


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
1.基础介绍
本期,我们将着重介绍elasticsearch的基本使用方法。
2.名词解释
在介绍elasticsearch的基本使用方法之前,我们先来了解一下在elasticsearch中常用名词的含义。
索引(Index):一个索引就是含有某些相似特性的文档的集合。
例如,你可以有一个用户数据的索引,一个产品目录的索引,还有其他的有规则数据的索引。一个索引被一个名称(必须都是小写)唯一标识,并且这个名称被用于索引通过文档去执行索引,搜索,更新和删除操作。
类型(Type):一个类型是你的索引中的一个分类或者说是一个分区,它可以让你在同一索引中存储不同类型的文档。
例如,为用户建一个类型,为博客文章建另一个类型。
文档(Document):一个文档是一个可被索引的数据的基础单元。
例如,你可以给一个单独的用户创建一个文档,给单个产品创建一个文档,以及其他的单独的规则。这个文档用JSON格式表现,JSON是一种普遍的网络数据交换格式。
在一个索引或类型中,你可以根据自己的需求存储任意多的文档。注意,虽然一个文档在物理存储上属于一个索引,但是文档实际上必须指定一个在索引中的类型。
3.基本使用
进入控制台
1.打开浏览器,访问:http://服务器IP:5601/
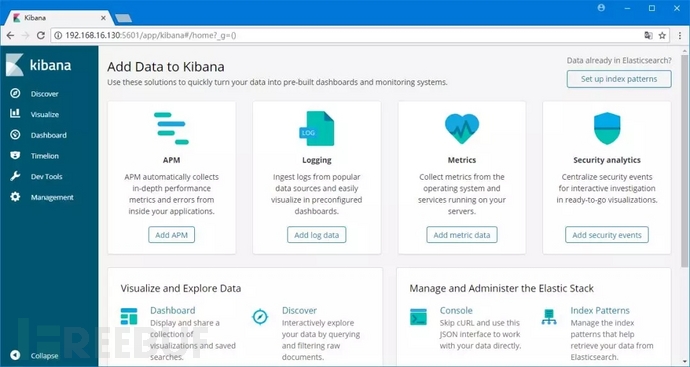
2.点击左边导航窗口的Dev Tools,进入开发者控制台。
访问数据的模式:
命令: ///
解释:请求方法 /索引名/类型/文档ID
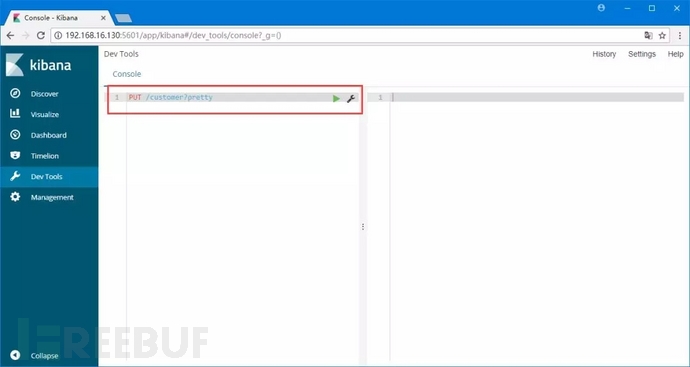
创建一个索引:
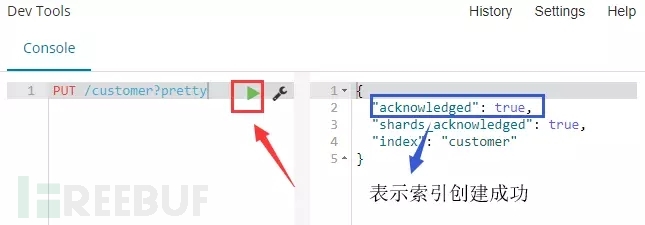
命令:PUT /customer?pretty
解释:使用PUT方法创建了一个名为“customer”的索引。我们简单的在请求后面追加pretty参数来使返回值以格式化过美观的JSON输出(如果返回值是JSON格式的话)
命令运行:在开发者控制台中输入创建索引的命令。
点击命令上的运行按钮,可在右边看到运行结果。
查看已创建索引:
命令:GET /_cat/indices?v
解释:使用GET方法进行数据查询,命令在这里是查询当前存在的所有索引。
命令运行:可在右边看到已创建的索引customer
创建一个文档:
命令:
POST /customer/doc/1?pretty
{
"name": "John Doe"
}
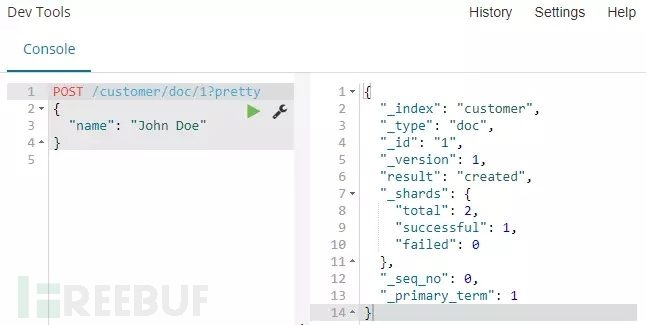
解释:使用POST请求方式,将一个简单的顾客文档放入customer索引中,这个文档ID为1。
命令运行:从下面截图我们可以看到,一个新的顾客文档已经在customer索引中成功创建。同时这个文档有一个自己的id,这个id就是我们在将文档加入索引时指定的。
删除一个索引:
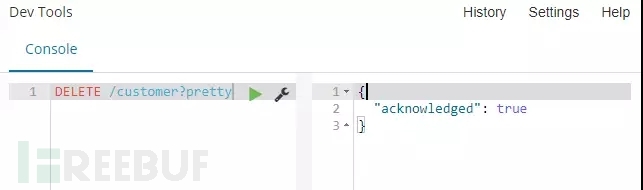
命令:DELETE /customer?pretty
解释:使用DELETE请求方式,将customer索引删除,并使用pretty参数美化输出。
命令运行:以下截图结果意味着我们的索引已经被删除。
添加文档数据:
命令:
POST /customer/doc?pretty
{
"name": "Mike"
}
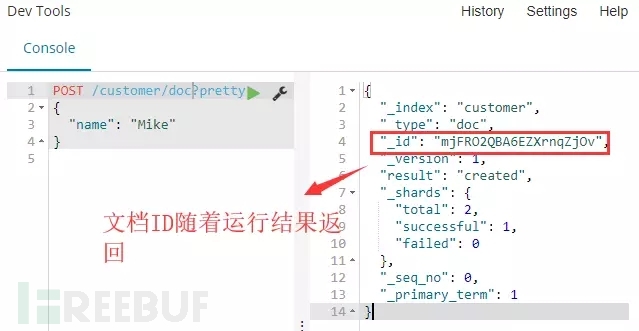
解释:上面创建一个文档的操作中,我们有指定文档ID为1。而实际上,当将文档加入索引时,ID部分并不是必须的。如果没有指定,Elasticsearch将会生产一个随机的ID,然后使用它去索引文档。实际Elasticsearch生成的ID(或者是我们明确指定的)将会在API调用成功后返回。
命令运行:如下图命令运行结果可以看到,在没有指定文档ID的情况下,随机的文档ID会被生成并随着运行结果返回。
修改文档数据:
命令:
PUT /customer/doc/1?pretty
{
"name": "Jane Doe"
}
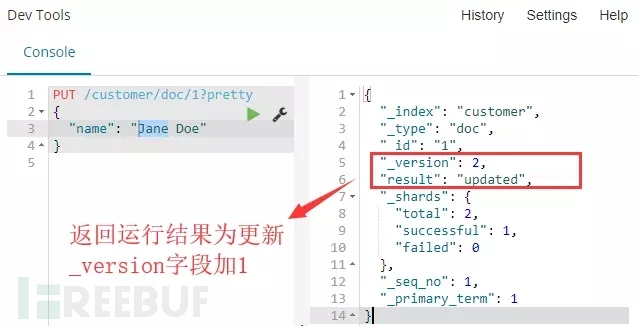
解释:如果我们再次执行上面的请求,以相同的文档内容或者是不同的,Elasticsearch将会用这个新文档替换之前的文档(就是以相同的ID重新加入索引)。
命令运行:通过下图运行结果可以看到,每次操作数据,_version字段将自加1。
删除文档数据:
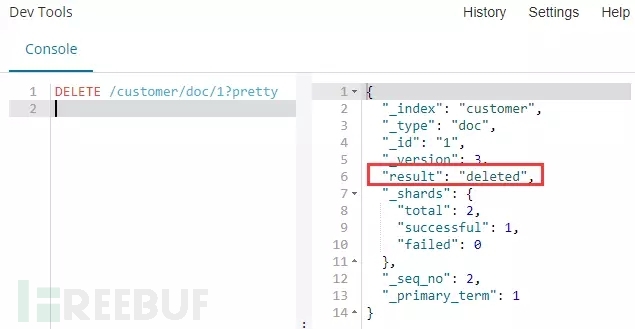
命令:DELETE /customer/doc/1?pretty
解释:使用DELETE请求方式,将customer索引下ID为1的文档删除,并使用pretty参数美化输出。
命令运行:以下截图结果意味着我们ID为1的文档数据已经被删除。
批处理:
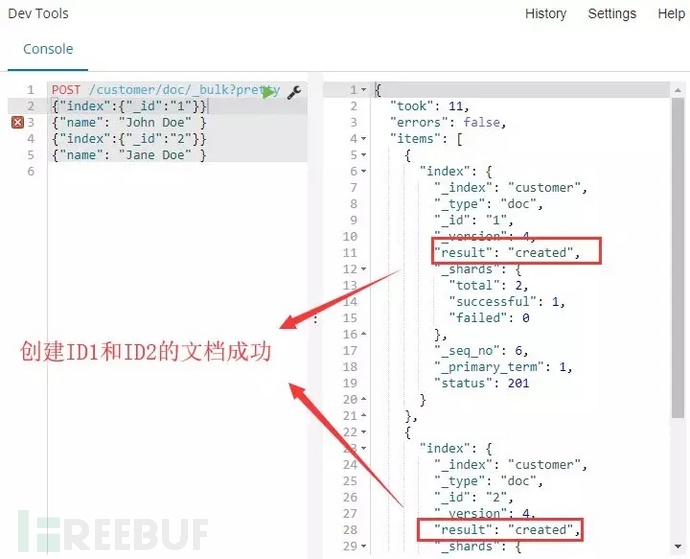
命令1:
POST /customer/doc/_bulk?pretty
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
解释:调用批处理方法_bulk,先是创建/更新ID为1的文档,然后创建/更新ID为2的文档
命令运行:成功创建ID为1、2的文档。
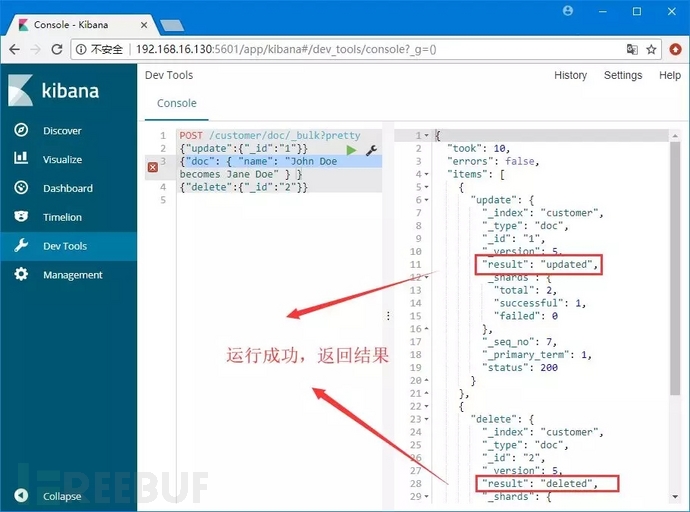
命令2:
POST /customer/doc/_bulk?pretty
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}}
解释:调用批处理方法_bulk,先是更新ID为1的文档,然后删除ID为2的文档。
命令运行:
4.总结
如有任何疑问,欢迎喜欢技术的小姐姐们艾特漏斗社区那位最帅的萌新小哥哥。下次,将分享的文章是《大数据搜索引擎elasticsearch基本使用篇(二)》。

- 0 文章数
- 0 关注者