


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
Web扫描器通过构造特殊请求的方式,对Web系统可能存在的安全漏洞进行扫描,是渗透工作的必备工具。本文尝试从扫描器检测方向出发,根据扫描器的功能和所产生的请求内容对其进行分类,结合苏宁Web应用防火墙(WAF)日志数据,分别展示了规则模型、统计特征模型和基于n-gram的的MLP模型在Web扫描器识别上的简单实践效果,供大家参考。
一. 扫描器概览
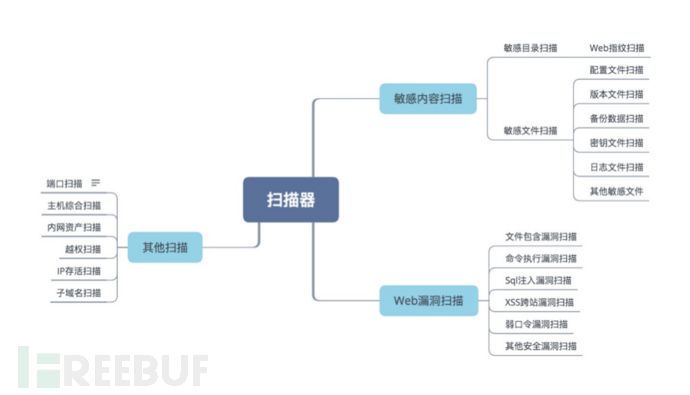 图1 - 扫描器分类
图1 - 扫描器分类
1 敏感内容扫描
俗话说知己知彼方能百战不殆,当黑客或渗透测试人员面对一个未知站点时,这个站点对他们来说就是一个黑盒。这时候不妨拿敏感内容扫描器先给它来个一把嗦摸摸底,指不定就能扫到有价值信息,找到撬动安全防护缺口的第一把钥匙。
敏感内容扫描器通常具备一系列敏感路径及敏感文件的字典,扫描器利用这些敏感内容字典对站点进行盲扫来判断是否存在这些敏感内容;进一步地,通过响应数据包对站点目录结构及其他信息进行判断,为下一步针对性单点突破作准备。
这里提到了一个字典的概念,字典这玩意很重要,可以说字典的质量、广度和深度决定了这个扫描器的上限。相对于IP代理、UA伪造、随机化访问时间间隔这些伪装手段来说,敏感内容是固定的,翻来覆去就这么多东西,同时因为请求资源不存在大多数会返回404状态码(有些会触发WAF拦截策略返回403,还有些因为服务器设置了默认跳转状态码为301或302)。攻方选手通常不会构造毫无意义的字典内容来浪费有限的资源和精力,这些字典通常包含如下内容信息(忽略大小写):
- 敏感目录信息:如/admin/, /phpadmin/, /mysqladmin/, /usr/local/, /etc/passwd/, ...
- 敏感配置文件:如.bashrc, .bash_history, conf.icn, config.inc, ...
- 版本文件信息:如/.git/config, /.svn/entries, /.bzr/xxx, ...
- 备份文件信息:如bak, index.php.bak, database.wsp, backup.zip, ...
- 密钥文件信息:如/.ssh/id_rsa, /.ssh/known_hosts, id_rsa.pub, authorized_keys, ...
- 日志文件信息:如/logs/error.log, /logs/auth.log, /var/log/mysql/mysql.log, ...
- 其他敏感文件:如php, system.inc, mysql.inc, shell.php, ...
2 Web漏洞扫描
漏洞扫描器通常会与爬虫相结合。首先利用爬虫获取到页面可能存在注入点的接口,然后针对该接口来一个SQl注入、XSS注入、命令注入一把嗦,对于一些安全防护意识低的站点往往能取到最直接的效果。针对这类扫描请求,WAF都能够做到单点正则过滤,理论上会拦截返回大量403状态码,但是扫描器常针对一些新域名或偏僻的域名进行扫描,这些域名往往没有启用WAF攻击防护,因此实际上是有很多是未被拦截的非403状态码。同上述敏感内容扫描,这类请求往往也具备明显的文本特征,下面分别以SQL注入、文件包含和XSS跨站扫描举例。
2.1 sql注入漏洞扫描
SQL注入攻击是一种注入攻击,它将SQL命令注入到数据层输入,从而影响执行预定义的SQL命令;通过控制部分SQL语句,攻击者可以查询数据库中任何自己需要的数据,利用数据库的一些特性,可以直接获取数据库服务器的系统权限。
首先,判断接口是否存在注入点,如:
- 若参数ID为数字,加减运算判断是否存在数字型注入;
- 参数后加单双引号,判断返回结果是否报错;
- 添加注释符判断前后是否有报错:如id=1' --+ 或 id=1" --+或id=1' #或id=1" --+;
- 有些参数可能在括号里面,所以也可以在参数后面加单双引号和括号,如id=1') --+或 id=1") --+或id=1') #或id=1") --+;
- 参数后面跟or 或者and,判断返回结果是否有变化,如1' or 'a'='a或者and 'a'='a或者1' or 'a'='b或者1' or '1'='2;
- 也可以考虑时间延迟的方法判断是否存在注入,如 1’ and sleep(5)。
然后对存在注入漏洞的点利用联合查询一步步获取信息,如:
- 查询数据库名:id=0' union select NULL,database(),NULL --+ ;
- 爆库名:id=0' union select null,groupconcat(schemaname),null from information_schema.schemata --+;
- 爆表名:id=0' union select null,groupconcat(tablename),null from informationtables where tableschema='security' --+;
- 爆字段名:id=0' union select null,groupconcat(columnname),null from informationcolumns where tableschema='security' and table_name='users' --+;
或者通过报错回显查询结果,如:
- 回显数据库名:and extractvalue(1,concat(0x7e,(select database())));
- 回显表名:<br>and extractvalue(1,concat(0x7e,(select groupconcat(tablename) from informationtables where tableschema='security' ))) ;
- 回显列名:<br>and extractvalue(1,concat(0x7e,(select groupconcat(columnname) from informationcolumns where tableschema='security' and table_name='users')))。
2.2 文件包含漏洞扫描
服务器通过PHP的特性(函数)去包含任意文件时,由于要包含的这个文件来源过滤不严,从而可以去包含一个恶意文件,非法用户可以构造这个恶意文件来达到恶意的目的,如读取目标主机上的其他文件,远程文件包含可运行的PHP木马,包含一个创建文件的PHP文件,本地文件包含等。
- Include:包含并运行指定文件,当包含外部文件发生错误时,系统给出警告,但整个php文件继续执行;
- Require:跟include唯一不同的是,当产生错误时候,include下面继续运行而require停止运行了;
- Include_once:这个函数跟include函数作用几乎相同,只是他在导入函数之前先检测下该文件是否被导入,如果已经执行一遍那么就不重复执行了;
- Requireonce:这个函数跟require的区别 跟上面所讲的include和includeonce一样。
2.3 XSS跨站漏洞
跨站脚本攻击是指恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该网页时,嵌入网页中的Script代码会被执行,从而达到恶意攻击用户的目的。与正常请求相比,XSS请求也具备明显的文本特征,如<script>alert(0)</script>,<img src=0 onerror=alert(0)>等。
二. 规则模型
扫描器检测与Web攻击检测不同之处在于,扫描是一种持续的行为,我们通过对扫描器持续一段时间的请求进行聚合分析,而Web攻击检测则是把每条请求作为一次独立的事件来判断是否为Web攻击。扫描器在请求不存在的资源时往往会返回状态码404,但实际生产环境中并非如此。尤其是作为电商企业,希望被正面的搜索引擎抓取,返回404的这种方式会对SEO搜索引擎优化产生不利影响,因此多数域名针对这种请求会做3XX的跳转。总体来说,大量返回404的请求往往都是盲扫请求,但仍有大量盲扫请求返回状态码并非404。这里依赖Web请求日志,在一定时间被仅对请求url文本特征进行分析,来识别扫描器。
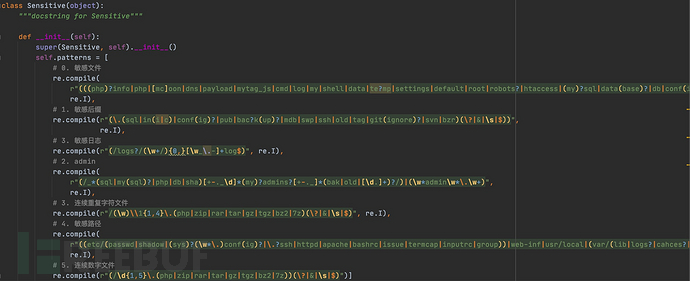
1 正则提取
敏感内容扫描器往往会请求敏感路径、敏感文件等信息,因此首先收集这些信息,然后用正则去匹配这些内容。这里分别按照敏感信息的类型进行分类:
2 正则优化
正则顺序优化:按照Sensitive类的定义,当url匹配到关键内容后即返回匹配内容,跳出正则过滤的循环。因此,为了进一步降低性能的消耗,将生产环境中命中频率最高的正则放在最前面,命中率低的正则放在靠后位置。
单条正则调优:由于正则匹配搜索的优先级为由左向右,因此将生产环境中命中频率最高的放在左边,最低的放在最右边。
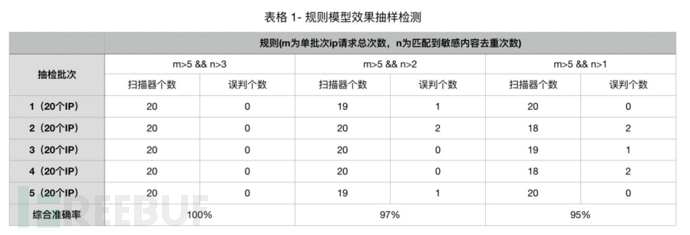
3 准确率和召回率评估
评估方式:模型部署在准实时分布式计算平台,按每分钟进行聚合,并将检测到的扫描器数据作为Log日志打印。根据Yarn日志输出的扫描器IP和检测到的请求时间在云迹进行抽样验证。
三. 统计特征ML模型
扫描器请求和正常请求之间除了文本特征以外,在状态码、url长度、所携带ua的混乱度及访问域名的混乱度等也存在一定差异性。因此提取命中关键词次数及上述特征,结合WAF正常日志和规则检测到的扫描器日志形成黑白样本,进一步训练ML模型。
1 特征提取
关键词提取:搜集网上常见的集中扫描器提取敏感内容字典,并结合规则模型识别的扫描器日志加以补充。进一步随机提取全网流量作为白样本对扫描器关键词库进行匹配,并将白样本中大量存在的关键词剔除,组成关键词库。
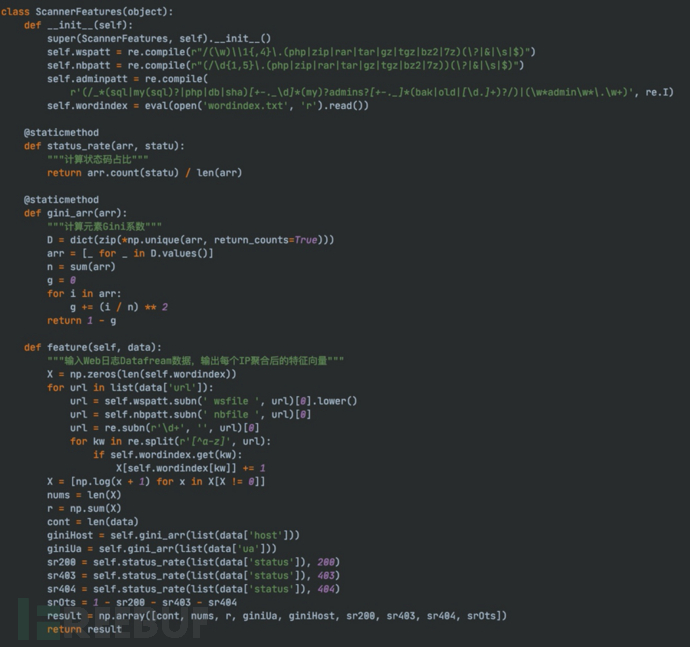
2 特征工程
除了关键词系数特征,同时还分别提取了请求次数、敏感词个数、敏感词威胁系数、UA混乱度、域名换乱度、状态码等特征占比进行示范。
3 模型评估
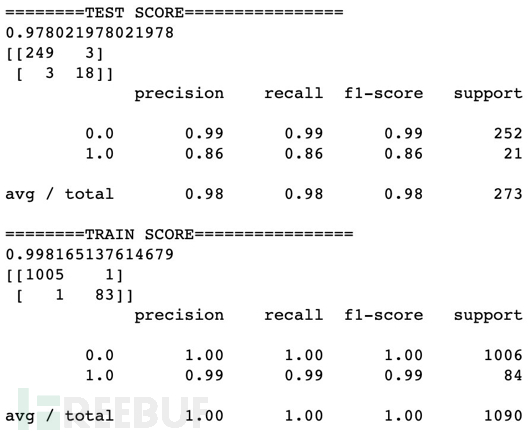
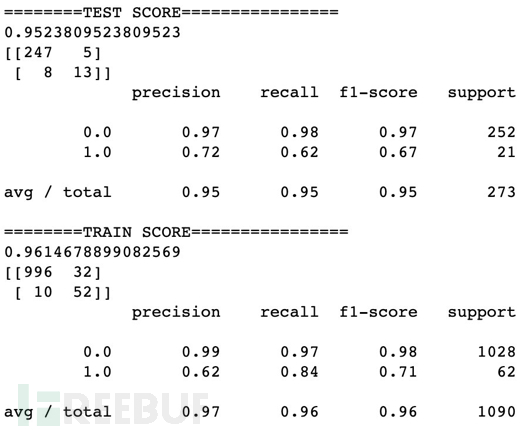
对规则模型采集的黑样本及Web日志白样本进行逐个人为验证并打标,进而训练随机森林模型、和MLP模型分别用召回率、准确率和F1得分进行评估。模型在训练及表现良好,但测试集中可以看出模型过拟合验证,结构风险太高。无法满足生产环境真实业务场景需求。针对不同的模型通过降低树深度、前后剪植,调整惩罚系数等方式降低模型结构风险造成准确率和召回率降低,左右权衡后效果均未能达到满意效果。
- 随机森林模型评估:
- MLP模型评估
四. 基于n-gram特征提取的MLP模型
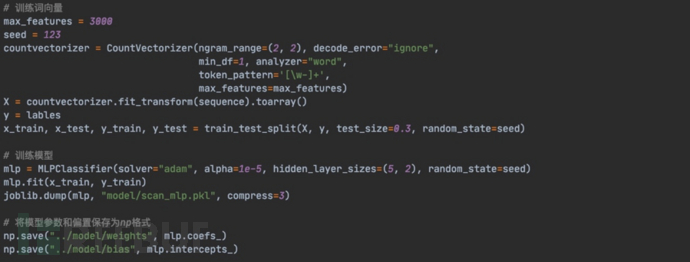
1 模型训练示范
对传统机器学习来说,特征提取是比较繁琐的,需要对业务场景的深入理解。在扫描器识别任务中,我们可以将单个用户连续发起的请求序列拼接到一起作为一个短文本,采取NLP中情感分析的思想,分别训练词向量和分类器模型对扫描器请求序列进行识别。训练过程中需要注意参数n-gram和max_features的调整,这里分别代表取词方式和特征维度。我们先取部分数据实验不同的n-gram参数和max_features参数进行模型训练,并对测试集数据进行评估。在保证模型测试集评分的基础上,max_features越小资源消耗越小。
2 模型评估示范
我们从苏宁应用防火墙(SNWAF)日志中抽取了拼接275019条正常访问序列作为正样本,同时通过SNWAF输出的扫描器IP列表提取拼接出361504条扫描器IP的访问序列作为黑样本,对模型进行训练,取得了比规则模型和统计特征ML模型更好的效果。该方法有更好的成长性,可以随着高质量训练数据的增长进行优化迭代,同时缺点是模型结构相比前两者略复杂,资源消耗也较大。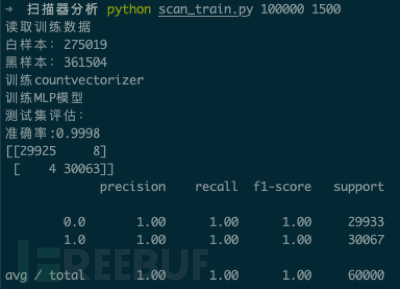
我们分别针对不同的max_features进行了k-flod测试,当max_features=1500时取得了较好的模型表现,交叉验证集平均曲线下面积(AUC)约为0.99。
3 模型工程化部署
实际工程化应用时,我们要将模型部署到分布式大数据计算平台。在实际的代码工程化部署过程中,可能会出现训练模型的环境与分布式环境模块版本不一致或缺少模块导致的模型加载失败问题。针对上述问题,我们采取了一些办法:
- 抽取countvectorizer模型的字典向量,手动构建词向量转换函数
- 重写MLP模型预测代码,将模型预测逻辑函数化
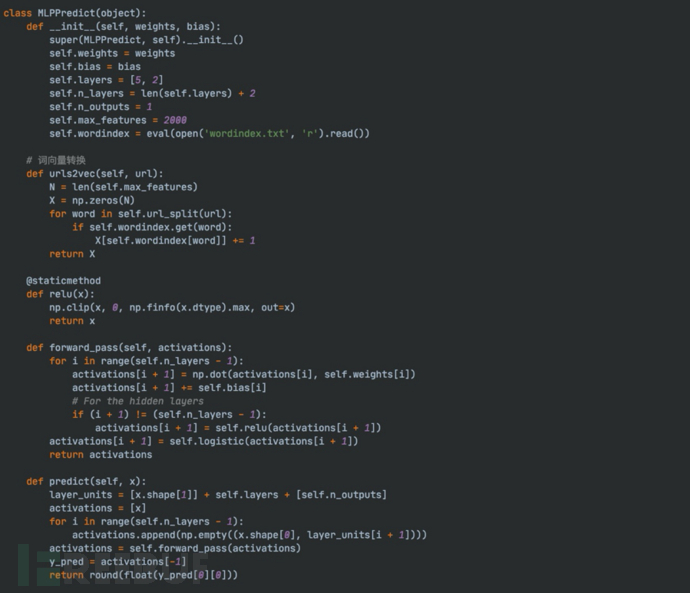
通过本地测试我们发现,采取上述方式与加载模型的输出结果一致,并且预测效率更高。
我们通过创建pyspark-streaming任务,实时消费WAF访问日志对每批次用户的访问日志进行向量化转化后输入预测模型,从而实现扫描器的实时监控,并将检测到的扫描器IP进行告警或根据配置实施访问限制。
五. 总结
本文对各类web扫描器特征进行了梳理和总结,并展示了利用规则模型和统计特征ML模型对扫描器的识别效果。
其中规则模型有天然的优势,所见即所得,可信度高可解释性强,同时满足奥卡姆剃刀简单高效原则,然而只对已知的扫描类型有效,合理的阈值设计非常重要,需要结合实际业务流量来精准分析;基于统计特征的机器学习识别模型的特征提取相对简单,只抽取了少量数据集进行训练,表达能力有限,不能够充分学习到正常请求行为和扫描器行为的区别,有兴趣的同学可以在此基础上进行更加精细化的特征提取以达到识别率的提升;基于n-gram特征提取的机器学习模型具备更好的成长性,可以随着高质量训练样本数据的增加进行优化迭代,同时缺点是相对前两种方式资源消耗较大。
在实际的生产应用中,我们选择AI模型的落地,需要根据企业的数据规模、资源情况和需求标准来选择适合自己场景的模型和方式,最适合的才是最好的。
由于本人能力有限,如有不足之处还望指正,看官若有其他新颖检测思路欢迎一起交流,互通有无。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者