


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文作者:pingch,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
前言
近年来,隐私问题成为人们广泛关注的热点问题,随着大数据时代的到来,每个人的行为轨迹都被厂商以不同形式存储在云端,产生了大量的隐私泄露问题。有研究者提出了差分隐私技术(Differential Privacy),它作为一种隐私模型,严格定义了隐私保护的强度,即任意一条记录的添加或删除,都不会影响最终的查询结果。同时,该模型定义了极为严格的攻击模型,其不关心攻击者具有多少背景知识。
0x00 概述
传统的差分隐私技术将原始数据集集中到一个数据中心,再有数据中心对用户数据进行加工,使其符合差分隐私保护的要求,我们将其称之为中心化差分隐私。在上一篇文章中我们简单介绍了中心化差分隐私保护技术的拉普拉斯机制和指数机制。中心化差分隐私技术有一个很关键的假设,即数据中心/数据收集者是可信的,不会泄露用户的隐私信息。显然这种前提仅存在于理论中,即使数据收集者主观上没有泄露用户隐私的意愿,但由于网络攻击等外在因素,数据同样可能被非法获得。
在很多情况下,用户往往面对的是大量的非可信实体(untrusted entity),很多时候用户甚至不希望厂商获得自己的隐私数据。然而数据挖掘又需要大量的用户行为轨迹进行分析,从而获得更精确的用户画像,提升用户体验(或是更精准的广告投放)。如何让企业在不侵犯用户隐私的前提下,利用数据、挖掘数据的价值,是本文所要讨论的问题。
既然一个真正可信的数据收集者很难找到,研究人员提出了本地化的差分隐私保护技术,直接在客户端进行数据的隐私化处理,杜绝了数据中心/数据收集者泄露用户隐私的可能。
0x01 随机响应技术
在介绍本地化差分隐私技术之前,需要介绍的是随机响应技术(randomized response)。
首先,我们介绍一个使用随机响应技术的典型场景:
假设有n个用户,其中艾滋病患者的比例为π,我们希望对π进行统计。于是对目标用户发起问卷调查:“你是否为艾滋病患者?”显然,如果直接获得用户的相应数据进行统计,一旦数据泄露,那么用户隐私随即泄露。因此,我们假设存在一枚非均匀的硬币,其正面向上的概率为p,反面向上的概率为1-p。抛出该硬币,若正面向上,则回答真实答案,反面向上,则回答相反的答案。
显然,理论上,Pr[Xi=“是”]=πp+(1-π)(1-p),Pr[Xi=“否”]=(1-π)p+π(1-p)。直觉上,当n足够大时,设回答“是”的人数为n1,回答“否”的人数为n2。Pr[Xi=“是”]=n1/n,Pr[Xi=“否”]=n2/n。求解下面的二次方程即可获得π的值。
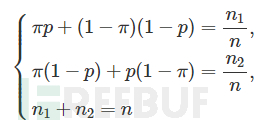
但是,上述的结果并非真实比例的无偏估计,我们用极大似然估计(Max Likehood Estimation)对统计结果进行校正。
首先构建似然函数:
![]()
对数似然函数为:
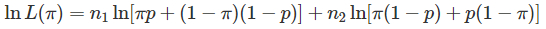
令
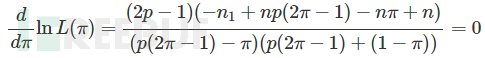
求解可得π的极大似然估计:
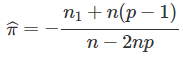
通过进一步求解π的数学期望可验证上述估计为π的无偏估计。
由此可得患有HIV的总人数:
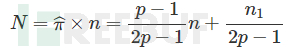
0x02 本地化差分隐私定义
定义给定n个用户,每个用户对应一个隐私算法M及其定义域Dom(M)和值域Ran(M),若算法M在任意两条记录t和t’(t, t’ ∈ Dom(M))上得到相同的输出结果t ( t ⊆ Ran(M))满足下列不等式,则M满足ε-本地化差分隐私。
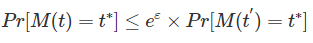
从上述定义可知,在实现本地化差分隐私保护的系统中,任意两个用户都可能输出相同的结果,与中心化差分隐私技术相似,本地化差分隐私技术也是通过对数据加入扰动来实现任意两条记录之间的相似性。0x01随机响应技术就是主流的数据扰动机制,由于扰动添加的流程被分配到客户端,因此数据安全性的保证不再依赖于一个可信实体,降低了数据泄露的风险。通俗的说,本地化差分隐私就是让各个数据提供者根据一定的概率对自身数据加入噪声,而在数据聚合时,由于噪声符合一定的概率分布,因此不同记录间的噪声相互抵消,从而获得基于大样本的统计学特征。
事实上,在0x01随机响应技术的案例中即是实现了ε=ln(p/(1-p))的ε-本地化差分隐私,具体的证明步骤在此略去,可以参考相关文献[2]。由于随机响应技术仅适用于两种取值的离散型变量,因此对于具有超过两种取值的变量,主流的方案是对其进行二进制编码,使其分解为多个0-1变量,从而满足随机响应技术对二值变量的要求。另外,一些研究人员通过对随机响应技术中的概率分布进行改进,实现支持多种取值的差分隐私保护,例如文献[3]中所提到的k-RR方法。
0x03 方案设计
在WWDC2016会议上,苹果公司宣布了他们将差分隐私技术应用在iOS10,尽管没有开源相关技术,但是文献[4]介绍了该技术实现的细节。如下图所示,在苹果对用户Emoji表情使用频数统计中,当一个Emoji表情使用事件发生时,首先对该事件使用ε-本地化差分隐私进行隐私化处理,然后将其暂存在设备上,在经过一定时间后,系统根据规则对暂存的数据随机抽样,并发送至服务器。
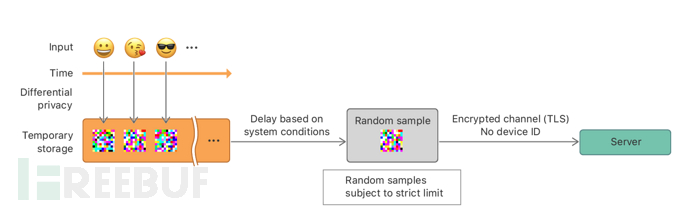
在iOS上,可以在[设置]-[隐私]-[分析]-[分析数据]中找到包含“DifferentialPrivacy”的实体【事实上,我并没有在我的iOS设备中找到相关条目】,下图展示了使用差分隐私保护技术收集受欢迎的Emoji表情的实例,parameters字段表示该差分隐私算法中所使用参数的取值,records字段表示一段由十六进制编码的隐私数据。

所有的隐私数据在处理前都会去除其IP地址,采集器(Ingestion)会一视同仁地将来自所有设备和用户的数据放在相同的环境中进行处理。在处理时,首先会删除时间戳等元数据(metadata),然后根据各自的统计场景(例如Emoji表情受欢迎程度、系统偏好设置等)进行分类,最后随机打乱各使用场景内部数据的顺序,并传输至聚合器(Aggregation)。
聚合器从采集器获得相关数据后,分别对不同统计场景,利用后续介绍的算法生成该统计场景下的直方图,这些统计结果会在苹果内部的相关团队中共享。
0x04 算法
相比于Google的RAPPOR[2],苹果所提出的Private Count Mean Sketch(CMS)算法显然更易于理解。在这里,我们将以CMS算法为例,介绍如何在客户端和服务端实现ε-本地化差分隐私保护。
客户端
以统计用户最常使用的Emoji表情为例。例如,根据客户端的统计,某用户最常浏览的Emoji表情为“【大笑】”。CMS算法首先设计一组哈希函数H={h1, h2, ···, hn},并规定H中的函数能够根据输入的域名输出一个大小为m的较小的值。假设,在该场景中CMS算法选取哈希函数h1,并且h1(“【大笑】”)=31。此时,我们首先初始化一个长度为m的one-hot向量B,并将第31位赋值为1,其他位置赋值为0,然后对该向量的每一位以概率p进行翻转(即当Bi=1时,将Bi赋值为0;当Bi=0时,将Bi赋值为1),最后将翻转后的向量B’和所选取的哈希函数h1发送至服务端。其中,p=1/(exp(ε/2)+1),ε为该算法的隐私保护预算。
对于服务端而言,由于获得的向量经过混淆,无法根据客户端发送的向量来识别该用户最常使用的Emoji表情。
服务端
在服务端,首先构建一个大小为n×m的矩阵M,即n列,m行。其中,n表示哈希函数的数目,m表示向量B’的长度。当向量B’和哈希函数h1被传输至服务端,则在M的第1行加上向量B’。当服务端获得足够多的样本,矩阵M的规模足够大,每一行就会提供每个元素的无偏估计。为了计算使用【大笑】表情的频数,CMS算法会通过读取每一行M[j,hj(“【大笑】”)]的值,并计算这些估计的均值,从而获得无偏估计。
实例:Emoji表情使用统计
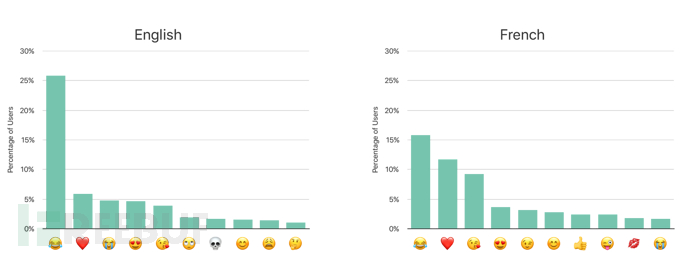
苹果采用了该技术用于获得不同语言使用者的Emoji使用情况。在该统计场景中,共有2600个Emoji表情,此时CMS算法的参数取值如下:m=1024,n=65536,ε=4。图3的直方图展示了英语使用者和法语使用者的Emoji表情使用情况。
RAPPOR:另一种可能
因为篇幅有限,这里仅简单介绍Google所提出的RAPPOR算法的流程,不再介绍具体的扰动机制。
如下图所示,RAPPOR首先使用Bloom Filter将字符串编码为长度为h的01向量B,同时记录下字符串与Bloom Filter的映射关系矩阵,然后利用随机响应技术对向量B的每一位加入扰动,得到永久性随机响应(Permanent Randomized Response,PRR)结果B’,然后在对B’的每一位进行第2次扰动,得到瞬时性随机响应(Instantaneous Randomized Response,IRR)结果S。每个用户得到扰动结果S后,将其发送至服务端,服务端统计每一位上1出现的次数并进行校正,然后结合映射矩阵,通过Lasso回归方法完成用户年龄频数的统计。
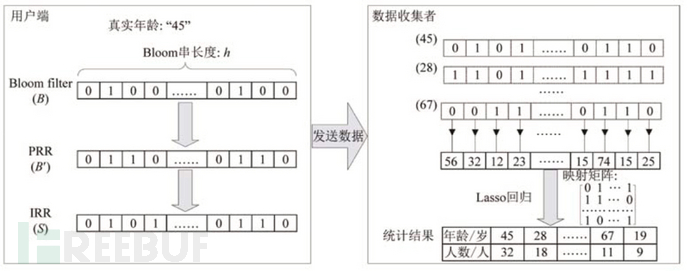
熟悉Bloom Filter的人都知道,这个方法存在的一个很明显的问题就是向量编码值的冲突,即可能两个不同的值可能会输出相同的01向量编码结果,对于这一点,RAPPOR通过调节映射矩阵的参数来避免。
0x05 总结
本文介绍了本地化差分隐私保护技术的系统架构和算法,是前一篇文章差分隐私保护的细化和外延,相比于中心化差分隐私保护技术,本地化差分隐私保护技术打破了中心化差分隐私保护关于可信数据收集者的假设,直接在客户端完成数据的隐私化处理,在工业实践中具有更高的应用价值。
参考文献
[1] 叶青青等. "本地化差分隐私研究综述." 软件学报 7(2018).
[2] Erlingsson, Úlfar, Vasyl Pihur, and Aleksandra Korolova. "Rappor: Randomized aggregatable privacy-preserving ordinal response." Proceedings of the 2014 ACM SIGSAC conference on computer and communications security. ACM, 2014.
[3] Kairouz, Peter, Sewoong Oh, and Pramod Viswanath. "Extremal mechanisms for local differential privacy." Advances in neural information processing systems. 2014.
[4] Differential Privacy Team.“Learning with Privacy at Scale” Apple Machine Learning Journal
*本文作者:pingch,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者