


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
机器学习时下非常流行,已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。MLlib 是构建在 Spark 上的分布式机器学习库,充分利用了 Spark 的内存计算和适合迭代型计算的优势,将性能大幅度提升。同时由于 Spark 算子丰富的表现力,让大规模机器学习的算法开发不再复杂。
Adaboost算法介绍
h2Adaboost是adaptive boosting(自适应boosting)的缩写,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。它有一个明显的特点就是排除一些不必要的特征值,把模型训练放在关键特征值数据上。正是由于这个特点我们在风控系统中主要采用的就是这个算法来进行数据建模。它的算法过程如下:
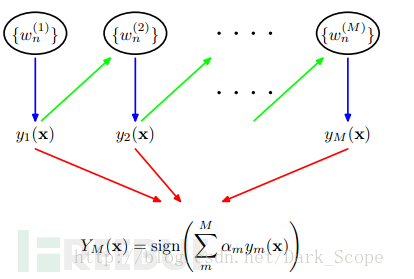
Adaboost从以上概念可以看出它有两种分类器,一种是y1称之为弱分类器,另外一种是Ym称之为强分类器以及一个参数叫alpha,这个值是基于每个弱分类器的错误率进行计算的,其中错误率计算公式如下:![]()
Alpha的计算公式如下:
![]()
计算出alpha之后就需要对权重向量D进行更新,D的计算方法如下:
正确被分类的权重计算:
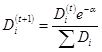
样本被错分之后的权重计算:
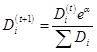
本系统的adaboost是基于单层决策树(decision stump)来构建弱分类器的,单层决策树的算法流程如下:
1、假设数据特征值分为n列m行,错误率初始化为均值,例如100行数据,初始错误向量值为1/100;
2、对每一列数据(即维度数据)选择出最大值和最小值;
3、基于最大和最小值设置每一步的区间,假设100步长,那么步区间为:(max-min)/100
4、遍历每一步区间,做二分类(1和-1),并记录下本次数据和步长的对比关系(大于或者小于)
5、依据第4步算出的特征值(1或者-1)计算错误率;
6、提取最小的错误率、维度、关系运算符以及特征值
我们下面要讲解的spark实现的adaboost算法就是实现上述的算法过程。
算法实现
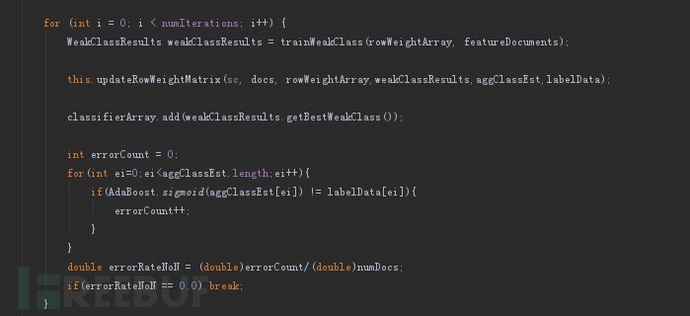
算法实现和spark的自有MLlib的实现步骤基本相同,主要包括:数据加载、特征提取、模型训练。我们截取adaboost算法模型训练之中核心的两个部分:弱分类器训练、权重更新详细讲解一下:
弱分类器训练
1、首先将每一列的特征值数据训练找出最小错误率的阈值(通过stepSize渐进逼近阈值点)
2、记录下错误率及弱分类器以及分类结果值
3、找到最小的一个错误率的维度返回弱分类结果
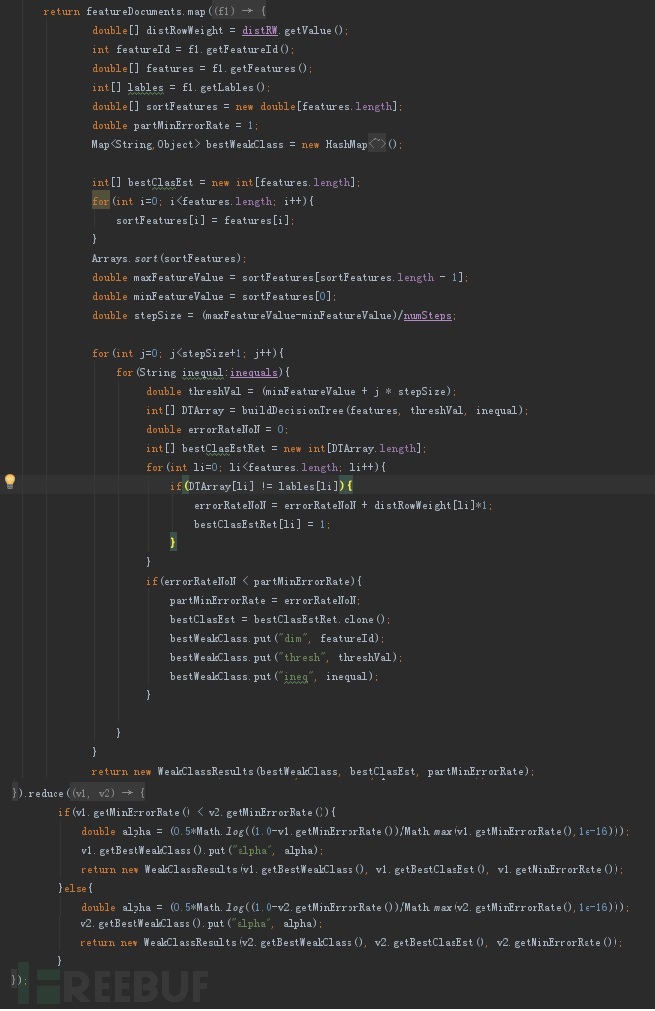
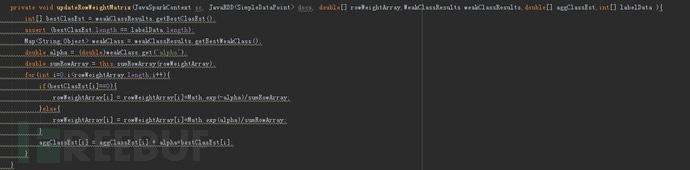
权重更新
1、计算弱分类器是否判断准确,判断准确记为1,否则记为0
2、通过弱分类器结果值判断是否分类正确,正确则通过公式1修改权重,错误则通过公式2修改权重
模型训练入口
账号登录特征提取
账号登录一般涉及到的相关因子字段有账号名称,id,登录注册时间、邮箱及激活等等,我们以几个维度标签来做一个详细说明:
IP维度
网络属性:代理IP、网关IP、VPNip、服务器IP
地域属性:国外IP、IP归属地、高危地区
业务属性:IP登录的业务、IP登录业务的频次
恶意属性:是否风险情报范围内
如何识别代理IP,从代码和扫描工具上来进行判别,以下是一些常用判断方法:
1、反向探测技术:扫描IP是不是开通了80、8080等代理服务器经常开通的端口;
2、HTTP头部的X_Forwarded_For:如果带有XFF信息,该IP是代理IP无疑;
3、Keep-alive报文:如果带有Proxy-Connection的Keep-alive报文,该IP毫无疑问是代理IP;
4、查看IP上端口:如果一个IP有的端口大于10000,那么该IP大多也存在问题,普通的家庭IP开这么大的端口,几乎是不可能的;
手机号维度
异常属性:猫池手机号、诈骗手机号、物联网手机号等
正常标签:保密手机号、实名手机号等
兴趣标签
社交行为、游戏行为、活跃平台、活跃天数、娱乐行为、资讯行为等等
每个账号都以这些因子作为判断维度,进一步量化为数字特征值,整体作为adaboost的输入进行训练,具体训练的结果如下所示。
训练结果
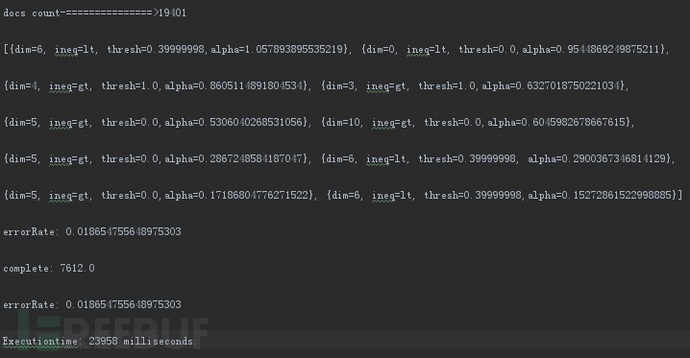
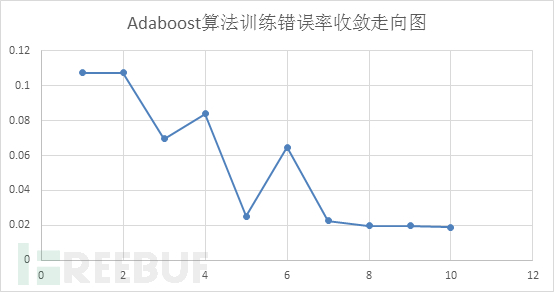
我们以19401条数据进行训练并使用7612条数据测试得到的结果准确率可以达到98.2%,具体输出如下:
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者