


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
目标
基于UNSW-NB15数据集提供的已经过特征工程的CSV文件,训练一个以Session/Flow为单位对异常流量的二分类。
数据预处理
在对数据集进行简单的探索分析和清洗后,可以开始根据任务目标对数据预处理。
CSV文件中的每一行为一个Session,在以Session为单位的分类中,描述Session上下文环境(而非描述Session本身)的信息可以直接去除,所以首先去除与IP地址以及Session开始和结束的时间戳相关的列。
其次,由于只是对于异常流量的二分类,与攻击类型相关的列也可以去除。
one-hot编码
在入侵检测数据集中,有许多列所表示的是离散数据,比如端口、协议以及状态(虽然端口是以数值形式在数据集中被表示,但端口之间的关系并不如其数值关系所表示的那样,如80 http和443 https)。
协议和端口的的处理方式可以参考自然语言处理中的将不同词语。但是,在词汇量较大的情况下,使用one-hot编码会使模型的维度过高,相同的问题也在处理端口时尤其突出。解决方法可以是只筛选其中频繁出现的端口或协议进行one-hot编码。
端口的去留
上一节提到端口若作为离散数据进行one-hot编码会使数据集的维度过高,除了筛选一部分高频出现的端口,另一种解决方式是直接去除与端口相关的列。
由于网络通信中端口的选用与协议有相当大的关联,所以在数据集中存在协议相关列的情况下可以直接去除与端口。协议与端口的关联可以通过计算协议和端口列之间的信息增益率证明。
模型建立
只是建立一个简单的入侵检测模型,模型的建立方面就简单直接一些DNN+Batch Normalization,以95%的准确率为目标。
model = keras.Sequential([
tf.keras.Input(shape=(202,)),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=2048, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=1024, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=1024, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=512, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=256, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=128, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=64, activation=keras.activations.elu,kernel_initializer='he_normal',),
keras.layers.BatchNormalization(),
keras.layers.Dense(units=1, activation=keras.activations.sigmoid),
])
model.compile(loss='MSE',
optimizer=keras.optimizers.Adam(learning_rate=0.0001),
metrics=[keras.metrics.BinaryAccuracy(),tf.keras.metrics.Precision(),tf.keras.metrics.Recall()],
)
CHECKPOINT_PATH = './weights.{epoch:03d}-{val_loss:.4f}.hdf5'
# Create a callback that saves the model's weights
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=CHECKPOINT_PATH,
save_weights_only=True,
verbose=1)
history = model.fit(x=X_train,y=Y_train,
batch_size=1000,
epochs=5,
validation_data=(X_test,Y_test),
callbacks=[cp_callback],)
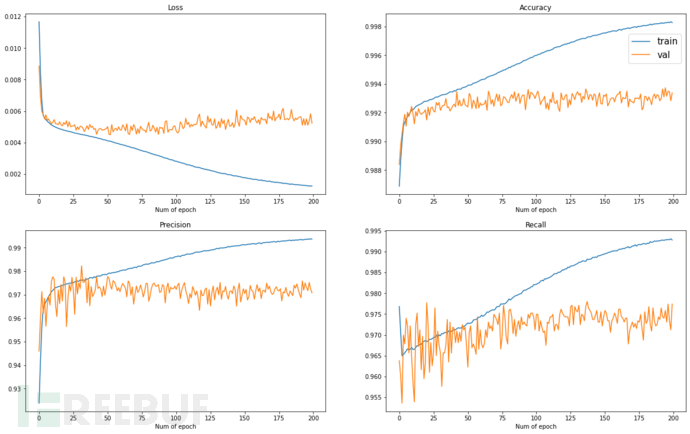
实验结果
经过200轮,共约两小时的训练可以看到有一定程度上的过拟合,后续可以采取Dropout、正则化等措施,但总体上各项指标都在96~97%左右,实验结果已经优于一些Access论文,足够作为一个简单的Baseline模型。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者