检测预处理过程中不可或缺的一部分,精确的文件类型识别是文件内容还原和文件敏感信息检测模型选择的关键步骤之一,它能够让我们根据不同的文件类型选择适合的文件内容提取方法和敏感信息检测模型。文件类型的多样性,会给有关数据保密以及信息安全等方面带来威胁,通过对一些文件类型的识别和阻断,可以避免互联网上木马和病毒的传播,还可以避免保密文件的泄漏。
文本文件是一种由若干行字符构成的计算机文件,文本文件大部分为脚本语言类文件,即使用脚本语言创建的文件,脚本语言例如有javascript、python、以及php(Hypertext Preprocessor,超文本预处理器)等。脚本语言类文件一般是根据所使用的脚本语言以特定后缀名(如.reg,.vbs,.js或.inf等)进行保存,例如javascript脚本语言文件以 .js的后缀名进行保存。现有技术通常是基于文件后缀名来确定文本文件的类型,例如检测到文件的后缀名为“js”,则判断文件类型是javascript脚本语言文件。在对现有技术的研究和实践过程中,现有文本文件类型的识别方式,识别准确率较低,一旦文件的后缀名被修改,将会识别出错误的文件类型,造成误判。
文件类型识别原理
当服务器接收到待识别文件,通过读取待识别文件中的文件魔法数特征,并将文件魔法数特征与预先统计设定不同文件类型的多个魔法数特征进行匹配,获取匹配的文件类型,然后再使用匹配到的文件类型的语法树规则与待识别文件的内容进行对比分析,若语法树规则能正常与待识别文件的内容的框架相对应,则将待识别文件的文件类型识别为预定文件类型。
具体流程
待识别文件可以是任何未携带扩展名的未知文件类型的文件。表示不同文件类型的魔术数,是指文件的最开头的几个用于唯一区别其它文件类型的字节,根据这些字节特征就可以很方便的区别不同的文件类型,相比于只根据文件后缀名来识别文件类型准确率要高的多。
首先要以二进制的方式读取文本文件的前100个字节,然后再读取文件类型与文件魔法数一一对应的文件,将魔法数逐一与读取的字节匹配对应,然后获取到匹配的文件类型。部分文件魔法数样式如下图所示:
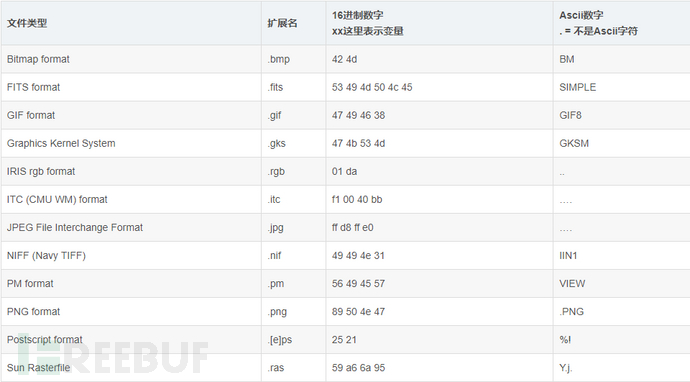
图1部分图片类文件魔法数
不同的文件类型的语法树规则是指待识别文件中所记录的文本特征信息,例如可以是待识别文件中的关键字,关键字是指计机语言里事先定义的、有特别意义的标识符,例如if、for、while、def等,javascript语言文件类型、python语言文件类型、php语言文件类型、html语言文件类型或vbs语言文件类型等语法树规则各不相同。
读取待识别文件的内容,根据匹配到的文件类型,获取其预先设定好的语法树规则,然后与待识别文件中的内容进行匹配,当匹配的正确率达到超过预先设定的阈值时,则该待识别文件的文件类型即为所匹配的文件类型。下图为匹配结果示例:

图2 文件类型识别分析结果展示
文件类型的准确识别能够帮助文本内容提取更全面的更准确的文本特征信息,为以后的文本敏感信息检测的算法模型提供更优质的数据输入,提升模型识别的准确率。
- 0 文章数
- 0 关注者