


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
“网藤杯”智能安全机器人养成计划活动从2018年1月4日开启,为期2个月,目前已告一段落。收获暗链、webshell通信样本、恶意URL样本共计12357份。在活动期间,通过各模型的定期重训练和训练样本数量及质量提高,使智能安全机器人的识别能力有了大幅提升。本着资源共享思想,下面将一些活动运行机制和检测模型原理等技术细节做部分解密,希望能给安全爱好者和从业者带来一些启迪。
伴随着十三届全国人大再次重点强调人工智能产业发展,将人工智能引入到安全行业中已是大势所趋。与其他领域不同地方是,安全行业面临的难点是数据稀缺问题,通过组织一系列样本收集活动,是一个很好的解决方案,即可提高训练样本集的多样性和质量,又可以向大众普及人工智能在安全行业中的切入点。
“网藤杯”智能安全机器人养成计划活动结合网藤智能安全系统自研的机器学习模型为基础,设计了网页暗链、webshell通信、恶意URL三类样本收集。这类样本收集技术实现是较复杂的,需要考虑到作弊、刷分、提交非法样本、提交重复样本等情况。我们在实际实施中通过设计样本合法性校验模块、去重模块、基于时间序列的作弊检测模块等预置模块解决此类问题。当样本经过这些模块后,被标记为合法样本(即符合要求的恶意样本,进一步被送入到机器学习检测模型识别样本属性(恶意、安全,并将模型识别样本为恶意的概率转化为智力值得分反馈给用户。通过定期从数据库导出恶意样本和正常样本做1:1混合成训练样本集,重训练模型不断优化提高模型检测效果。
机器人养成计划活动中,将用户提交的合格样本投递到各算法模型中实现“养成”。我们自研的暗链检测模型、webshell通信检测模型、恶意URL检测模型均使用了机器学习算法。下面将对每个模型做简要介绍。
网页暗链检测模型用于检测网页中被注入的暗链页面中不可见,指向外部链接,包含淫秽博彩商广等敏感内容。技术实现上设计了一种域识别加主题识别构建机器学习模型检测互联网暗链的方法,此方法目的在于通过构建机器学习模型改善传统基于规则的方法对高混杂暗链代码识别效果差的问题,通过引入域识别机制解决目前已公开的基于机器学习识别暗链方法特征提取不纯的问题,通过在域识别基础上做主题识别解决目前已公开的基于机器学习识别暗链方法无法很好区分暗链和页面篡改的问题。图1展示了暗链检测模型逻辑框架。
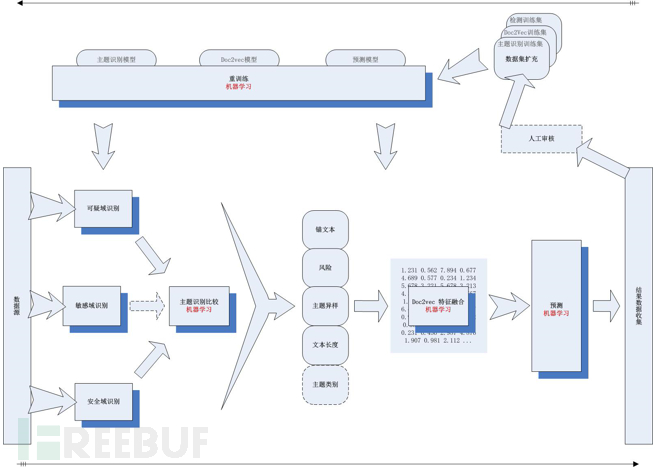
图1
webshell通信检测模型用于检测webshell通信流量行为,通过提取流量数据HTTP请求和响应包中的payload数据进行检测。在特征提取时,采用n-gram模型提取特征,提取的特征会存在维度灾难,使用KL-divergence聚类算法对特征做降维, 训练多层SVM模型(one-class),通过度量组合集(投票数、概率均值、先验概率、概率最大值、概率最小值方式决策结果。
恶意URL检测模型用于检测包含攻击者植入恶意payload的URL,类型可分为SQL注入、跨站脚本、代码注入、文件包含等。恶意URL检测模型使用深度学习中的CNN模型实现。具体来说,使用了256个k长度的卷积核,k取{2,3,4,5},四个全连接层,卷积层中的卷积核宽度为每个字符的向量维数32,每组卷积核分别生成256维向量,在通过ReLU激活函数向卷积网络中引入非线性。之后使用BatchNormalization、pool(sum)、Dropout(0.5)防止模型过拟合。
我们将收集到的样本,通过人工复核再次过滤掉不合法数据,最终获得合法数据。将收集样本与原始样本集混合,使用交叉验证划分训练测试集。ROC曲线对比原始模型效果,和增加样本量后模型效果。以暗链检测模型为例,图2为原始模型ROC曲线,图3为新训练后模型ROC曲线。通过ROC曲线对比可知,样本收集活动对模型检测效果有明显提升。但是,由于作弊、刷分等行为存在,最终收集到的合规样本数量还是较少,对机器学习模型效果优化还是显得捉襟见肘,并且样本合规检测是基于规则的,一些新颖样本很可能无法被准确被标注出,也导致了样本收集多样性的减少。
通过举办一场活动收集样本,如何杜绝非法提交、刷分等作弊情况,并能确保样本收集的多样性,是我们需要不断研究和探索的方向。
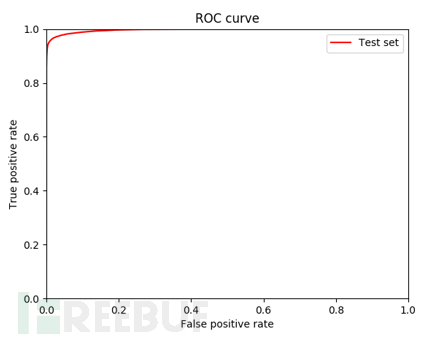
图2
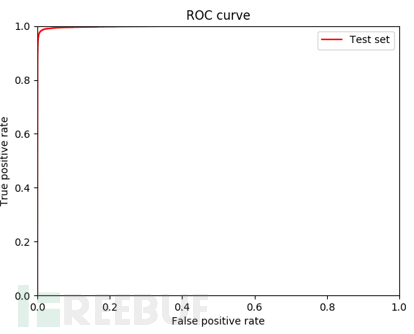
图3
- 0 文章数
- 0 关注者