


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
1 Nessus 与 OpenVAS
Nessus 是目前全世界最多人使用的系统漏洞扫描与分析软件。1998年,Nessus 的创办人 Renaud Deraison 展开了一项名为Nessus的计划,其计划目的是希望能为因特网社群提供一个免费、威力强大、更新频繁并简易使用的远端系统安全扫描程序。经过了数年的发展, 包括 CERT 与 SANS 等著名的网络安全相关机构皆认同此工具软件的功能与可用性。2002年,Renaud 与 Ron Gula, Jack Huffard 创办了一个名为Tenable Network Security的机构。在Nessus 3 发布之时,该机构收回了 Nessus 的版权与程序源代码 (原本为开放源代码),Nessus 自此变成了专有软件。
Nessus 2 引擎和一些插件仍然使用 GNU Public License,这促使了基于 Nessus 的fork开源漏洞扫描器 OpenVAS 的诞生,OpenVAS(开放漏洞评估扫描器,最初称为 GNessUs)是 Greenbone 漏洞管理 (GVM) 的扫描器组件,GVM 是一个由多种服务和工具组成的软件框架,提供漏洞扫描和漏洞管理。
可以阅读以下官方文档了解Greenbone Community Edition的架构:
https://greenbone.github.io/docs/latest/architecture.html
2 NASL
NASL – Nessus Attack Scripting Language,网络安全扫描工具 Nessus 和 OpenVAS 插件使用的脚本语言,专用于进行远程主机的漏洞检测扫描,有各种内置函数等。语法类似C,但更简单
NASL脚本语言语法及编写说明可以参看以下链接:
nasl2语法和内置函数文档:https://web.archive.org/web/20220331090759/http://michel.arboi.free.fr/nasl2ref/nasl2_reference.pdf
nasl编写手册文档:The Nessus Attack Scripting Language Reference Guide - DocsLib
中文翻译版:Nessus NASL脚本参考手册 — Nessus NASL脚本参考手册 1.0.1 documentation (homemoon.top)
本文作为OpenVAS源码分析的第一遍文章,介绍NASL语言解释器的实现,并尝试对NASL的语法进行简单的扩充
3 背景知识
3.1 CFG & CFL
上下文无关语言(Context-Free Language, CFL)是形式语言理论中的一个概念,它描述了一类特定的 语言,这些语言可以通过上下文无关文法(Context-Free Grammar, CFG)来生成。上下文无关语言在 计算机科学、尤其是在编译器设计和语言处理中占有非常重要的地位。
上下文无关文法(CFG)
是一个四元组 G = (V,Σ,R,S),其中:
V 是一个非终结符的有限集合。非终结符是用于进一步推导的符号;
Σ 是一个终结符的有限集合,与 V 互斥。终结符是语言的基本符号,不能被进一步推导;
R 是产生式规则的有限集合,规则的形式为 A → γ,其中 A ∈ V 且 γ 是 V 和 Σ 中符号的序列;
S ∈ V 是一个特定的非终结符,称为起始符号。
特点
上下文无关:这意味着产生式规则的应用不依赖于非终结符周围的符号(即上下文)。每个规则 A → γ 表示非终结符 A 可以被替换为 γ,无论 A 出现在哪里或者它周围是什么符号。
表达能力:上下文无关语言能够描述许多编程语言的语法,包括嵌套结构和递归,这是正则表达式所不能做到的。例如,它能够描述括号的配对,函数调用的嵌套等。
正则表达式是CFL,但不是所有CFL是正则表达式,正则表达式不能用于表达无限长度回文,正则表达式 基于有穷状态机 FSM,到达下一个状态不用感知上一个状态了。
3.2 BNF
巴科斯-诺尔范式(BNF,Backus-Naur Form)是一种用于表示上下文无关文法CFG的符号方法。它于 20世纪50年代由约翰·巴科斯(John Backus)提出,并由彼得·诺尔(Peter Naur)进一步发展。BNF广 泛用于计算机科学领域,尤其是在描述编程语言的语法规则时(即编程语言代码怎么写是有效的)。
BNF 使用一系列的替换规则来表达语法结构,这些规则说明了语言中的句子如何构建。它使用尖括号<>来标记非终结符,使用::=来表示定义,终结符直接写作它们自己,产生式规则的不同选择用|分隔。
具体基本组件构成如下:
非终结符(Non-terminal symbols):用尖括号
<>包围,代表语法结构的名称。非终结符是通过其他非终结符或终结符的组合来进一步定义的。终结符(Terminal symbols):表示语言中的基本符号,如字面量、标识符或操作符,直接写 出,不用尖括号包围。
定义符(Definition symbol):用
::=表示,读作 定义为 或 是由...组成的 ,用来分隔定义的左侧 (非终结符)和右侧(由终结符和非终结符组成的表达式)。选择符(Alternation symbol):用
|表示,读作 或 ,表示选择。它用于分隔在相同的上下文中 可以交换使用的不同构造。
假设我们要定义一个打印简单的整数算术表达式语法(将这个语言标记成 MiniLang方便后续使用), 可以用BNF来描述如下(自顶向下):
<statement> ::= "print" <expression>";"
<expression> ::= <term> | <expression> "+" <term> | <expression> "-" <term>
<term> ::= <factor> | <term> "*" <factor> | <term> "/" <factor>
<factor> ::= <number> | "(" <expression> ")"
<number> ::= <digit> | <number><digit>
<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
对算数运算表达式进行打印。定义了加法(+)、减法(-)、乘法(*)、除法(/)四种基本的算 术运算。这些运算可以在表达式中自由组合使用。通过<factor>的定义,这个语法支持使用圆括号
()来改变运算的优先级。括号内的表达式会首先被计算。语法规则的定义允许表达式递归地包含其他表 达式,这意味着可以构建复杂的嵌套表达式。例如,3 + 2 * (1 + 4)中的(1 + 4)就是一个嵌套的表达式
3.3 词法分析 & 语法分析 & 语义分析
下图来自编译器“龙书”《Compilers: Principles, Techniques, and Tools》,介绍了编译器的结构,其 中包含了3个重要阶段词法分析、语法分析和语义分析
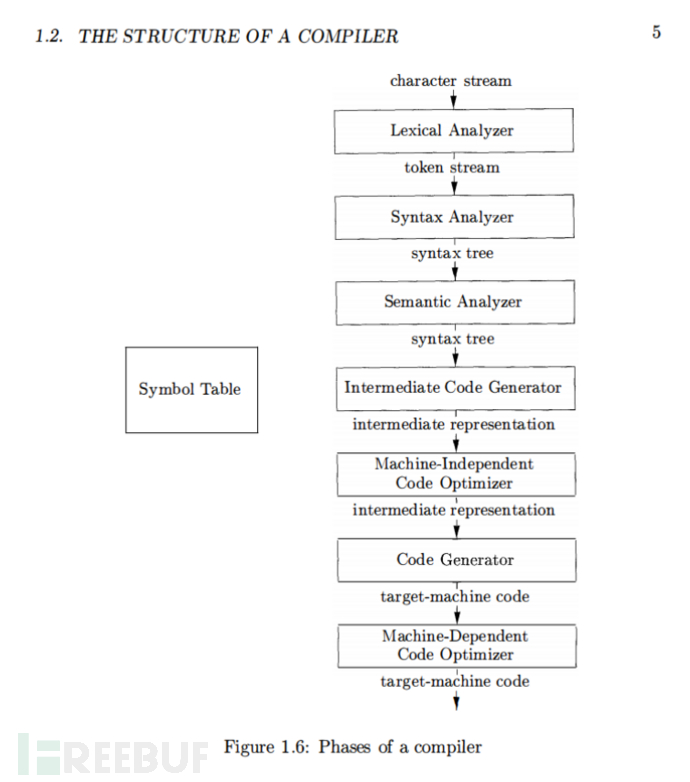
让我们结合上述 MiniLang语言语法,通过一个简单的编程语言例子来说明词法分析、语法分析和语义分析过程。假设我们有这样一行简单的代码:
print 10 + (5 - 3);
在词法分析阶段,编译器的任务是将源代码文本分解成一系列的词法单元(tokens),每个token都是代 码中最基本的语法单位。对于上面的代码,词法分析器可能会产生以下tokens序列:
print→ 关键字(PRINT)10→ 整数(NUMBER:10)+→ 加号(PLUS)(→ 左括号(LPAREN)5→ 整数(NUMBER:5)-→ 减号(MINUS)3→ 整数(NUMBER:3))→ 右括号(RPAREN);→ 分号(SEMICOLON)
接下来,语法分析阶段将使用这些tokens来构建一个抽象语法树(AST)。语法分析器会检查tokens的 序列是否遵循了语言的语法规则。比如 print 后面是否跟着一个合法的表达式。对于我们的例子,一个 可能的AST如下所示:
print
|
+
/ \
10 -
/ \
5 3
在语义分析阶段,编译器会对AST进行遍历,执行类型检查、变量绑定、作用域规则检查等操作,确保程序的语义符合语言规范。
语义分析成功之后,编译器会继续进行后续的编译阶段,例如中间代码生成、优化和目标代码生成等。
NASL 实现主要涉及词法分析阶段和语法分析阶段用于构造AST树,以及语义分析阶段用于遍历AST树,判断当前树节点类型执行对应类型的处理代码,不断改变AST树并执行。
4 自行实现一门语言与 Lex & Yacc
4.1 自行实现
介绍完以上背景知识后,我们开始实现上述 MiniLang语言,这里借助Python语言进行实现:
词法分析器实现
import re
import sys
class Lexer:
def __init__(self, text):
self.tokens = re.findall(r'\d+|\+|-|\*|/|\(|\)|print|;', text)
self.token_index = 0
def get_next_token(self):
if self.token_index < len(self.tokens):
token = self.tokens[self.token_index]
self.token_index += 1
return token
return None # 表示没有更多的标记
语法分析器和解释器实现
class Interpreter:
def __init__(self, lexer):
self.lexer = lexer
self.current_token = self.lexer.get_next_token()
def eat(self, token_type):
if self.current_token == token_type:
self.current_token = self.lexer.get_next_token()
else:
raise Exception('Invalid syntax')
def factor(self):
"""解析因子"""
token = self.current_toke
if token.isdigit():
self.eat(token)
return int(token)
elif token == '(':
self.eat('(')
result = self.expr()
self.eat(')')
return result
def term(self):
"""解析项"""
result = self.factor()
while self.current_token in ('*', '/'):
token = self.current_token
if token == '*':
self.eat('*')
result *= self.factor()
elif token == '/':
self.eat('/')
result /= self.factor()
return result
def expr(self):
"""解析表达式"""
result = self.term()
while self.current_token in ('+', '-'):
token = self.current_token
if token == '+':
self.eat('+')
result += self.term()
elif token == '-':
self.eat('-')
result -= self.term()
return result
def statement(self):
"""解析命令"""
if self.current_token == 'print':
self.eat('print')
value = self.expr()
self.eat(';')
print(value) # 确保每条语句以分号结束
def parse(self):
while self.current_token is not None:
self.statement()
测试运行
from mini_lang_lexer import Lexer
from mini_lang_parser import Interpreter
text = "print 1 + 2 * (3 + 4) - 5;"
lexer = Lexer(text)
interpreter = Interpreter(lexer)
interpreter.parse()
4.2 Lex & Yacc
由上不难看出,随着编程语言的词法和语法规则越来越复杂,手写一个能够正确识别所有合法程序并且优雅地处理错误的解析器是非常困难和耗时的。
为了解决上述问题,诞生了Lex(词法分析器生成器) 和 Yacc(Yet Another Compiler Compiler, 语法分析器生成器),使用 Lex 和 Yacc,语言设计者可以快速实现新语言的原型。Lex 被设计用来自动生成词法分析器(或称为 lexer 或 scanner),通过定义一套简单的正则表达式规 则,Lex 能够生成一个高效的词法分析器代码,极大简化了这一过程。Yacc 用于自动生成语法分析器, 它接受一组定义语言语法的规则(通常以 BNF 形式给出),并产生一个能够解析这些规则的代码。这使 得开发者可以更专注于语言的设计,而不是解析技术的实现细节。
Flex 是 Lex 的一个开源替代品,Flex 提供了对 Lex 的向后兼容,这意味着大多数为 Lex 编写的词法规则 文件也可以在 Flex 中使用而不需要或只需少量修改。Bison 是 GNU 项目的一部分,作为 Yacc 的一个自 由开源替代品,Bison 设计上兼容 Yacc,这意味着大多数为 Yacc 编写的文法规则文件都可以不加修改地 在 Bison 中使用。
Flex / Bison 语法类似,分为definition section/rules section/user subroutines section */详细可以参看 lex & yacc 书籍(By John R. Levine, Tony Mason, Doug Brown · 1995)
下面将上述 MiniLang 使用 Flex 和 Bison 实现
mini_lang.l :
%{
#include "y.tab.h" // Bison 生成的头文件
%}
%%
[0-9]+ { yylval = atoi(yytext); return NUMBER; }
"print" { return PRINT; }
"+" { return PLUS; }
"-" { return MINUS; }
"*" { return TIMES; }
"/" { return DIVIDE; }
"(" { return LPAREN; }
")" { return RPAREN; }
";" { return SEMICOLON; }
[ \t\n]+ { /* 忽略空白 */ }
. { /* 忽略其他字符 */ }
%%
/* 不用 gcc -lfl 了*/
int yywrap() {
return 1;
}
mini_lang.y :
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(const char *s);
int yylex(void);
%}
%token NUMBER PRINT
%token PLUS MINUS TIMES DIVIDE
%token LPAREN RPAREN SEMICOLON
%left PLUS MINUS
%left TIMES DIVIDE
%%
program:
| program statement SEMICOLON
;
statement:
PRINT expression { printf("%d\n", $2); }
;
expression:
NUMBER { $$ = $1; }
| expression PLUS expression { $$ = $1 + $3; }
| expression MINUS expression { $$ = $1 - $3; }
| expression TIMES expression { $$ = $1 * $3; }
| expression DIVIDE expression { $$ = $1 / $3; }
| LPAREN expression RPAREN { $$ = $2; }
;
%%
int main(void) {
yyparse();
return 0;
}
void yyerror(const char *s) {
fprintf(stderr, "Error: %s\n", s);
}
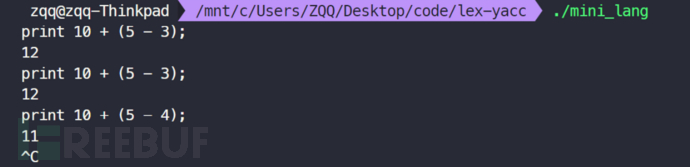
编译
flex mini_lang.l # 生成lex.yy.c
bison -dy mini_lang.y #生成y.tab.h y.tab.c
gcc lex.yy.c y.tab.c -o mini_lang
运行
./mini_lang
5 回到NASL
好了,具备以上背景知识后,让我们分析OpenVAS NASL解释器实现相关代码
代码仓库:https://github.com/greenbone/openvas-scanner/tree/main/nasl tag: v22.7.9
执行入口:nasl/exec.c:1614 int exec_nasl_script (struct script_infos *script_infos, int mode)
关键调用了以下函数:
int init_nasl_ctx (naslctxt *, const char *);int naslparse (naslctxt *, int *);lex_ctxt * init_empty_lex_ctxt ();tree_cell * nasl_exec (lex_ctxt *, tree_cell *);
nasl/nasl_grammar.y此文件 NASL语言的 yacc 语法文件,定义了NASL语法,以及如何生成AST
5.1 init_nasl_ctx
主要作用是初始化了如下语法分析时涉及的结构体
nasl_global_ctx.h: typedef struct
{
int line_nb;
char *name;
int always_signed; /**< If set disable signature check during scans and feed
upload. */
int exec_descr; /**< Tell grammar that is a feed upload process or a running a
scan process. */
int index;
unsigned int include_order;
tree_cell *tree; /* 解析的AST树 */
char *buffer; /* 存nasl脚本内容 */ kb_t kb;
} naslctxt;
5.2 naslparse
naslparse(语法分析入口)会循环调用nasllex(此法分析入口),当 nasllex return 0时,代表到达EOF处理结束;nasllex 调用了 mylex,nasl_grammar.y:906: static int mylex (YYSTYPE *lvalp, void *parm)
mylex 依据记录当前所处的状态进行token判断的,实现框架:
一个 while(1) 循环,通过
c = ctx->buffer[ctx->index++]一直读取字符,判断当前状态,闭合时状态处理等exit_loop
大致是:
如果状态是
ST_START/ST_COMMENT/ST_SPACE,且c == '\0',返回 0,告诉 naslparse EOF如果
c == '#',进入ST_COMMENT状态,一直读取字符,直到c == '\n',刷新状态为ST_START,实现忽略注释的功能如果
c == '"',进入ST_STRING2状态,后续一直读取字符,存在p = parse_buffer中,直到另 一个c == '"'进行闭合,进入exit_loop,返回lvalp->str = g_strdup (parse_buffer);如果
c == ''',进入ST_STRING1状态,代码中的字符串 可以是a = '123\n456'这种,会将实际的 \n 换行符放在字符串中,与c语言中的字符串一致,\n 这种字符串长度 len +1,并返回memcpy (lvalp->data.val, parse_buffer, len + 1); / lvalp- >data.len = len;其他类似
构造AST
构造AST树依赖nasl/nasl_grammar.y匹配到的action进行构建,action调用涉及nasl_tree.h和nasl_tree.c中的结构体和函数
如下NASL代码:
x = 1 + 2 * 3;
生成的ASTnaslctx -> tree大致如下
NODE_INSTR_L
1: NODE_AFF
1: L1: NODE_VAR
Val="x"
2: EXPR_PLUS
1: CONST_INT
Val=1
2: EXPR_MULT
1: CONST_INT
Val=2
2: CONST_INT
Val=3
5.3 init_empty_lex_ctxt
开始执行逻辑的处理,初始化执行环境的context
nasl_lex_ctxt.h
{
struct struct_lex_ctxt *up_ctxt;
tree_cell *ret_val; /* return value or exit flag */
unsigned fct_ctxt : 1; /* This is a function context */
unsigned break_flag : 1; /* Break from loop */
unsigned cont_flag : 1; /* Next iteration in loop */
unsigned always_signed : 1;
struct script_infos *script_infos;
const char *oid;
int recv_timeout;
int line_nb;
/* Named variables hash set + anonymous variables array */
nasl_array ctx_vars;
/* Functions hash table */
GHashTable *functions;
} lex_ctxt;
5.4 nasl_exec
exec.c:1650: tree_cell * nasl_exec (lex_ctxt *lexic, tree_cell *st),对AST节点进行遍历和执行,涉及到nasl_var.c/nasl_func.c等
本质为遍历当前AST树节点,基于节点类型执行对应操作,如下举例说明for循环的处理for(i=1;i<=10;i++) {display(i);},for循环的节点类型为NODE_FOR
case NODE_FOR:
/* [0] = start expr, [1] = cond, [2] = end_expr, [3] = block */
ret2 = nasl_exec (lexic, st->link[0]); /*先执行 link[0],即 i=1 操作
#ifdef STOP_AT_FIRST_ERROR
if (ret2 == NULL)
return NULL;
#endif
deref_cell (ret2);
for (;;) {
/* Break the loop if 'return' */
if (lexic->ret_val != NULL)
{
ref_cell (lexic->ret_val);
return lexic->ret_val;
}
/* condition */
if ((ret = nasl_exec (lexic, st->link[1])) == NULL) /* 进入一个死循环,执行判断 i<=10 */
return NULL; /* We can return here, as NULL is false */
flag = cell2bool (lexic, ret);
deref_cell (ret);
if (!flag)
break;
/* block */
ret = nasl_exec (lexic, st->link[3]); /* 如果 i <=10,则执行 display(i) */
#ifdef STOP_AT_FIRST_ERROR
if (ret == NULL)
#endif
return NULL;
deref_cell (ret);
/* break */
if (lexic->break_flag)
{
lexic->break_flag = 0;
return FAKE_CELL;
}
lexic->cont_flag = 0; /* No need to test if set */
/* end expression */
ret = nasl_exec (lexic, st->link[2]); /* 最后执行 i++ */
#ifdef STOP_AT_FIRST_ERROR
if (ret == NULL)
#endif
return NULL;
deref_cell (ret);
}
return FAKE_CELL;
5.5 扩充NASL语法
实现新增阶乘符号a = 3! = 3x2x1 = 6,对应代码的修改如下
nasl/nasl_grammar.y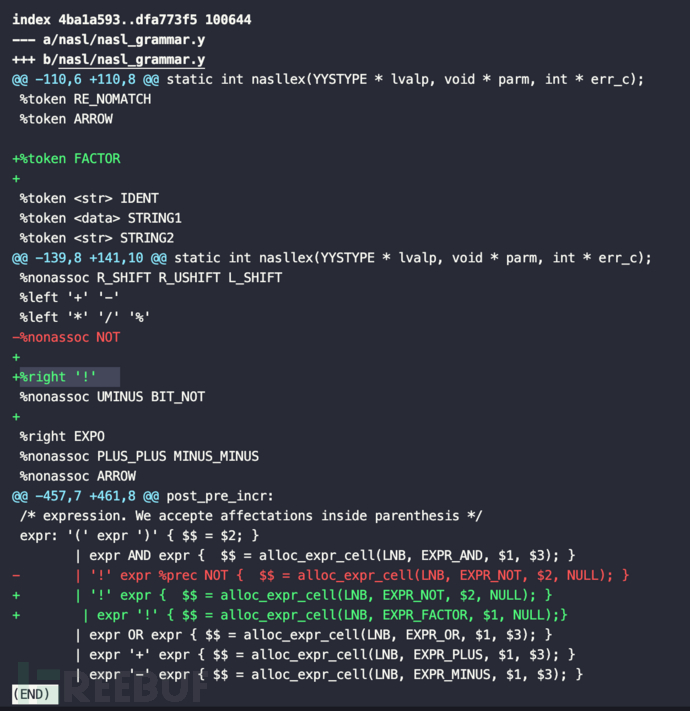
%right '!',!操作符(NASL原本为逻辑非操作)具有右结合性。这意味着在表达式中连续使用多个!操作符时,它们会从右到左进行分组,如!3!=!6
nasl/nasl_tree.h和nasl/nasl_tree.c,主要为添加EXPR_FACTOR节点类型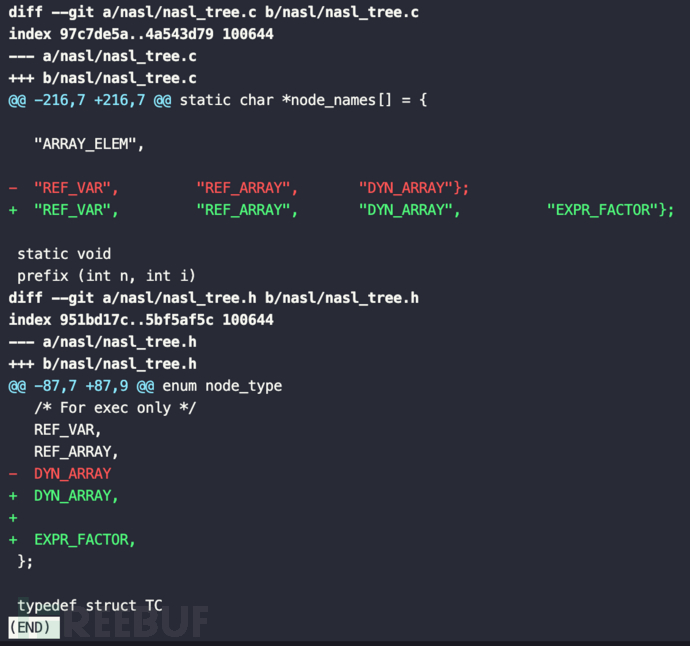
nasl/exec.c对应阶乘的实现逻辑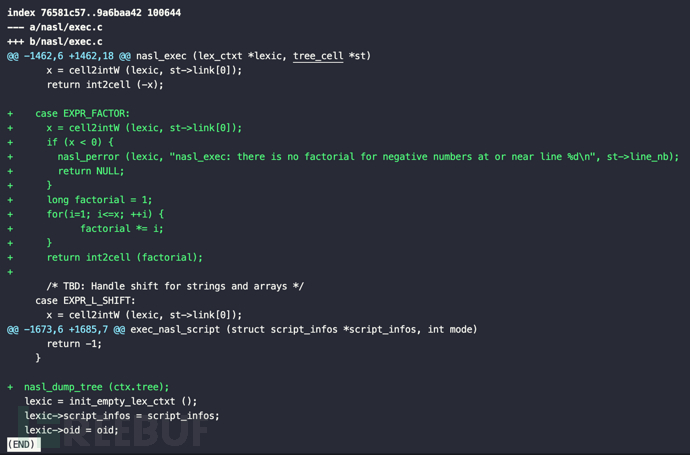
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者