


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
用户模式读取内核内存
我本打写一篇介绍这有多严重的文章,但并没有,我想你应该知道其严重性,如果没有的话,你应该读读这篇博客。如果你还觉得这东西微不足道,你更应该看看这篇文章。
内存子系统
我想多数人可能会立刻会想到,没有权限的进程是不可能读取内核内存的,因为有页表机制。这也是指令集架构或是ISA所说的,但是想说这不太领我满意,我们需要更深入些的开始。
运行在核心的软件需要内存,会起动一个所谓的“加载”命令。加载命令会在多个阶段处理,直到无返回数据或是有错误发生。下图展示了一个简化版的子系统。
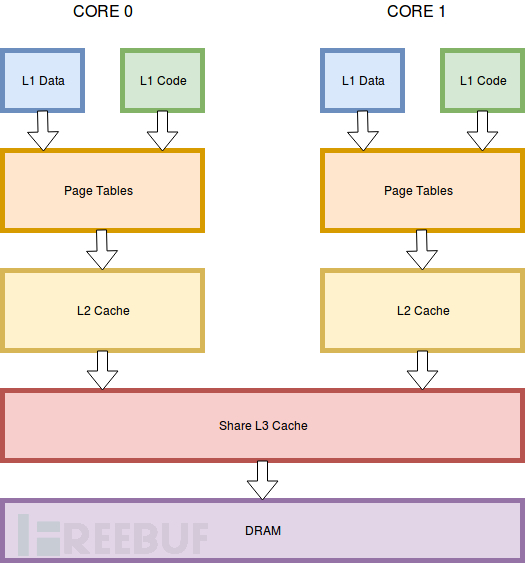
内存层次结构
包括操作系统在内的软件使用虚拟寻址来启动加载(CPU内部的地址读取)。第一阶段处理在L1高速缓存。L1高速缓存分数据和指令高速缓存。L1高速缓存也叫VIPT或是虚索引,物理标记高速缓存。意味着可以直接加载虚地址请求查找数据。同核中的核心位置一样让L1出奇的快。如果在L1没找到请求加载数据,必须继续到下面的缓存层。这种情况是页表就发挥了作用。页表将虚拟地址转换成物理地址。这本质就是如何在x64上分页有效。转换的过程中是有权限检查的。一旦我们有了物理地址,CPU就可以继续轮询L2和L3缓存了。
PITP缓存(物理索引、物理标记)在查找完成之前就需要在页表中翻译。如果高速缓冲区中没有,CPU会请求内存控制器去主内存中取。L1数据加载延迟是5个时钟周期,而从内存中加载需要200个时钟周期。页表安全检查和L1定位之前,我们可看到,在这点上,页表的参数太简单了。这已经Intel的软件开发者手册中指明,安全设定是跟着数据复制到L1缓冲中的。
推测执行
人这到下一节,我会概述理论背后的论点,但也只是概述。对这个感兴趣的可以看我在1月3日在HackPra上讲的,关于管道的更多细节,尽管可能有些不同。Intel的CPU是超标量。管道化CPU,并且使用推测执行有很重要的位置,也是为什么我认为他 能从无权限的用户模式下访问内核内存的。下图是一个简单的管道视图。
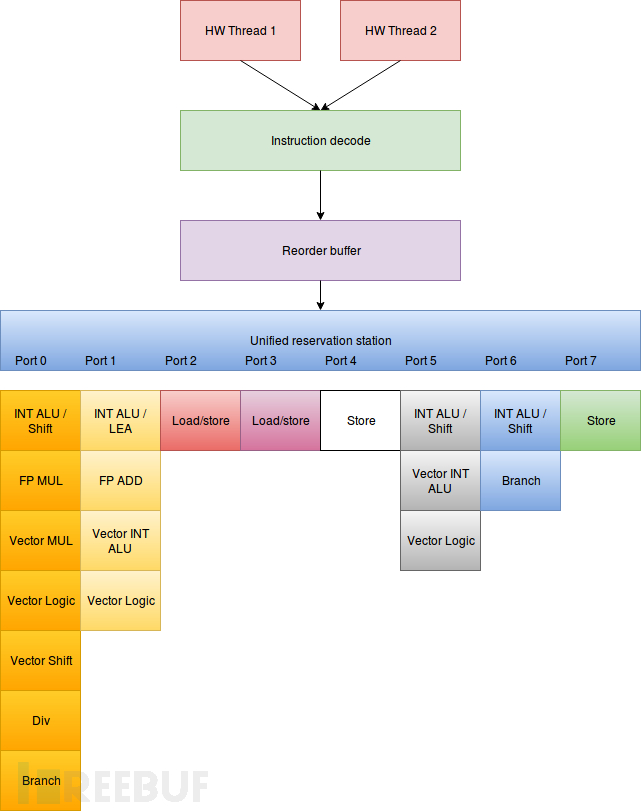
管道
管道从指令解码器开始。指令解码器读取内存字节,解析缓存区并输出指令。将指令解码成微指令。指令是由微指令构成的。必须要考虑的是x86 CPU是复杂指令集计算机和使用精简指令集的后端。也不一定真是这样的,但是我们可以先这样考虑。微指令在(精简指令)排队进入重排缓存。微指令保持到所有它的相关依赖都被处理。每一个周期 所有依赖的微操作都会按排在可用的执行单元,按先进先出的顺序。因为许多专门的执行单元,很多微指令是同时完成,更重要的是,由于执行单元的依赖性和瓶颈,微指令不需要与进入记录缓存相同的顺序执行。当一条微指令结束执行,并且结果异常时,会被重添到重排缓存区中,解决与其它微指令的依赖关系。当给定指令的所有微指令都被执行,并且被重新排列到重排缓冲的头部时,它进入失效处理流程。因为微指令是在重排缓存区的头部,我们可以确定指令失效和微操作进队列是相同顺序。如果一个异常被标记为在一个微操作失效时又重进重排序缓存,而引起微操作所属的那条指令中断。就算整个指令完成之前,引起中断的微操作会被执行很长时间,也会引起中断。中断触发会导致管道刷新,在重排缓冲区的微指会被丢弃,指令解码器复位。如果没有抛出异常,结果会提交给寄存器。实质上这是托马苏洛算法的实现,允许多指令同时执行,并最大效率的得用资源。
烂用预测执行
想象下面的指令在用户模式执行
mov rax,[some kernel mode address]
它会引起中断失效。但不是很清楚指令执行结束和实际退进之间发生了什么。我们知道,一旦失效,任意信息,可能或可能没有被读了,因为他永远不会被提交到寄存器。然而,也许我们还是有有机会看到,如果intel是完全按托马苏洛实现来读的。想象MOV指令集的结果重新在重排缓存中标记,指令失效应该引起中断和丢弃对任何数据的读取。如果真这样我们可以执得另外的推测代码。
想象下面的代码。
mov rax, [Some kernel address]
mov rbx, [some usermode address]
如无依赖,两者同时执行。(是两个执行单元加载的)
第二条指令的结果永远不会提交到寄存器上,因为第一个指令抛出中断,它就被丢弃了。但第二条指令会被推测执行,我们可以检测到,CPU的微指令架构也许会改变状态。在这种情况下,第二条MOV指令会被加载。
some user mode address
进入缓存层级结构,在结构异常处理处理异常之后, 我们可以观察更快的的访问时间。为了确定“一些用户的地址”不在缓存层次结构中,我可以使用在开始执行之前使用clflush指令。现在我们只需要一步就可以泄露内核内存信息。
Mov rax, [some kernel address]
And rax, 1
Mov rbx,[rax + Some user mode address]
如果后两条指令被执行被预测执行,加载了的有问题的依赖于“某些内核地址”的地址值,并且因此,地址被加载到缓存中,也许是因为不同的缓存行被加载了。这个缓存活动,我们可以通过flush + load缓存攻击来观察。我们面对的第一个问题是,我们必须确保,第二条,第三条指令在第一条指令失效前执行。要保证竞争条件优先。怎么做?我们使用与我们需要的执行单元不同的相关指令填充重新排序缓冲区。然后我们添加上面的代码。这种依赖性会强制CPU在添冲指令时,执行一个微操。
使用与泄漏代码中使用的执行单元不同的执行单元,确保CPU在填冲模式下,可执行这些利用代码。是直接填充模式,我使用300 ADD reg64. 我选择了ADD RAX, 0x141. 我这么选择是因为我们有两个执行单元可以执行这些指令(整数),因为必须顺序执行,所以这些执行单元中将一直对我们泄露代码可以。因为内核读取MOV指令和我的泄露MOV指令必须顺序执行,数据读取的泄露指令不能在缓存中,总执行时间大概是400个时钟周期,如果内核地址不能被缓存,和ADD RAX,0x041比来说,这是一个非常高的成本。因为这个原因,我注意到了我访问的内核地址被加载到了缓存层级中。我用两种方法确定这个,首先是我执行一个系统命令去访问这块内存。
其次,我使用prefectht0 指令提高地址在L1上被加载几率。gurss认为预取指令可以被加载到缓存区,虽然没有权限。另外,他们还表明页面表遍历可能会中止,这肯定意味着我得不到结果。但是L1中已有了数据会避免这种遍历。
所有这些架设都是建立在,我对intel实现的托马苏洛算法的实现的推测。
1) 中断还是会继续预测执行。
2) 在预测执行和失效之间取得竞争条件优势。
3) 在预测执行期间也可以加载缓存。
4) 尽管中断标记了,数据还有。
评估
我在i3-5005u的Broadwell CPU上做了测试。发现没法单独测试假定1、2和3条的方法。因些,我上面写的概要代码,用下面的代码替换。
Mov rdi, [rdi]; where rdi is some kernel mode address
rdi是某处内核模式的地址
mov rdi, [rdi + rcx+0]; where rcx is the Some user mode address
rcx是某处用户模式的地址
在异常处理处理异常结果后,同时的访问了“某处用户模式的地址”。运行1000次并取10次最慢的。
首先我用上面第二行内核地址为0的值运行一次。第二次把第二行注释掉运行。这允许我测试在推测执行中是否有一个旁路通道。结果总结看下图。(均值与方差: mean= 71.22 std = 3.31; mean= 286.17 std = 53.22)
可以看到,在推测执行过过程中有一个隐蔽的通道。 第二步,确何读取的内核地址值是4096。 现在如果实际读取内核模式数据,第二行会去取下一面的缓存行。因些,我们希望慢一点的访问“某用户模式的地址”
推测性的读取应该访问高速缓存下一行。我选的偏移量是4096防止由于硬件影响读取已在缓存行的大小。妙的的,读不了,Intel是不允许访问空值结果的。我对要访问的缓存行进行二次确认,确定这个地址没有被加载到缓存中。貌似Intel已经处理了非法读取内核的模式内存。但不复制结果到重排缓存。这次实验不灵了, 好奇的添加了 ADD RDI, 4096指令,在测试代码的第一行后,并且可以确这代码确定执行了推测,结果也是旁路的。
潘多拉盒子
在没有权限的情况下去读内核模式时会产生消极的结果。感觉打开了潘多拉的盒子。测试过程中有两个积极的结果。首先,Intel实现的托马苏洛算法不是旁路通道安全。尽管没有正常的结果提交,我们还是可以访问推测执行的结果。其次,从测试结果来看,内核模式和用户模式间虽有隔离,但推测执行的确还是不会被阻止。这对对安全来说这不太好。
首先给微架构旁路攻击添油加火,我们从实际运行和推测运行中都可以推演出一些信息。似乎我们可以影响推测运行结果,并且不通过影响缓存,BTB看Dmitry Evtyushkin and Dmitry Ponomarev [5]的实例。因些,增加了更多让攻击者对CPU的微架构进行旁路攻击的可能性。这也让代码编写更复杂,绝不是什么好事。
很难说这个能发展到什么程度。
但我立刻猜到是vmexit处理指令失效。
另外,推测执行不严格遵守隔离机制,这是个问题,实际上推测执行也是可以被完成执行的。
英文原文:https://cyber.wtf/2017/07/28/negative-result-reading-kernel-memory-from-user-mode/
- 0 文章数
- 0 关注者