


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一、人工智能简史
业界公认人工智能的起源是1956年的达特茅斯会议。出席这次会议的有麦卡锡、明斯基、香农、所罗门诺夫、纽厄尔、司马贺、西蒙、撒缪尔、塞弗里奇、罗切斯特、和摩尔,可谓人才济济。正是在这次会议上首次出现了“人工智能”这个词汇。
图 1 达特茅斯会议
达特茅斯会议之后,人工智能就展开了跌宕起伏的发展历程。人工智能的发展大致可以归纳为三次高潮和两次低潮。第一次高潮大致是从1956年到1974年,这一时期取得突破的领域包括机器定理证明。普通人觉得数学定理证明很难,在马路上骑自行车很容易。在人工智能领域恰恰相反。因为前者属于封闭系统,条件确定,后者是开放系统,存在大量的不确定因素。1959年,华人学者王浩在IBM 704上的程序花费8.4分钟机器时间,自动证明了《数学原理》中的133条一阶逻辑定理。1976年,阿佩尔(Kenneth Appel)与哈肯(Wolfgang Haken)完成四色定理的计算机辅助证明。在成就面前,一些科学家过于乐观,H. A. Simon在1958年曾经断言不出10年计算机将在国际象棋比赛中击败人类。随着一些断言(吹牛)的破灭,批评之声涌现,国家(美国)层面缩减了研究经费。人工智能的第一次低潮来临了,这个阶段大约从1974年到1980年。野火烧不尽,春风吹又生。人工智能的研究并没有沉寂太久,第二次高潮很快又来了,这次高潮的代表事件是日本的第五代计算机计划和专家系统的流行。上世纪70年代末,日本雄心勃勃地想从制造大国向经济强国转型,日本的精英们想到的突破口也是人工智能。在日本的带动下,美国、英国、法国、德国纷纷行动,制定出对应的计划。于是,在各国政府的大力投入下,人工智能迎来了新的高潮。转眼间到了上世纪80年代末,日本的第五代计算机进展缓慢,巨额的投入没有换来与之相当的收益。后果自然就是人工智能再次进入低潮,本世纪初随着互联网时代的到来,海量数据和高性能运算期间推动人工智能进入第三次高潮。
人工智能研究的领域很大,涉及甚广,派别众多。两个最有影响力的派别是符号主义和连结主义。符号主义(Symbolism)的主要思想就是应用逻辑推理法则,从公理出发推演整个理论体系。前面提到的机器定理证明就属于符号主义。连结主义(Connectionism)是一种基于生物神经网络机制与学习算法的智能模拟方法,其原理主要为模拟神经网络和神经网络间的连接机制,在此基础上配置算法。这两个派别自人工智能诞生之日起就存在,符号主义认为实现人工智能必须使用逻辑和符号系统,这一派看问题的角度是自顶向下的;连结主义认为通过仿造大脑可以达到人工智能,这一派是自底向上的。连接主义认为如果能制造一台机器,模拟大脑中的神经网络,这台机器就有智能了。套用一个庸俗的哲学名词,前者唯心,后者唯物。
人工智能的第三次高潮的核心是连结主义的深度学习网络。深度学习需要两个条件:大数据和大算力。互联网的普及满足了大数据的需求。集成电路的发展带来了算力的巨大提升。
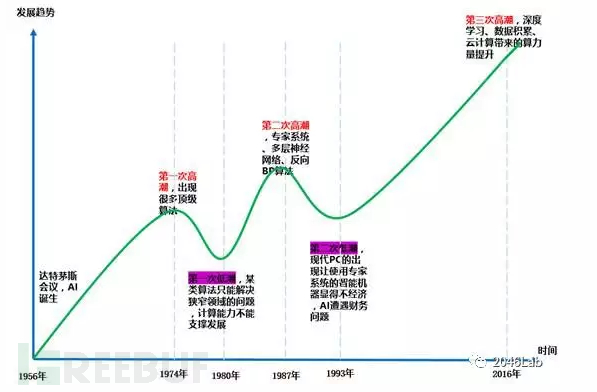 图 2 人工智能简史
图 2 人工智能简史
二、机器学习简介
机器学习,就是在不专门编程的基础上让计算机拥有学习的能力。机器学习是人工智能的一个重要的子领域。机器学习和深度学习主导了人工智能的第三次高潮。那么,机器学习是符号主义还是连接主义?都不是也都是。机器学习包含很多模型,其中有的偏符号,有的偏连接,还有的两者都不是。下面每类介绍一种:
2.1决策树
决策树是一类常见的机器学习方法。机器学习中,决策树是一个树形结构,叶节点代表分类,非叶节点为决定分类的特征。下面看一个简单的例子:
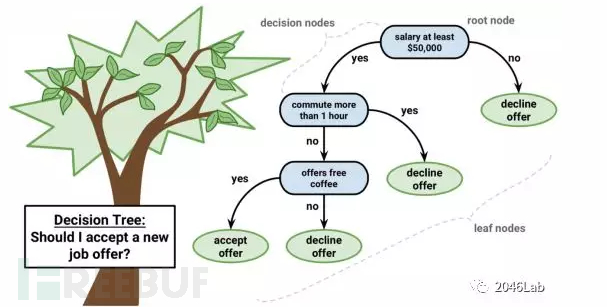
图 3 决策树示例
决策树包含一个根节点、若干个内部节点和若干个叶节点。叶节点对应决策结果,根节点和内部节点对应特征测试。决策树学习的目的是产生一棵泛化能力强,也就是处理未见数据能力强的决策树。构造决策树的过程就是从根向下逐级选择属性的过程,选择的标准之一是信息论中的信息熵和信息增益。简而言之,信息增益越大的属性在决策树中的层次越高。
决策树的概念表达十分清晰,决策结果的可解释性也非常好。决策树可以被归为符号主义。
2.2支持向量机
上世纪90年代中期,“统计学派”(Statistical Learning)闪亮登场并迅速占领主流,其代表性技术是支持向量机(Support Vector Machine, SVM)。下面以线性2类别分类问题简要说明SVM的工作原理。
f(x) = wx + r
上式中的w是将正样本和负样本隔离开的超平面的法线,r为截距。
对于样本xi对应的分类为yi,规定若分类为正样本,则yi=1,反之yi=-1。选择w和r的依据是令:
(wxi+r)yi≥1
当存在满足这样的条件的w和r时,这样的训练样本集就是线性可分的训练样本集。对于线性可分的训练样本集,可以把所有样本都正确分类的解有无数多个。这就需要确定最优解。下面该支持向量登场了。满足wxi+r=1的向量为距离超平面最近的向量,它们被称为支持向量。支持向量到超平面的距离为:1/|w|。最优解就是令1/|w|最大。
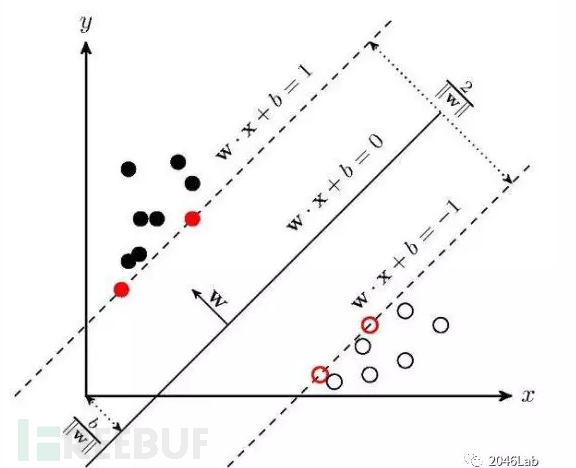
图 4 SVM示例
上面这个例子简单展示了支持向量机的工作原理。除了线性分割外,支持向量机还支持其它的分割模型。支持向量机既不是符号派,也不是连接派,在深度学习大放异彩之前,支持向量机以其优异的性能长期占据机器学习受关注的中心。
2.3深度学习
人工智能在上世纪80年代的光芒被后来的互联网所掩盖。但是进入新世纪,恰恰是互联网产生的海量数据给了人工智能巨大的机会。近几年,人工智能领域使用频率最高的词是深度学习。神经网络是由一层层的神经元构成,层数越多,网络越深。所谓深度学习就是用很多层神经元构成的神经网络达到机器学习的功能。理论上说,如果一层网络是一个函数,多层网络就是多个函数的嵌套。网络越深,表达能力越强,与之而来的是训练的复杂性也急剧加大。
本世纪初,连接主义卷土重来,掀起了“深度学习”的热潮。在若干测试和竞赛中,尤其是涉及语音和图像等复杂对象,深度学习取得了卓越的成绩。以往机器学习技术要取得优越性能,需要使用者对应用领域具有深厚的了解。而深度学习不是这样,只要使用者下功夫把深度学习模型的参数调整好,就能取得很好的性能。深度学习虽然缺乏严格的理论基础,但是显著地降低了使用者的专业门槛,为机器学习技术走向工程实践带来了便利。图 5是一个深度学习网络示例。
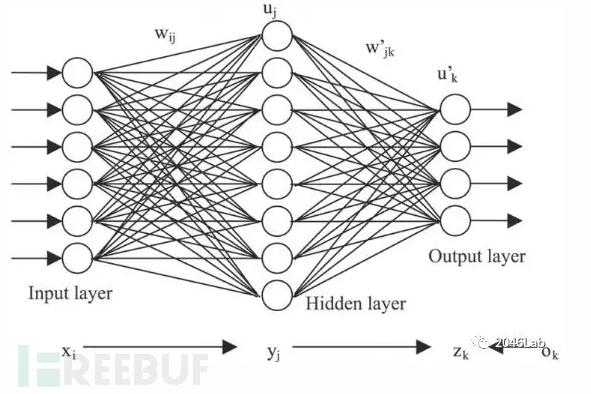
图 5 深度学习网络
三、现状
目前,机器学习中的深度学习正处于发展的巅峰。深度学习在计算机视觉、语音识别、和自然语言处理上都有良好的表现。巅峰意味着风光无限备受关注,但也意味着今后要走下坡路了。
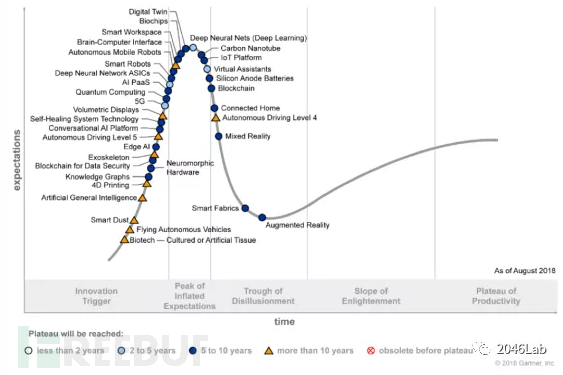
图 6 Gartner技术趋势
3.1 计算机视觉
计算机视觉的研究内容涉及甚广。目前主流的方法是基于深度学习的方法。自从2012年,AlexNet以巨大领先优势获得ImageNet比赛中获得第一名以后,研究人员开始思考是否能够用深度学习方法来做图像识别的任务。高性能计算器件 (CPU, GPU)的出现和大规模图像数据集的出现,加上研究人员对图像识别问题的日益深刻的理解,基于深度学习的图像识别算法将图像识别精度提高到了一个新的台阶。
3.2 语音识别
语音识别是人工智能的一只圣杯。十年前,计算机的独立的语音识别应用领域还很有限,比如机票预订。2012年,一名来自多伦多大学的实习生在微软研究院的一个夏季研究项目中,让微软的语音是别系统的性能得到了显著的提升。2016年,微软的一个团队宣布,他们开发的一个拥有120层的深度学习网络已经在多人语音识别基准测试中达到了与人类相当的水平。
3.3 自然语言处理
深度学习快速改变格局的一个例子时它对语言翻译的影响。语言翻译是人工智能的一只圣杯,因为它涉及对句子的理解。传统上,人工智能在演算和感知上都取得了突破,前者如下围棋,后者如图像识别。但是一旦涉及到理解,人工智能就难以突破。谷歌推出的基于深度学习的谷歌翻译后,自然语言翻译质量取得了重大飞跃。深度学习可以在整个句子中寻找词汇之间的依赖关系。
人工智能检测恶意代码
人工智能领域所涉甚多,复杂而庞杂。同样复杂而庞杂的是信息安全领域,它比人工智能还要难以说清楚。本文只谈谈信息安全中的一个小领域——恶意代码检测。
前面挂一漏万地描述了人工智能的发展和现状,这些成果和应用都和信息安全没有什么联系。因为,人工智能就像往池塘中投掷的一个石块,最初的突破掀起的涟漪要经过一段时间才会波及到其它的领域。目前为止,人工智能在信息安全领域没有原创技术,都是从其它领域——主要是图像、声音、和自然语言处理——移植已有的成果。
利用已有的模型来处理现有的问题需要做什么工作呢?答案是需要将问题描述转化为向量,然后让已有的模型来处理这些向量。所以,本章的内容就是形形**的“2vec”(to vector),即“向量化”。打个比方,现成的鞋子有很多双,就看你的脚能不能塞进去了。
图像法
信息安全领域并不是人工智能应用的重点领域。随着人工智能的第三次高潮,深度学习和机器学习应用在信息安全领域是一个自然的趋势。但是,怎么用呢?一个自然的想法就是将信息安全的问题转化为一个现在已经有完美解决方案的问题,比如将二进制程序文件转化为图像,然后用图像识别方法对其进行分类和识别。这就是2011年加利福尼亚大学的学者Nataraj和Karthikeyan的论文“Malware Images: Visualization and Automatic Classification”的基本思想。这篇论文的思路非常新颖,在试验中也展现了一定的效果。在后续的研究中,很多学者沿着这个思路发表了一些研究成果。这些论文显现了恶意代码的图像模式并不固定。使用这种方法必须根据实际情况经常进行调整。
源代码检测
如果让人来分辨恶意软件,阅读源代码无疑比阅读反汇编后的CPU指令要容易。在任何领域运用机器学习和深度学习的第一步都是向量化,将输入转化为数字向量,然后机器学习和深度学习就可以处理数字向量了。对程序语言的向量化有两种方式,一种可以被称为主观的向量化,由人定义一些条件,比如变量的平均长度,一行代码的最长长度,函数的调用次数等。这种向量化的优点是相对简单,运算代价小;缺点是主观性较大,不灵活,不能反应程序的实质。另一种可以被称为客观的向量化。思想是使用一些数学模型来计算出向量。相比前一种方法,它显然更加客观,缺点是相对计算成本大。
客观的向量化所使用的数学模型主要来自自然语言处理的已有成果。自然语言处理领域用的比较多的向量化方法有:word2vec、CBOW、skip-gram。为了运用这些已有的成果,需要做的第一个工作是定义什么是“词”。这就需要另一项已有的成熟技术了,它就是编译器。编译过程实际上分为若干阶段。下面这张图是gcc的各个编译阶段,其它的编译器与之类似。
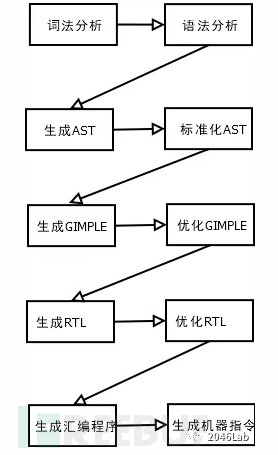
图 7 gcc编译阶段
与真正的编译的区别在于,此处只要得到抽象语法树(Abstract Syntax Tree, AST)就已经足够运用自然语言处理的已有技术了。下面是由一段程序转化而成的抽象语法树:
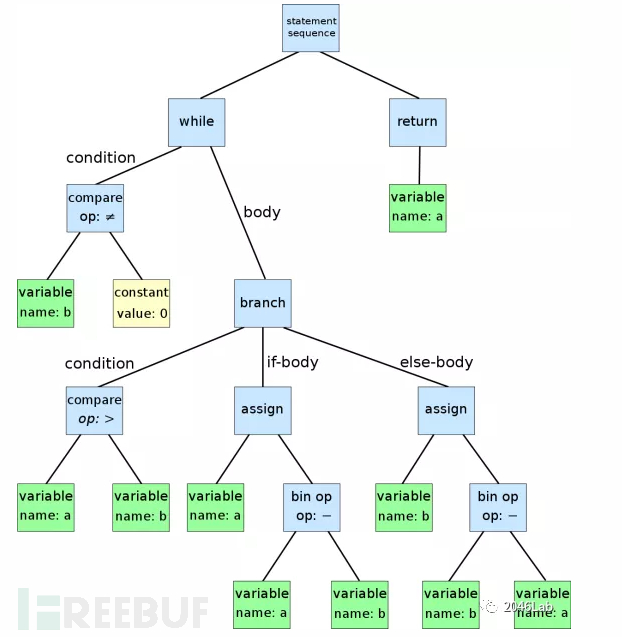
图 8 抽象语法树示例
抽象语法树中的节点标记某种语句或者表达式,节点的子节点表示语句或表达式的参数。一段程序语句会转化为若干棵树。
下面介绍2018年的一篇有趣的论文:code2vec: Learning Distributed Representations of Code。这篇论文的研究成果是在抽象语法树的基础上学习出一个函数的语义,进而“预测”函数的名字。研究用到了自然语言处理中的注意力模型。

图 9 code2vec示例
目标代码检测
恶意软件的另一种存在形式是二进制代码形式,这是比源代码方式更广泛的存在形式。大部分这个领域的研究是将CPU指令当作“词”,将一段关联的指令当作“句子”。然后运用自然语言处理的成熟方法。如何定义关联,如何取词,那就“八仙过海各显神通”了。下面列出几种处理方法:
instruction2vec
instruction2vec出现在2019年的一篇论文——“Investigating Graph Embedding Neural Networks with Unsupervised Features Extraction for Binary Analysis”——之中。其基本思想是从二进制代码中提取出控制流图,再将控制流图转化为向量。这项研究主要使用了自然语言处理中的attention模型和深度学习的循环神经网络(RNN)。
Structure2Vec
Structure2Vec出现在2016年的一篇论文——“Discriminative Embeddings of Latent Variable Models for Structured Data”——之中。计算机程序中有大量的有结构的数据结构,比如树、图、数组。这篇论文的主要研究工作是向量化这些有结构的数据结构。
Asm2Vec
Asm2Vec出现在2019年的一篇论文——“Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization”之中。其应用场景是对二进制代码实施反汇编之后,对这些汇编语句向量化。其研究成果显示,Asm2Vec可以识别代码克隆、代码同义改写、以及代码微调。在克服代码优化和代码混淆带来的识别困难上,Asm2Vec也有不俗表现。
问题与展望
如前所述,人工智能在信息安全领域还没有孵化出全新的模型。目前取得的成果都是自图像、声音、和自然语音处理领域移植现有模型,再做适配性处理。但是信息安全领域有自己的一些特点。以恶意软件识别为例,在现实中绝大多数的软件是非恶意的,这个基本事实给机器学习的训练和识别都带来了巨大的挑战。在图像领域,互联网巨头可以利用海量数据提升了深度学习的准确性。在恶意软件识别领域,这是无法达到的。相关厂商和研究机构很难拿到与图像领域匹敌的数据。训练如此,识别也是如此。如果现实世界中只有万分之一的软件是恶意软件,那么如果你训练的模型只是将1%的软件识别为恶意软件,那仍然意味着有100倍的误差。
另一个棘手的问题是可解释性。在图像和声音领域,这个问题还不算太突出。识别照片里有一匹马只是结果,人不需要模型解释什么是马,马头在哪里,马腿在哪里,马尾巴在哪里。但是,在恶意软件识别上,客户就没有这么宽容了。客户想知道软件的“恶意”到底在哪里。尤其是在把一个客户开发的软件识别成恶意软件的时候。
在可预见的未来,人工智能在信息安全领域的应用还是移植其它领域的成果,运用信息安全领域的专业知识将信息安全问题向量化供已有模型使用是工作的重点。随着机器学习研究和开发的日益成熟,未来机器学习在信息安全领域一定会有越来越多的成果涌现。
*本文作者:东巽科技2046Lab,转载请注明来自FreeBuf.COM
- 0 文章数
- 0 关注者