


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
Tensorflow神经网络的数据存储中都使用张量(Tensor),张量具体是什么?
张量是TensorFlow数据的中心单元,张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。张量是矩阵向任意维度的推广。
属性
张量是由以下三个关键属性来定义的。
秩(Rank)
Tensor对象由原始数据组成的多维的数组,Tensor的rank(秩)其实是表示数组的维数,如下所示的tensor例子:
Rank | 数学实例 | Python 例子 |
0 | 标量 (点) | 666 |
1 | 向量(直线) | [6,6] |
2 | 矩阵(平面) | [[6,6,6],[6,6,6]] |
3 | 立体 (图片) | [[[6,6],[6,6]] , [[6,6],[6,6]]] |
n | n阶 (立体+时间轴,可参考下图) | [[[[[........]]]]] |
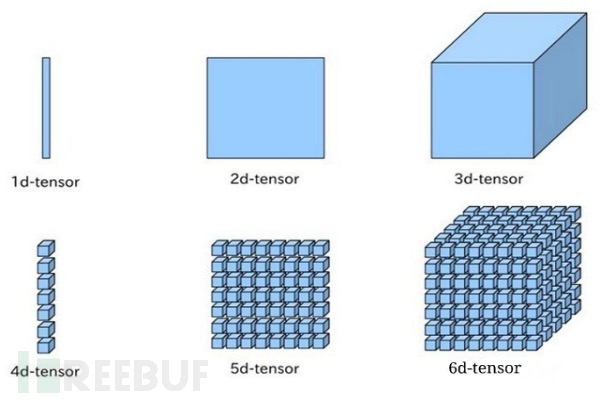
实例
本文的运行环境为:
python=2.7.18
tensorflow=1.14.0
标量(0D 张量)
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量)。如一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。
tf.constant(1)
<tf.Tensor 'Const_4:0' shape=() dtype=int32>
向量(1D 张量)
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。
tf.constant([1],name="const_1d")
<tf.Tensor 'const_1d_4:0' shape=(1,) dtype=int32>
矩阵(2D 张量)
向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和列)。可以将直观地理解为数字组成的矩形网格。
tf.constant([[1,2],[3,4]],name="const_2d")
<tf.Tensor 'const_2d:0' shape=(2, 2) dtype=int32>
图片(3D 张量)
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体。常见的图片是包含RGBA等颜色通道的,每个通道是一个矩阵,所以图片也是3D张量的一种。
注意上面说的是一张图片,而tensorflow中的图片数据集是4D张量,还包括了一维数据集大小。如MNIST特征数据集的形状为(60000,28,28,1),60000代表60000张图片,两个28代表28*28的图片尺寸,1代表只有灰度这一个通道
tf.constant([[[1,2],[3,4]],[[1,2],[3,4]]],name="const_3d")
<tf.Tensor 'const_3d:0' shape=(2, 2, 2) dtype=int32>
视频(4~nD张量)
将多个 3D 张量组合成一个数组,可以创建一个 4D 张量,以此类推。视频是多帧图片的组合,图片是3D张量,时间轴就可以作为第四维度,这样,视频也就是4D张量的一种。
同样需要注意,tensorflow中的视频数据集是5D张量,也包括了一维数据集大小。
形状(Shape)
为了描述Tensor每一维数组的长度,所以定义了Shape概念。既可以描述每一维的长度,又以描述Tensor的维数Rank,其中Rank = len(Shape)
Rank | Shape | Dimension number | Example |
0 | [] | 0-D | [] |
1 | [D0] | 1-D | [6]:表示一个向量有6个元素 |
2 | [D0, D1] | 2-D | [6, 6]:表示一个矩阵,共有6 * 6个元素 |
3 | [D0, D1, D2] | 3-D | [6, 6, 6]:表示一个三维矩阵,总共有6 * 6 * 6个元素 |
n | [D0, D1, D2,… Dn-1] | n-D | [6......6]:表示一个n维矩阵 |
类型(Data type)
每个Tensor都有有一个数据类型属性,你可以为一个张量指定下列数据类型中的任意一个类型,但是一个Tensor中所有元素的类型必须相同。
数据类型 | Python 类型 | 描述 |
DT_FLOAT | tf.float32 | 32 位浮点数. |
DT_DOUBLE | tf.float64 | 64 位浮点数. |
DT_INT64 | tf.int64 | 64 位有符号整型. |
DT_INT32 | tf.int32 | 32 位有符号整型. |
DT_INT16 | tf.int16 | 16 位有符号整型. |
DT_INT8 | tf.int8 | 8 位有符号整型. |
DT_UINT8 | tf.uint8 | 8 位无符号整型. |
DT_STRING | tf.string | 可变长度的字节数组.每一个张量元素都是一个字节数组. |
DT_BOOL | tf.bool | 布尔型. |
DT_COMPLEX64 | tf.complex64 | 由两个32位浮点数组成的复数:实数和虚数. |
DT_QINT32 | tf.qint32 | 用于量化Ops的32位有符号整型. |
DT_QINT8 | tf.qint8 | 用于量化Ops的8位有符号整型. |
DT_QUINT8 | tf.quint8 | 用于量化Ops的8位无符号整型. |
数据节点
常量(constant)
constant是tensorflow的常量节点,通过constant方法创建,其是计算图中的起始节点,是传入数据。
创建方式:
cons = tf.constant(value=[1,2],dtype=tf.float32,shape=(1,2),name='testConstant',verify_shape=False)1
参数说明:
value:初始值,必填,必须是一个张量(1或[1,2,3]或[[1,2,3],[2,2,3]]或……)。
dtype:数据类型,选填,默认为value的数据类型,传入参数为tensotflow下的枚举值(float32,float64….)。
shape:数据形状,选填,默认为value的shape,设置时不得比value小,可以比value阶数,纬度更高,超过部分按value提供最后一个数字填充。
name:常量,选填,默认值不重复,根据创建顺序为(Const,Const_1,Const_2…….)。
verify_shape:是否验证value的shape和指定shape相符,若设为True则进行验证,不相符时会抛出异常。
cons = tf.constant(1)
print(cons)
withtf.Session() as sess:
print(sess.run(cons))
output:
Tensor("Const:0", shape=(), dtype=int32)
1
这里我们发现,第一次定义cons之后,cons为Tensor的对象,并没有赋值为1
在调用sess.run之后,才赋值为1
占位符(placeholder)
placeholder是Tensorflow的占位符节点,由placeholder创建,它既可以看成常量也可以看成变量。placeholder用于在会话运行时动态提供输入数据。placeholder相当于定义了一个位置,在这个位置上的数据在程序运行时再指定。数据内容是由用户在调用run方法时传递的,也可以将placeholder理解为一种形式参数,很像符号执行中的Z3求解。
之所以说placeholder既可以看成常量也可以看成变量, 是因为在将数据填入到占位符后,其值在图中就不能再做修改(即不能通过assign等函数修改值);但是在图之外又可以不断传入不同的值。
创建方式:
x = tf.placeholder(dtype=tf.float32,shape=[144,10],name = 'x')
参数说明:
dtype:数据类型,必填,默认为value的数据类型,传入参数为tensorflow下的枚举值(float32,float64…..)。
shape:数据类型,选填,不填则随传入数据的形状自行变动,可以在多次调用中传入不同形状的数据。
name:常量名,选填,默认值不重复,根据创建顺序为(Placeholder,Placeholder_1,Placeholder_2…….).
示例代码:
placeholder1 = tf.placeholder(tf.float32)
print(placeholder1)
#:Tensor("Placeholder_1:0", dtype=float32)
withtf.Session() as sess:
print(session.run(placeholder1))
#:ERROR
可以发现,sess.run直接调用placeholder1会报错
withtf.Session() as sess:
print(sess.run(placeholder1,feed_dict={placeholder1: 6.6}))
#6.6
seed.run中,feed_dict是一个字典,在字典中需要给出每个用到的占位符的取值,如果参与运算的placeholder没有被指定取值,那么程序就会报错。
变量(Variable)
variable是tensorflow的变量节点,通过Variable方法创建,并且需要传递初始值,在使用前需要通过tensorflow方法进行初始化。
创建方式:
v1 = tf.Variable(value=tf.zeros([3, 10]), dtype=tf.float64, name='v1')
参数说明:
__init__(
initial_value=None, # Tensor或可转换为Tensor的Python对象,它是Variable的初始值。除非validate_shape设置为False,否则初始值必须具有指定的形状。也可以不指定初始值,在调用时返回初始值。在这种情况下,必须指定dtype。
trainable=True, # 如果为True,则默认值也会将变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES中。此集合用作Optimizer类使用的默认变量列表。
collections=None, # 图表集合键列表。新变量将添加到这些集合中。默认为[GraphKeys.GLOBAL_VARIABLES]。
validate_shape=True, # 如果为False,则允许使用未知形状的值初始化变量。如果为True,则默认为initial_value的形状必须已知。
caching_device=None, # 可选设备字符串,描述缓存变量供读取的位置。默认为Variable的设备。如果不是None,则在其他台设备上缓存。典型用法是在使用变量驻留的Ops的设备上进行缓存,以通过Switch和其他条件语句进行重复数据删除。
name=None, # 变量的可选名称。默认为“Variable”并获取自动去重(Variable_1,Variable_2....)
variable_def=None, # VariableDef协议缓冲区。如果不是None,引用图中已存在的变量节点容重新创建Variable对象。图表未更改。 variable_def和其他参数是互斥的。
dtype=None, # 如果设置,则initial_value将转换为给定类型。如果为None,则保留数据类型(如果initial_value为Tensor),或者由convert_to_tensor决定。
expected_shape=None, # TensorShape。如果设置,则initial_value应具有此形状。
import_scope=None, # 可选字符串。要添加到变量的名称范围。仅在从协议缓冲区初始化时使用。
constraint=None, # 由优化器更新后应用于变量的可选投影函数(例如,用于实现层权重的范数约束或值约束)。该函数以未投影的Tensor作为输入,并返回Tensor的投影值(必须具有相同的形状)。在进行异步分布式培训时,使用约束是不安全的。
use_resource=None, # 是否使用资源变量。
synchronization=tf.VariableSynchronization.AUTO, # 未使用
aggregation=tf.VariableAggregation.NONE # 未使用
)
在使用TensorFlow来训练计算图的时候,我们可以通过Variable来增加计算图的参数,我们可以约束参数的类型和值,如线性模型y=a*x+b,需要通过variable来增加a和b两个参数。
要注意constant和Variable的区别,在调用tf.constant()的时候,它们就已经被初始化了,而且它们的值永远都不会变。而tf.Variable不同,在使用这个方法的时候并没有初始化。可以在sess.run时初始化variable参数
var1 = tf.Variable(10)
print(var1)
#:<tf.Variable 'Variable_5:0' shape=() dtype=int32_ref>
withtf.Session() as sess:
print(sess.run(var1,{var1:123}))
#:123
区别
tf.Variable:表示变量,运行时可以改变。主要用于一些可训练变量(trainable variables),比如模型的权重(weights,W)或者偏置值(bias);
声明时,必须提供初始值。
运行时,必须初始化。 可以用sess.run(tf.global_variables_initializer())初始化所有变量
tf.placeholder:表示张量(最少有一维,即最少含有一组中括号),运行时不可改变。用于得到传递进来的真实的训练样本:
声明时,不指定初始值
运行时,需要赋值。 通过 Session.run 的函数的 feed_dict 参数指定
tf.constan:表示常量,运行时不可改变
- 0 文章数
- 0 关注者