


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
随着十四五规划中数据经济再次被广泛提及,数据作为生产要素的地位已成为不争的事实。在全面转向数字化的过程中,各行各业已经认识到了数据治理对于数字化的重要性,数据的规范化、数据湖统一存储、大数据平台统一计算、数据经营信息的充分挖掘已经极大地促进了各行业的再次发展。但生产和安全始终是需要相辅相成的。勿在浮沙筑高台,保障生产要素的安全就成为了目前最高关注的话题,且随着社会的发展,人们个人隐私保护意识的提高,使得这一话题进一步受到广泛的关注。这就是今天要说的数据安全!

有需求就会有解决方案。目前已有多种数据安全治理理论,也包括一些最佳实践。各种安全厂商也从自己的视角提出了思路和想法。但有一点却出奇的一致,那就是以数据为中心,切换以往信息安全、网络安全的视角来保障数据的安全。以数据为中心可以简单理解为,以数据的视角,从产生到消亡的全生命周期,围绕数据的存储、流动以及此过程中涉及到的人、权限等多种维度来建设安全架构。这里面绕不开的第一步便是对数据的分类分级。

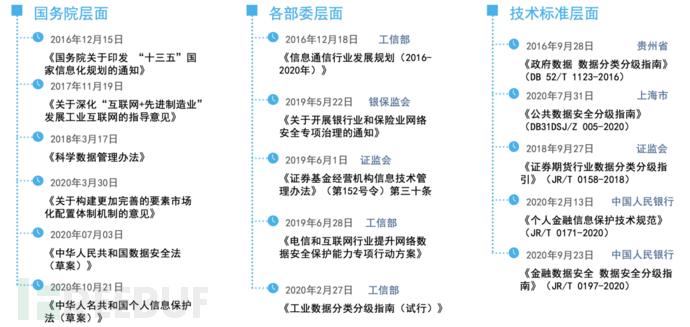
数据分类分级作为数据安全的“桥头堡”,在数据安全治理过程中至关重要,一般企业的数据可以分为公开数据、非公开数据(敏感数据)。为此我们需要把主要精力放在敏感数据的管控上,制定精细化的管控原则。根据不同数据级别,实现不同的安全防护,避免敏感数据泄露给公司造成重大损失。各行各业的分类分级标准虽然如雨后春笋般大量颁布,但在生产落地实践中还需要解决以下的问题(或者避开这些误区)才会迎来最佳的应用效果。
如何下手,分类分级的好处是什么?
企业可优先梳理高敏感等级数据类型的识别规则,在准确绘制出高敏感等级数据的分布情况后,再对次高级数据进行相同操作,以此流程逐步完善企业对全局数据的梳理识别能力,并将企业敏感数据分布地图逐步补全。
有了数据的分布地图和相关数据标签后,就能清楚地知道后期数据安全的建设方向,以此针对不同级别的数据,清楚地梳理管控原则。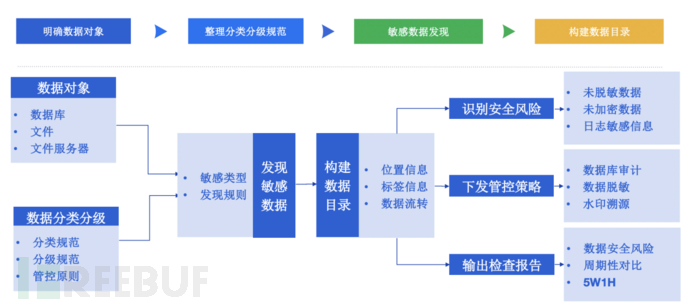
如何落地分类分级规范要求
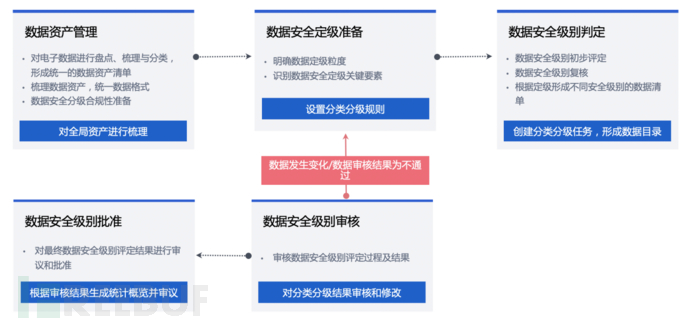
企业在体系构建的初期,由于缺少辅助工具和持续优化的运营经验,面对规范要求中繁杂的数据类型往往无从下手。
首先要建立一个意识,数据安全不是以往常规的在信息安全上的迭代,而是新的建模方式,它是一个长期持续,不断演进的体系。所以单纯的短平快实现必然会对后面造成更大的困扰。即使目前需求是简单的,后期必然也会演进到正规的道路上来,所以需要一个专业化的工具,或者平台来承载。有些行业的数据安全治理方案中也会以自身的业务系统出发,提供独立的系统梳理数据现状以应对监管,也为后期建设打下基础。因此数据敏感标签的 API 化也会是着重考虑的诉求。
规范中分级类型无法跟实际存储对应
规范中一般分级规则是各监管单位、核心企业根据业务模型讨论出来的理想情况。在实际落地过程中发现,某种敏感业务类型是由数十种原子敏感数据组成的,而这些原子类型也会跨多个表来存储,这将给分级类型的识别带来困扰。这也是分类分级逻辑上简单、但落地困难的原因,也正因为如此,才需要专业的系统感知各物理表中的敏感数据比例,充分分析整体数据存储情况来给出智能推断,辅助分类分级达到良好的落地效果。

如何对汇聚融合数据准确打标
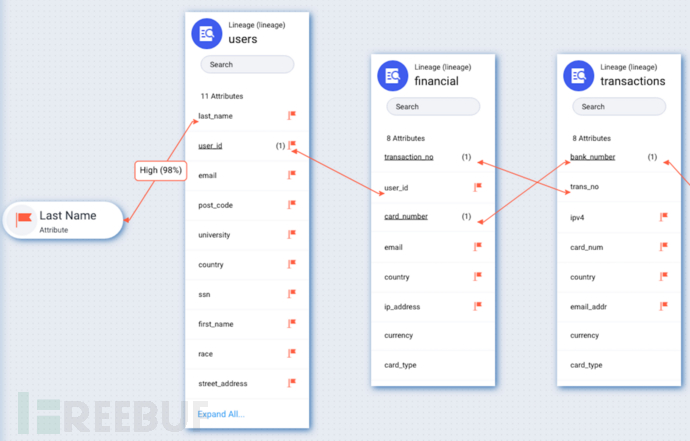
两种或两种以上的低敏感程度类别信息经过组合、关联和分析后可能产生高敏感程度的信息。
——不应当仅从数据类型本身判别其敏感等级,还应当结合与之一同存储,一同使用的其他数据类型分布情况,综合判别其可能存在的最高风险,避免误判漏判。

如何发现业务数据潜在的关系
企业业务正常开展的过程中,可能需要来源于不同部门的多种类型数据共同辅助完成工作,数据的潜在联系无法通过静态存储情况知晓。
——通过数据的实际场景下的组合使用情况进行分析,对组合数据进行合理评估,对相关数据库表通过业务行为进行关联,将潜在业务关联梳理为具体可视化的关系,辅助制定更好的安全策略。
如何对不规则敏感数据发现
真实生产环境中的数据往往并不规则,敏感数据可能潜藏在众多脏数据、非结构化化数据的包围之中。
实际落地过程中,切不可高估了数据治理过程中对数据规范的执行。我们可以肯定数据治理的成果,但做分类分级时还是要抱着“低姿态”切入到工作中来,要考虑到,数据元信息不规范,数据内容不规范,各类型杂糅,敏感数据被分隔,加工。总之不作任何规范假设的前提下,设计发现及分类分级方案,才能使最终效果达到预期。
在技术上通过设置关键数据类型占比的形式于不规则数据中精准定位敏感数据占比较多的数据列,同时可以通过自然语言分析等技术手段对非结构化数据中的敏感数据进行精准分割与识别,提高敏感数据的检出率,减少漏判,充分利用现有技术手段,往往会达到出其不意的效果。
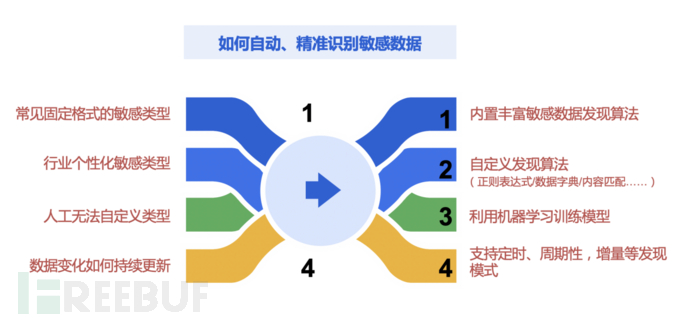
如何对海量数据进行处理
随着企业信息化程度的不断加深,敏感数据量级的发展十分迅猛,又因为企业业务的快速拓展,企业在在对海量数据处理的问题上提出了更高的时效性要求。
——我们面临的永远不是一个小数仓,可能是海量的数据湖。所以水平扩容的技术架构以及对业务低侵入或者零侵入的技术会是核心考虑的性能指标。可采用分布式部署形态,通过横向拓展配置多台处理器,对数据识别处理的能力进行灵活升级。
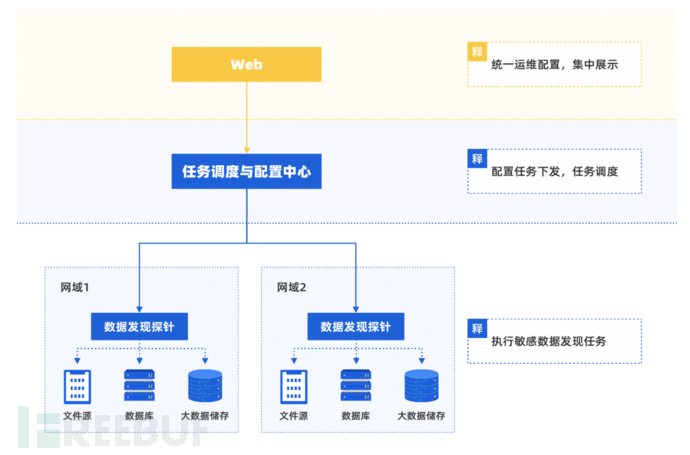
如何满足企业中多种数据资产类型多样性要求
不同业务特性可能需要不同种类的数据库提供支持,如何通过一个平台统一梳理发现数据资产是企业面对的问题之一。
——使用对数据资产类型支持范围尽可能广的产品,至少支持包括关系型数据库、分析型数据库、半结构化数据库、大数据组件、文件存储服务器等类型,另应支持插件化拓展数据资产类型,保证对企业用户定制或自研数据库的快速支持。
目前通过分类分级落地精细化管控的理念已被成功运用到了数据安全产品中。

- 0 文章数
- 0 关注者