


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
当企业需要建设独立的数据仓库系统来支撑BI和分析业务时,有了“数据湖+数据仓库”的混合架构。但混合架构带来了更高的建设成本、管理成本和业务开发成本。随着大数据技术的发展,通过在数据湖层增加分布式事务、元数据管理、极致的SQL性能、SQL和数据API接口能力,企业可以基于统一的架构来同时支持数据湖和数据仓库的业务,这就是湖仓一体架构。本篇继续介绍星环科技Inceptor和Apache Delta Lake。

— 星环科技Inceptor—
星环科技 Inceptor是一个分布式的关系型分析引擎,于2013年开始研发,主要用于ODS、数据湖以及其他结构化数据的分析型业务场景。Inceptor支持绝大部分ANSI 92、99、2003 SQL标准,兼容传统关系型数据库方言,如Oracle、IBM DB2、Teradata等,并且支持存储过程。2014年起,国内一些银行客户开始尝试将一些原本在DB2上一些性能不足的数据加工业务,迁移到Inceptor上,而这些原本构建在关系型数据库上的数据任务有大量的并发update、delete的需求,并且存在多个数据链路加工一个结果表的情况,因此有很强的并发事务性能要求。此外,由于用户不仅期望完成数据批处理业务从关系数据库迁移到Hadoop平台上,并且期望性能上有数量级上的提升,因此星环科技从2014年开始研发基于HDFS的分布式事务机制,以支撑部分数据仓库的业务场景,到2016年随着Inceptor 4.3版本正式发布了相关的技术,并后续几年在数百个金融行业用户落地生产,技术成熟度已经金融级要求。
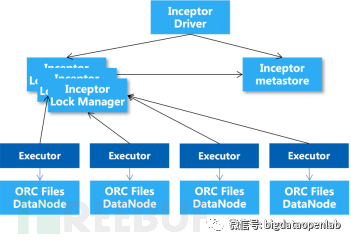
Inceptor的总体架构图如上,因为ORC是列式存储,有非常好的统计分析性能,我们选择基于ORC文件格式来二次开发分布式系统。由于HDFS也不支持文件的random access和文件内的事务操作,因此对数据的并发update和delete,我们采用了MVCC机制,每次提交的数据更新,不直接对数据文件进行改写,而是对数据文件增加一个相应的新版本,一个事务内的所有的数据操作都写入一个delta文件中。读取数据的时候再将所有文件数据读入内存,并且在内存中对多个文件中的同一个数据按照事务顺序和可见性来做合并,也就是Merge on Read机制。
需要强调一点,数据仓库上都是数据批处理加工,批处理的数据业务每个SQL都可能操作的数据量比较大,单个的SQL操作需要的延时可能是几十秒甚至是分钟级以上,它对分布式事务的性能要求是几十到几百TPS,而不是分布式数据库面向交易型业务需要的几万甚至更高的TPS。锁冲突是批处理情况下并发性能的一个主要瓶颈点。如果同时有多个ETL任务在加工一个数据表,那么这个表很有可能就会出现锁冲突,从而导致数据任务之间出现锁等待而拖慢最终加工节奏。为了解决性能问题,我们开发了一个独立的Lock Manager来管理分布式事务的产生与可见性判断,同时锁的粒度包括Database、Table和Partition三个粒度,这样就减少了很多的不必要的锁冲突问题。
此外,在数仓加工过程中,很多表既是上一个加工任务的结果表,也是其他数据任务的数据源头,因此也会存在读写冲突问题,部分情况下会导致并发受限。为了解决这个问题,我们引入快照(snapshot)机制和Serializable Snapshot的隔离级别,数据表的读操作可以直接读取某个快照,这样就无需跟写操作产生事务冲突。在我们的设计中,快照不需要持久化,无需增加大量的物理存储,而是一个轻量级的、全局一致的逻辑概念,在事务处理中可以快速判断数据的某版本应当包含还是排除。
在事务的隔离性上,Inceptor支持Read uncommitted、Read committed、Repeatable reads、Serializable和Serializable Snapshot这5种隔离级别。在并发控制技术上,Inceptor 提供了悲观和乐观两类可序列化隔离级别:基于严格的两阶段锁的串行化隔离级别和基于快照的序列化隔离级别。用户可以根据业务场景选择适合的隔离级别类型。严格的两阶段锁的序列化隔离(S2PL Based Serializable Isolation)是一种悲观的并发控制技术,其主要特点是先获得锁,再处理读写,直到事务提交完成后才释放所有锁。它的实现比较方便,主要难点是处理好死锁问题(通过环检测解决)。该技术的读写无法并发,因此事务处理的并发性能较差。而可序列化快照隔离(Serializable Snapshot Isolation)能够提高事务处理的并发性能,采用了基于乐观锁的可序列化快照隔离,该技术的优势是不会产生两阶段锁技术中读写操作互相阻塞的情况,使得读写互不阻塞,提高了并发度。虽然快照隔离也不会出现脏读、不可重复读、幻读现象,但它并不能保证可序列化,在处理并发的事务时,仍然可能因为不满足约束(Constraints)而发生异常,称之为写偏序问题(Write Skew)。为解决写偏序问题,Inceptor引入对可序列化快照冲突的检查,增加了对快照隔离级别下事务间的读写依赖关系中环的检测来发现相关的冲突问题并abort异常的事务。
如上文所述,Inceptor在分布式事务的并发能力、事务隔离性、SQL性能等方面的技术积累比较完整,此外从2016年就开始被金融业大量采用,在数据仓库的场景下Inceptor的成熟度比较高。由于Inceptor设计上不是为了机器学习的场景,因此没有提供直接给机器学习框架使用的数据API层。另外,Inceptor也没有单独设计面向实时数据写入的架构,也不能有效的支持流批一体的架构,不过星环科技在分布式数据库ArgoDB中解决了流批一体的需求问题。
— Apache Delta Lake —
由于Databricks Cloud上大量用户运行机器学习任务,因此Databricks的主要设计目标包括:
- 优秀的SQL性能
数据分析的性能是BI和分析类软件的核心要求,因此需要采用列式文件格式(如Parquet等)等适合统计分析的格式,以及向量式计算引擎、数据访问缓存、层级化数据存储(如冷热数据分离存储等技术)等技术,来提升数据湖内SQL统计分析的性能,达到数据仓库的技术要求 - 提供分布式事务和schema支持
数据湖的存储多以文件方式,采用的schemaless方式,这位数据分析提供了灵活性,但是就无法实现数据库的ACID管理能力。Delta Lake完善了文件存储,提供严格的数据库schema机制,之后研发了一套基于MVCC的多版本事务机制,这样就进一步提供数据库的ACID 语义,并且支持高并发的update和delete的SQL操作。此外,Delta Lake基于开放的数据格式(Parquet),这样既可以直接操作HDFS,也让其他计算引擎可以访问相关的数据,提高了生态兼容性。
- 灵活对接机器学习任务和探索式分析的数据API
机器学习和AI训练任务对Databricks的核心业务场景,因此Delta Lake在设计上非常注重保证的这类业务的支撑,其不仅提供DataFrame API,还支持Python、R等编程语言接口,还强化了对Spark MLlib、SparkR、Pandas等机器学习框架的整合。
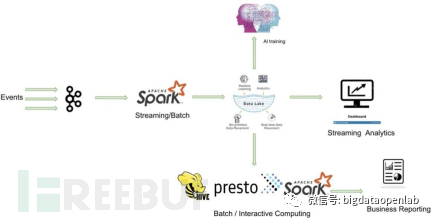
基于以上能力,结合Spark的计算能力和Delta lake的存储能力,就可以实现完全基于Databricks存算技术的数据架构,可以支持BI统计分析、实时分析以及机器学习任务,另外Delta Lake基于开放的数据存储格式,也可以对接其他的计算引擎如Presto做交互式分析。
在项目的初始设计目标上,Hudi侧重于高并发的update/delete性能,Iceberg侧重于大量数据情况下的查询性能,而Delta Lake设计的核心是为了更好的在一个存储上同时支持实时计算和离线计算。通过与Spark Structured Streaming的深入整合,delta table不仅可以做Streaming的数据源,也可以直接作为Streaming的目标表,此外还可以保证Exactly-Once语义。Delta社区结合multi-hop数据架构设计了一套流批一体的参考架构设计,能够做到类似Kappa架构的一份数据存储响应流批两种场景需求。
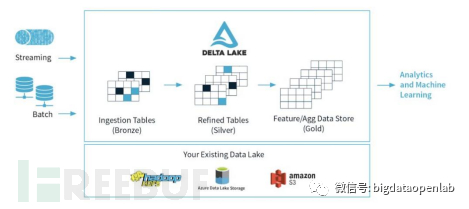
由于Databricks对Delta Lake的开源相对受限,部分功能需要依赖Databricks File System以及Engine才能比较好,因此社区里面的关注度上不如Huid和Iceberg。此外,设计上Delta Lake并不提供主键,因此高并发的update/delete不如Hudi,也不提供类似Iceberg的元数据级别的查询优化,因此查询性能上可能不如Iceberg,但是Delta Lake强调的是结合Spark形成的流批一体的数据架构以及对机器学习类应用的原生API级别的支持,可适用的业务场景有很好的普遍性。
— 小结—
从时间维度上看,星环科技Inceptor是最早开始探索在数据湖上提供数据仓库能力的产品,并且在2016年即完成产品的规模化上生产,因此产品成熟度较高,尤其是在分布式事务实现的完备性上更是有明显的优势。
Hudi在设计上适合有高并发的update/delete的业务场景,与星环科技Inceptor 类似,这两个技术也都是基于Hadoop提供update、delete的能力,而相对来说,Hudi在分布式事务的实现细节上还需要更多的时间和生产打磨来完善。
Iceberg项目在设计上适合有大量分区但少事务操作的海量数据的分析场景,对互联网类企业比较适合,加上Iceberg在软件设计上做了非常好的抽象,对各种计算引擎的支持比较完备,在partition等优化上做的非常细致,对一些事务性要求不太高的场景还是有很强的吸引力。
Databricks对Delta Lake的开源相对受限,部分功能需要依赖Databricks File System以及Engine才能比较好,因此社区里面的关注度上不如Hudi和Iceberg。Delta Lake在性能上没有突出的设计,在分布式事务的实现上相对比较简单,事务并发和隔离性实现都还处于早期阶段,目前该项目更强调的是结合Spark形成的流批一体的数据架构以及对机器学习类应用的原生API级别的支持。
随着各个项目逐步完成了初始设计目标,他们都想进一步扩大适用场景,也都在进入各自的领域,各个项目的快速发展也推动着湖仓一体架构的快速迭代。
- 0 文章数
- 0 关注者