


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
0x01 前言
在采集到URL之后,要做的就是对目标进行信息资产收集了,收集的越好,你挖到洞也就越多了............当然这一切的前提,就是要有耐心了!!!由于要写工具较多,SO,我会分两部分写......
0x02 端口扫描脚本编写
 端口扫描的原理:
端口扫描的原理:
端口扫描,顾名思义,就是逐个对一段端口或指定的端口进行扫描。通过扫描结果可以知道一台计算机上都提供了哪些服务,然后就可以通过所提供的这些服务的己知漏洞就可进行攻击。其原理是当一个主机向远端一个服务器的某一个端口提出建立一个连接的请求,如果对方有此项服务,就会应答,如果对方未安装此项服务时,即使你向相应的端口发出请求,对方仍无应答,利用这个原理,如果对所有熟知端口或自己选定的某个范围内的熟知端口分别建立连接,并记录下远端服务器所给予的应答,通过查看一记录就可以知道目标服务器上都安装了哪些服务,这就是端口扫描,通过端口扫描,就可以搜集到很多关于目标主机的各种很有参考价值的信息。例如,对方是否提供FPT服务、WWW服务或其它服务。
代理服务器还有很多常用的端口
比如HTTP协议常用的就是:80/8080/3128/8081/9080,FTP协议常用的就是:21,Telnet协议常用的是23等等
来个较全的...
代理服务器常用以下端口:
⑴. HTTP协议代理服务器常用端口号:80/8080/3128/8081/9080
⑵. SOCKS代理协议服务器常用端口号:1080
⑶. FTP(文件传输)协议代理服务器常用端口号:21
⑷. Telnet(远程登录)协议代理服务器常用端口:23
HTTP服务器,默认的端口号为80/tcp(木马Executor开放此端口);
HTTPS(securely transferring web pages)服务器,默认的端口号为443/tcp 443/udp;
Telnet(不安全的文本传送),默认端口号为23/tcp(木马Tiny Telnet Server所开放的端口);
FTP,默认的端口号为21/tcp(木马Doly Trojan、Fore、Invisible FTP、WebEx、WinCrash和Blade Runner所开放的端口);
TFTP(Trivial File Transfer Protocol),默认的端口号为69/udp;
SSH(安全登录)、SCP(文件传输)、端口重定向,默认的端口号为22/tcp;
SMTP Simple Mail Transfer Protocol (E-mail),默认的端口号为25/tcp(木马Antigen、Email Password Sender、Haebu Coceda、Shtrilitz Stealth、WinPC、WinSpy都开放这个端口);
POP3 Post Office Protocol (E-mail) ,默认的端口号为110/tcp;
WebLogic,默认的端口号为7001;
Webshpere应用程序,默认的端口号为9080;
webshpere管理工具,默认的端口号为9090;
JBOSS,默认的端口号为8080;
TOMCAT,默认的端口号为8080;
WIN2003远程登陆,默认的端口号为3389;
Symantec AV/Filter for MSE,默认端口号为 8081;
Oracle 数据库,默认的端口号为1521;
ORACLE EMCTL,默认的端口号为1158;
Oracle XDB(XML 数据库),默认的端口号为8080;
Oracle XDB FTP服务,默认的端口号为2100;
MS SQL*SERVER数据库server,默认的端口号为1433/tcp 1433/udp;
MS SQL*SERVER数据库monitor,默认的端口号为1434/tcp 1434/udp;
QQ,默认的端口号为1080/udp
等等,更具体的去百度吧,啊哈哈
端口的三种状态
OPEN --端口是开放的,可以访问,有进程
CLOSED --端口不会返回任何东西..可能有waf
FILTERED --可以访问,但是没有程序监听
这里用一个工具--nmap举下栗子吧...
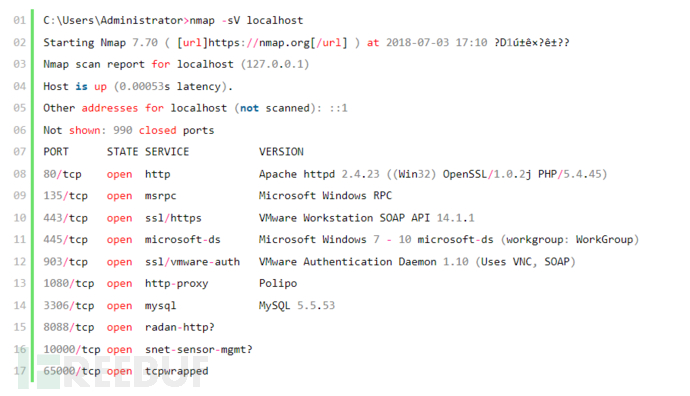
说的差不多了,咱们开始用Python实现它....端口扫描在Python中可以用的模块有很多,本文用socket模块演示单线程的在之前的文章有说过,具体传送门:
#-*- coding: UTF-8 -*-
import socket
def Get_ip(domain):
try:
return socket.gethostbyname(domain)
except socket.error,e:
print '%s: %s'%(domain,e)
return 0
def PortScan(ip):
result_list=list()
port_list=range(1,65535)
for port in port_list:
try:
s=socket.socket()
s.settimeout(0.1)
s.connect((ip,port))
openstr= " PORT:"+str(port) +" OPEN "
print openstr
result_list.append(port)
s.close()
except:
pass
print result_list
def main():
domain = raw_input("PLEASE INPUT YOUR TARGET:")
ip = Get_ip(domain)
print 'IP:'+ip
PortScan(ip)
if __name__=='__main__':
main()
速度是不是巨慢,既然是告别脚本小子,写个单线程的。。肯定是不行的,啊哈哈
放出多线程版本
#-*- coding: UTF-8 -*-
import socket
import threading
lock = threading.Lock()
threads = []
def Get_ip(domain):
try:
return socket.gethostbyname(domain)
except socket.error,e:
print '[-]%s: %s'%(domain,e)
return 0
def PortScan(ip,port):
try:
s=socket.socket()
s.settimeout(0.1)
s.connect((ip,port))
lock.acquire()
openstr= "[-] PORT:"+str(port) +" OPEN "
print openstr
lock.release()
s.close()
except:
pass
def main():
banner = '''
_
_ __ ___ _ __| |_ ___ ___ __ _ _ __
| '_ \ / _ \| '__| __/ __|/ __/ _` | '_ \
| |_) | (_) | | | |_\__ \ (_| (_| | | | |
| .__/ \___/|_| \__|___/\___\__,_|_| |_|
|_|
'''
print banner
domain = raw_input("PLEASE INPUT YOUR TARGET:")
ip = Get_ip(domain)
print '[-] IP:'+ip
for n in range(1,76):
for p in range((n-1)*880,n*880):
t = threading.Thread(target=PortScan,args=(ip,p))
threads.append(t)
t.start()
for t in threads:
t.join()
print ' This scan completed !'
if __name__=='__main__':
main()
很简单的,我都不知道该怎么讲。。。如果你基础知识还不够牢固,请移步至初级篇
0x03 子域名采集脚本编写

采集子域名可以在测试范围内发现更多的域或子域,这将增大漏洞发现的几率。采集的方法也有很多方法,本文就不再过多的叙述了,采集方法的方法可以参考这篇文章
其实lijiejie大佬的subdomainbrute就够用了.....当然了,i春秋也有视频教程的。。。
Python安全工具开发应用
本文就演示三种吧
第一种是通过字典爆破,这个方法主要靠的是字典了....采集的多少取决于字典的大小了...
演示个单线程的吧
#-*- coding: UTF-8 -*-
import requests
import re
import sys
def writtarget(target):
print target
file = open('result.txt','a')
with file as f:
f.write(target+'\n')
file.close()
def targetopen(httptarget , httpstarget):
header = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'DNT': '1',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
}
try:
reponse_http = requests.get(httptarget, timeout=3, headers=header)
code_http = reponse_http.status_code
if (code_http == 200):
httptarget_result = re.findall('//.*', httptarget)
writtarget(httptarget_result[0][2:])
else:
reponse_https = requests.get(httpstarget, timeout=3, headers=header)
code_https = reponse_https.status_code
if (code_https == 200):
httpstarget_result = re.findall('//.*', httpstarget)
writtarget(httpstarget_result[0][2:])
except:
pass
def domainscan(target)
f = open('domain.txt','r')
for line in f:
httptarget_result = 'http://'+ line.strip() + '.'+target
httpstarget_result = 'https://'+ line.strip() + '.'+target
targetopen(httptarget_result, httpstarget_result)
f.close()
if __name__ == "__main__":
print ' ____ _ ____ _ '
print '| _ \ ___ _ __ ___ __ _(_)_ __ | __ ) _ __ _ _| |_ ___ '
print "| | | |/ _ \| '_ ` _ \ / _` | | '_ \| _ \| '__| | | | __/ _ \ "
print "| |_| | (_) | | | | | | (_| | | | | | |_) | | | |_| | || __/"
print '|____/ \___/|_| |_| |_|\__,_|_|_| |_|____/|_| \__,_|\__\___|'
file = open('result.txt','w+')
file.truncate()
file.close()
target = raw_input('PLEASE INPUT YOUR DOMAIN(Eg:ichunqiu.com):')
print 'Starting.........'
domainscan(target)
print 'Done ! Results in result.txt'

第二种是通过搜索引擎采集子域名,不过有些子域名不会收录在搜索引擎中.....
参考这篇文章
我觉得这篇文章介绍的还可以的....我也懒得写了,直接贴过来吧
#-*-coding:utf-8-*-
import requests
import re
key="qq.com"
sites=[]
match='style="text-decoration:none;">(.*?)/'
for i in range(48):
i=i*10
url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=%s"%i
response=requests.get(url).content
subdomains=re.findall(match,response)
sites += list(subdomains)
site=list(set(sites)) #set()实现去重
print site
print "The number of sites is %d"%len(site)
for i in site:
print i
第三种就是通过一些第三方网站..实现方法类似于第二种
在之前的文章中介绍过,我就直接引用过来了
不会的话,就看这篇文章,很详细...
import requests
import re
import sys
def get(domain):
url = 'http://i.links.cn/subdomain/'
payload = ("domain={domain}&b2=1&b3=1&b4=1".format(domain=domain))
r = requests.post(url=url,params=payload)
con = r.text.encode('ISO-8859-1')
a = re.compile('value="(.+?)"><input')
result = a.findall(con)
list = '\n'.join(result)
print list
if __name__ == '__main__':
command= sys.argv[1:]
f = "".join(command)
get(f)
0x04 CMS指纹识别脚本编写

现在有很多开源的指纹识别程序,w3af,whatweb,wpscan,joomscan等,常见的识别的几种方式:
1:网页中发现关键字
2:特定文件的MD5(主要是静态文件、不一定要是MD5)
3:指定URL的关键字
4:指定URL的TAG模式
i春秋也有相应的课程
Python安全工具开发应用
本着买不起课程初心,啊哈哈,我就不讲ADO老师讲的方法了。。。啊哈哈
不过写的都差不多,只是用的模块不同。。。
本文我介绍两种方法,一种是通过API的。。另一种就是纯粹的指纹识别了,识别的多少看字典的大小了。。。
先说第一种。。。
说白了,就是发送个post请求,把关键字取出来就ok了,完全没有难度。。
我用的指纹识别网站是:http://whatweb.bugscaner.com/look/,我怎么感觉有种打广告的感觉。。。抓个包。。然后就一顿老套路 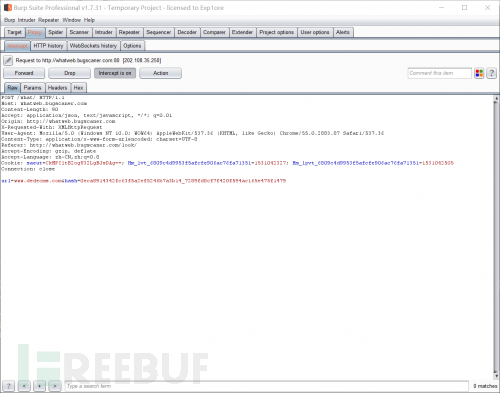
#-*- coding: UTF-8 -*-
import requests
import json
def what_cms(url):
headers = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'DNT': '1',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
}
post={
'hash':'0eca8914342fc63f5a2ef5246b7a3b14_7289fd8cf7f420f594ac165e475f1479',
'url':url,
}
r=requests.post(url='http://whatweb.bugscaner.com/what/', data=post, headers=headers)
dic=json.loads(r.text)
if dic['cms']=='':
print 'Sorry,Unidentified........'
else:
print 'CMS:' + dic['cms']
if __name__ == '__main__':
url=raw_input('PLEASE INPUT YOUR TARGET:')
what_cms(url)
cool!

接下来,就是CMS指纹识别的第二种方法了。。。
我用的匹配关键字的方法。。。
找了个dedecms的匹配字典
范例:链接||||关键字||||CMS别称
/data/admin/allowurl.txt||||dedecms||||DedeCMS(织梦)
/data/index.html||||dedecms||||DedeCMS(织梦)
/data/js/index.html||||dedecms||||DedeCMS(织梦)
/data/mytag/index.html||||dedecms||||DedeCMS(织梦)
/data/sessions/index.html||||dedecms||||DedeCMS(织梦)
/data/textdata/index.html||||dedecms||||DedeCMS(织梦)
/dede/action/css_body.css||||dedecms||||DedeCMS(织梦)
/dede/css_body.css||||dedecms||||DedeCMS(织梦)
/dede/templets/article_coonepage_rule.htm||||dedecms||||DedeCMS(织梦)
/include/alert.htm||||dedecms||||DedeCMS(织梦)
/member/images/base.css||||dedecms||||DedeCMS(织梦)
/member/js/box.js||||dedecms||||DedeCMS(织梦)
/php/modpage/readme.txt||||dedecms||||DedeCMS(织梦)
/plus/sitemap.html||||dedecms||||DedeCMS(织梦)
/setup/license.html||||dedecms||||DedeCMS(织梦)
/special/index.html||||dedecms||||DedeCMS(织梦)
/templets/default/style/dedecms.css||||dedecms||||DedeCMS(织梦)
/company/template/default/search_list.htm||||dedecms||||DedeCMS(织梦)
全的字典去百度吧,小弟不才......小弟用的是deepin,win的报错太鸡肋,实在懒得解决。。。。
#-*- coding: UTF-8 -*-
import os
import threading
import urllib2
identification = False
g_index = 0
lock = threading.Lock()
def list_file(dir):
files = os.listdir(dir)
return files
def request_url(url='', data=None, header={}):
page_content = ''
request = urllib2.Request(url, data, header)
try:
response = urllib2.urlopen(request)
page_content = response.read()
except Exception, e:
pass
return page_content
def whatweb(target):
global identification
global g_index
global cms
while True:
if identification:
break
if g_index > len(cms)-1:
break
lock.acquire()
eachline = cms[g_index]
g_index = g_index + 1
lock.release()
if len(eachline.strip())==0 or eachline.startswith('#'):
pass
else:
url, pattern, cmsname = eachline.split('||||')
html = request_url(target+url)
rate = float(g_index)/float(len(cms))
ratenum = int(100*rate)
if pattern.upper() in html.upper():
identification = True
print " CMS:%s,Matched URL:%s" % (cmsname.strip('\n').strip('\r'), url)
break
return
if __name__ == '__main__':
print '''
__ ___ _ ____ __ __ ____
\ \ / / |__ __ _| |_ / ___| \/ / ___|
\ \ /\ / /| '_ \ / _` | __| | | |\/| \___ \
\ V V / | | | | (_| | |_| |___| | | |___) |
\_/\_/ |_| |_|\__,_|\__|\____|_| |_|____/
'''
threadnum = int(raw_input(' Please input your threadnum:'))
target_url = raw_input(' Please input your target:')
f = open('./cms.txt')
cms = f.readlines()
threads = []
if target_url.endswith('/'):
target_url = target_url[:-1]
if target_url.startswith('http://') or target_url.startswith('https://'):
pass
else:
target_url = 'http://' + target_url
for i in range(threadnum):
t = threading.Thread(target=whatweb, args=(target_url,))
threads.append(t)
print ' The number of threads is %d' % threadnum
print 'Matching.......'
for t in threads:
t.start()
for t in threads:
t.join()
print " All threads exit"
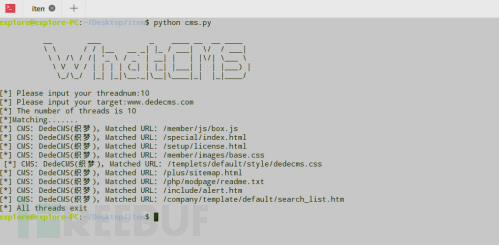
cool。。。这样就简单的实现CMS识别。。。
最近好久不写文章,手法生疏了,各位dalao见谅。。。。
最后,分享一首歌。。Kris Wu的天地
特别喜欢‘江湖人说我不行,古人说路遥知马力,陪我走陪我闯天地,我从不将就我的命运’这块。。
本集完
有问题大家可以留言哦~也欢迎大家到春秋论坛中来玩耍呢! >>>点击跳转
作者:阿甫哥哥
- 0 文章数
- 0 关注者