


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
随着现代技术的发展,互联网已经渗入到人类社会的各个领域,网络服务在吸引电商提供个性化的服务的同时,也引来了网络机器人(web bot)的访问。异常访问或者僵尸网络的攻击服务、盗取信息等行为不仅浪费了资源也严重威胁了网络安全。如何能利用少量标注数据准确的识别出异常访问是一直以来待解决的问题。本次研究利用一小时的日志文件通过半监督聚类的方法找到异常访问的相似性,然后对一天的日志进行实验和分析。实验结果表明半监督聚类的方法是可行且相对准确的。
网络机器人,也叫网络爬虫(web crawler),是一种自动抓取和分析网页的后台程序。善意的爬虫,通常出于合法的目的并且遵守网站协议只对各别网站进行合法访问。比如谷歌的搜索引擎爬虫,每隔几天对全网的网页合法抓取一遍,供大家查阅,这是一个善意爬虫。相对的,恶意爬虫或僵尸网络被不法分子用于攻击服务器、发送垃圾邮件、窃取用户信息等,这些行为对网络安全造成了较大的威胁。恶意爬虫经常改变“user agent”来掩饰自己,所以仅靠“user agent”关键字来识别是远远不够的。
行为分析是更为可靠的识别方法,它通过分析每个IP访问的行为来判断是用户还是网络机器人。
监督训练,即利用被标记好的日志来训练分类模型,是目前常用的识别网络机器人的方法。但是现实生活中很难得到大量标记好的数据,人工标注又消耗时间和人力。因此如果利用无标签数据来识别异常访问是一个挑战。研究共尝试了两种方法来避免大量的人工标注:
模糊c均值聚类(fuzzy c-means cluster)
半监督k-means聚类
模糊c均值聚类是一种无监督算法,即训练数据无需标注,它通过计算每个对象与C个聚类中心间的加权相似性测度,对目标函数进行迭代最小化,以确定每个对象的最佳类别。跟传统聚类算法不同的是,模糊c均值聚类中的隶属度不是0和1,而是一个范围[0,1],也就是说一个对象可以以不同的程度同时属于多个类。通过实验,模糊c均值聚类效果并不理想,于是我们引入了半监督方法,即只需要一小部分标注的数据。我们利用规则标注了一小部分数据并将他们分成两类:bot类或者human类。经过测试,k-means聚类取得了较为理想的结果。在这个算法中隶属度只有两个取值:0和1。
方法
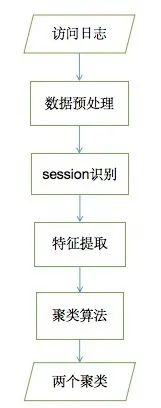
1. 方法框架
本报告所采用方法大概框架如下,包含以下几步:(1)对日志文件的数据预处理;(2)session识别;(3)对每一个session提取特征向量;(4)用聚类算法对每个session进行分类。下面将详细介绍每个步骤。
2. 数据预处理
本项目的输入数据是访问日志(access log)。访问日志记录网站运营中的访问情况,通过它可以清楚地得知用户IP、访问时间、访问时长、操作系统、浏览器、user_agent,访问是否成功等。为了方便分析和读取,访问日志存储在txt文件中。我们整理出的日志包含26个字段。
3. session识别
在调研中,一个session被定义为一系列来自同一用户的HTTP请求。在别的研究中,HTTP请求被放在同一个session里如果它们来自同一IP,有着同样的user agent并且连续时间不超过30分钟。由于本次研究主要为了验证无监督或者半监督聚类算法是否可用,所以将session的定义简化为来自同一IP的同一天的所有HTTP请求。于是基于session的机器人检测问题可以被定义为:给定一系列session,根据它们的特征标记为bot或者human。
Session分析器是由python写的,它可以读取txt格式的日志文件,将日志文件分成以IP为单位的不同session文件(txt格式)。每个session文件里的请求都按时间排序。
4. 特征提取
为了保证提取的特征具有普遍性,也就是说特征在任何网站的访问日志里都可以获取,我们首先将特征定义为十维向量,对应表格中列号0到列号9。但是模糊c均值聚类算法结果显示这十维向量是无法发现user agent或者中有明显bot指向的session。有一些善意爬虫会在user agent中标出自己是机器人,比如Googlebot和Baiduspider,还有些善意爬虫会在爬取网站数据前访问robots.txt文件来查看该网站哪些数据可以提取再对网站进行合法访问。同时,我们注意到爬虫往往会爬取一个目录下的所有文件,这是一个明显的爬虫行为。
综上,我们又加入了三维向量特征,对应表格中的列号10到列号12。在为每个session提取完下面十三维特征后,布尔值被表示为0或者1,数字值特征会被归一化。
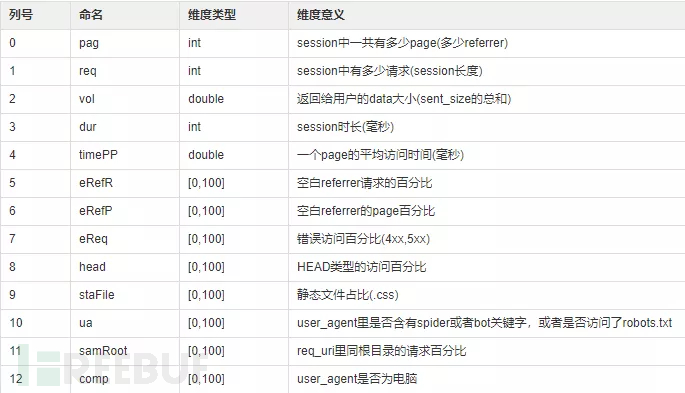
我们的特征提取器也是由python完成。所有的特征被存储在一个Nx13维的矩阵里,这里N代表session的数量,每一行对应一个session的特征。
5. 聚类算法
在上一步骤里,我们已经获得了所有session的特征向量,接下来就是对这些向量进行分类。传统的方法是利用标记好的数据训练一个二分类器来判断输入session是人还是机器人,然而在现实生活中是很难获得大量标记好的session数据,因为人工标注耗时耗力,所以我们第一个尝试的方法就是无监督模糊c均值聚类算法。
5.1 模糊c均值聚类
模糊c均值聚类算法首先是有Dunn提出,经过Bezdek等完善和推广的,其基本思想是根据对象与C个聚类中心间的加权相似性测度,对目标函数进行迭代最小化,以确定其最佳的类别,其算法步骤如下:

无监督模糊c均值聚类算法是最近很流行的分类方法,“模糊”的意思是对象的隶属度是一个范围[0,1]。因为现实生活中有很多分类的边界是模糊的,比如身高,对于同一身高数据180cm,有些人会觉得它属于高类,有些人会觉得它属于中等类。
无监督模糊c均值聚类通过改变隶属度取值来解决模糊分类边界的问题,因此它具有以下优点:
不需要标记数据;
改变了传统分类的时候非此即彼的现象,一个对象可以以不同的程度同时属于多个类。
5.2 半监督k-means聚类
半监督k-means聚类和k-means 聚类不同的是加入了一小部分有标记的数据。半监督k-means 聚类会根据这些标记的数据初始化均值点,每次迭代不改变种子样本的隶属关系。算法的流程大概如下:

为了获得小部分标记数据,我们首先利用规则标记human。一个session必须同时满足如下要求才可以被标记成human:
user_agent中不包含bot或spider
req_uri不包含robots.txt
req_uri同根目录下的访问不超过百分之三十,并且总访问页面不超过15
然后再利用与上述相反的规则和人工检查标记了bot。标记数据要保持平衡,即bot数量和human数量要相差不大。
实验结果
1. 实验设置
所有的实验都是在Anaconda python 3.7.6的环境下运行。
模糊c均值聚类使用的训练数据ds1是“xxxxx.org-acess-2020042710.log” 半监督k-means cluster使用的训练数据ds2是“xxxxx.org-access-2020052115.log”。测试数据ds3是“xxxxx.org-access-20200602.log”。由于聚类算法不是模型,因此不能利用训练数据学习一个模型,然后应用到测试数据上。所以,这里的训练数据指的是观察聚类效果的数据,测试数据是测试聚类在新数据上的应用效果。
2. 实验结果
2.1 模糊c均值聚类
首先,Session分析器将ds1分成了484545个session,即有484545个不同IP地址。再利用特征提取器对这484545个session提取了十维向量(方法中提到过)。为了方便验证结果,我们找到所有user_agent包含bot或者spider的session,共2006个,分布结果如下: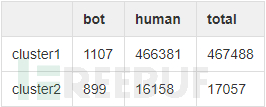
可以看出,在两个聚类中,bot都存在且数量没有明显区别。我们分析结果不理想的原因可能有两点:
提取的特征不够明显的区别出bot和human
非监督模糊法对类别较少的情况,不适用
为了验证第一个原因,我们将特征扩展到更多维,可是效果并没有明显改进。为了解决第二个原因,我们引入了半监督k-means聚类。
2.2 半监督k-means聚类
Session分析器将ds2分成了448722个session。再利用特征提取器对这448722个session提取了十三维向量。为了获得标记数据,我们利用规则标记了3393个bot,3965个human。在未标记的441364个数据中,识别出10个bot。经过人工检验,这10个session都可以算作可疑IP。
为了避免每次对新数据都要重新标注,我们将ds2的结果保存下来并用做标记数据,也就是说,在以后的应用中,新数据将作为未标记数据,ds2的结果将用作为标记数据。
为了进一步验证半监督k-means聚类算法是否可以应用在新数据上,我们将ds3作为未标记的测试数据。由于ds3文件较大,我们将其分成14个子日志文件。
在本调研中,以第一个子日志文件的结果为例。第一个子日志文件共有336623个session,检测出6333个被标记为bot的session,其中6311个在user_agent中有bot或spider关键词,22个需要被人工检查。经过初步观察,这22个session都有可疑的行为。
结论和研究展望
本次调研比较了两种聚类算法:模糊c均值聚类和半监督k-means聚类。通过比较,半监督k-means聚类更适用。同时,本次调研也总结出具有普遍性的十三维特征向量,保证了特征提取在任何访问日志上都可以获取。未来的研究方向是更好的定义session,给session加入时间限定。同时,我们的方法并没有在其他网站上进行测试,还需要进一步实验和改进。
ps. 知道创宇云安全招募深度学习工程师,了解详情或有意者可私信。
作者:李思锐@知道创宇云安全
- 0 文章数
- 0 关注者