


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
1、什么是Hive
Hive是一个基于Hadoop的数据仓库工具,用于处理和分析大规模结构化数据。Hive提供了类似SQL的查询语言(HiveQL),使得熟悉SQL的用户能够查询数据。Hive将SQL查询转换为MapReduce任务,以在Hadoop集群上执行数据处理和分析。
2、Hive起源
回答这个问题之前,先介绍下Hadoop。Hadoop是专门为离线和大数据分析而设计的分布式基础架构。Hadoop的计算模型是MapReduce,将计算任务分割成多个处理单元,并将其分散到一群家用或服务级别的硬件机器上,从而降低成本。但是直接用MapReduce处理大数据会面临难题:
•MapReduce开发需要具备较高的底层细节知识,开发难度大,学习成本高
•使用MapReduce框架开发,项目周期长,成本高
在此背景下Hive应运而生。Hive是基于Hadoop的一个数据仓库工具,本质是将SQL转换成MapReduce任务进行运算。将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,极大降低用户使用难度。
3、Hive架构
3.1 基本组成部分
Hive的架构是一个复杂的系统,通过用户接口、元数据存储、驱动器和Hadoop集群等多个组件的协同工作,实现了对大规模数据的高效存储和查询处理。其架构图如下图所示。
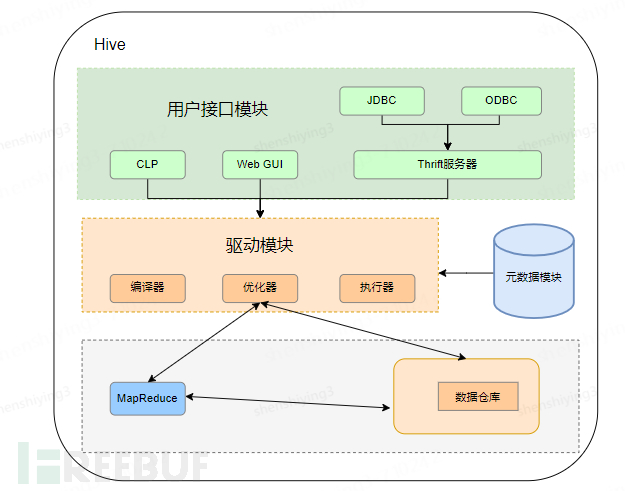
•用户接口模块
这是用户与Hive进行交互的主要方式。Hive提供了多种用户接口,包括CLI(命令行接口)、Client(客户端)、WUI(Web用户界面)以及JDBC/ODBC(允许Java或其他编程语言通过JDBC或ODBC访问Hive)。通过这些接口,用户可以执行HQL(Hive查询语言)语句,进行数据的查询、分析和管理。
BDP平台将页面的SQL转换成SHELL脚本,调用CLI来启动Hive引擎。


•元数据模块
Hive是将数据文件映射成一张表,元数据模块主要负责描述和管理数据存储、表结构、分区信息等,通常存储在关系型数据库中,如MySQL或Derby。

•驱动器(Driver)
驱动器是Hive的核心组件,主要作用是将HiveQL语句转换成一系列的MapReduce(MR)作业。驱动器中包含了解析器、编译器、优化器和执行器等多个子组件。解析器将用户的HQL查询语句转换为抽象语法树(AST),编译器将AST编译成逻辑执行计划,优化器对逻辑计划进行优化,最后执行器将优化后的计划转换成可以运行的物理计划并执行。

•Hadoop集群
Hive是建立在Hadoop上的数据仓库基础构架,因此Hadoop集群是Hive架构的重要组成部分。Hive使用Hadoop的分布式文件系统(HDFS)进行数据存储,利用Hadoop的MapReduce框架进行大规模数据的计算和处理。
3.2 Hadoop
Hadoop是开源的分布式存储和计算系统,旨在处理大规模数据集。它最初由Apache软件基金会开发,现已成为处理大数据的行业标准之一。Hadoop主要包括以下核心组件:HDFS、MapReduce。
3.2.1 分布式文件系统(HDFS)
HDFS是Hadoop的分布式文件系统,用于存储大规模数据集。它将数据分布存储在集群中的多台服务器上,通过数据冗余存储来提供容错性和高可靠性。
◦高可靠性
HDFS它将文件数据划分为多个数据块,并在集群中的多个节点上进行复制存储。每个数据块默认会有多个(通常是三个)副本存储在不同的节点上。这种冗余存储机制确保了即使某个节点或副本发生故障,数据仍然可以从其他副本中恢复,从而保证了数据的高可靠性。
◦HDFS架构
HDFS采用了主从架构,包括一个NameNode和多个DataNode。NameNode负责管理文件系统的命名空间和元数据信息,而DataNode负责存储实际的数据块。
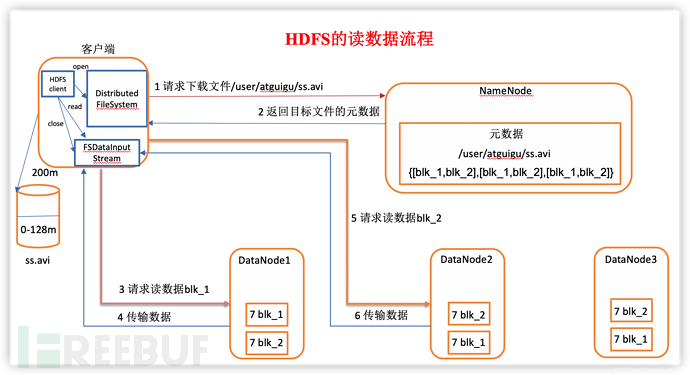
◦读取文件的过程:
1.客户端向NameNode请求获取文件,并对请求进行检查。
2.如果请求检查通过,NameNode将查询元数据,向客户端返回文件所在的各个Block的DN地址。
3.客户端拿到DN列表之后,按照Block,根据负载规则请求一台服务器,建立通道读取数据。
4.DN接收到请求后,向客户端传输Block内容。
5.获取到的内容,存入本地缓存,然后写入到输出目标中。
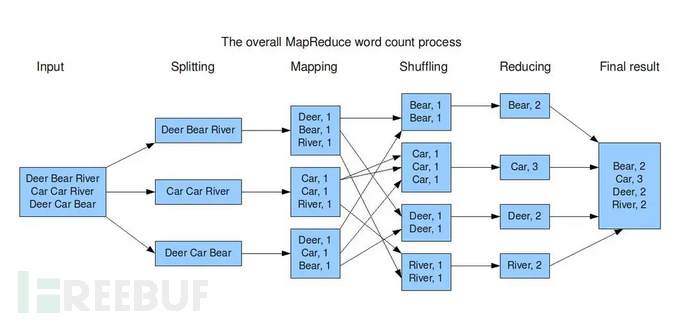
3.2.2 分布式计算框架(MapReduce)
MapReduce是Hadoop的分布式计算框架,用于在大规模数据集上执行并行计算任务。它将计算任务分解为多个独立的子任务,然后在集群中的多台计算节点上并行执行这些子任务。MapReduce包括Map阶段和Reduce阶段 ,2个阶段。
◦Map阶段将原始数据分解为更小的数据单元,这些单元可以被并行处理,且彼此之间没有太多依赖。
◦Reduce阶段则对Map阶段生成的中间结果进行汇总,以得到最终的处理结果。
4、Hive工作流程
Hive是一个建立在Hadoop之上的数据仓库系统,它提供了类似于SQL的查询语言(HiveQL),使用户可以在大规模数据集上执行查询和分析操作。下面是Hive的工作流程:
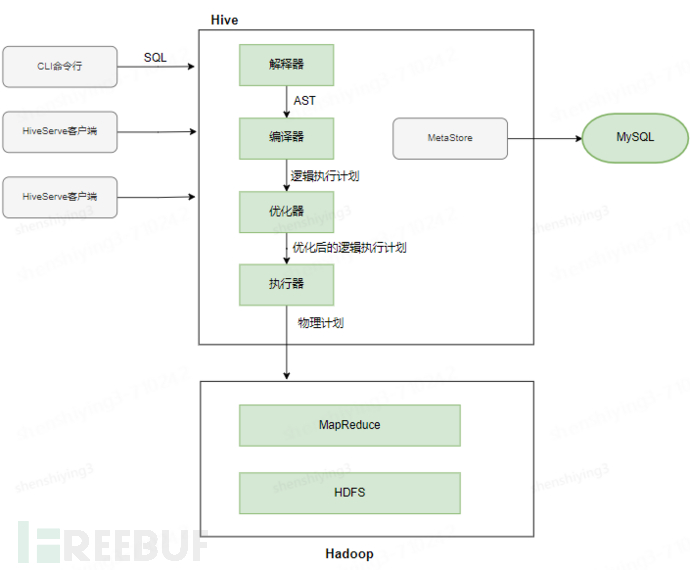
1.解析HiveSQL:
◦当用户提交一个HiveSQL查询时,Hive的解析器首先会解析这个查询,将其转换成一个抽象语法树(AST)。
◦解析器会检查SQL语法的正确性,并将SQL语句的各个部分(如SELECT、FROM、WHERE等)转换为相应的内部表示。
2.语义分析:
◦语义分析阶段会检查查询的语义正确性,确保所有引用的表、列和函数都存在且有效。
◦在这个阶段,Hive还会获取表的元数据,如列的数据类型、表的分区信息等,为后续的计划生成做准备。
3.生成逻辑执行计划:
◦接下来,Hive会根据解析和语义分析的结果,生成一个逻辑执行计划。这个计划描述了查询的执行步骤,但不涉及具体的物理操作。
◦逻辑计划通常包括一系列的操作,如扫描表、过滤数据、聚合数据等。
4.逻辑计划优化:
◦在生成逻辑计划后,Hive会对其进行优化,以提高查询的执行效率。
◦优化可能包括重写查询、消除冗余操作、选择更有效的连接策略等。
5.生成物理执行计划:
◦优化后的逻辑计划会被转换为物理执行计划。物理计划描述了如何在Hadoop集群上实际执行查询。
◦在这个阶段,Hive会决定将哪些操作映射到MapReduce任务上,以及如何在集群中分配这些任务。
6.执行MapReduce任务:
◦根据物理执行计划,Hive会启动MapReduce任务来执行查询。任务读取的数据来自HDFS。
◦Map阶段通常负责读取数据并进行一些基本的处理,如过滤和转换。
◦Reduce阶段则负责聚合数据并生成最终结果。
7.返回结果:
◦当所有MapReduce任务完成后,Hive会收集并整理结果,然后将其返回给用户。
- 0 文章数
- 0 关注者