


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
1 背景介绍
资产分类分级,又称数据识别,是整个数据安全的基石,无论是风险检测、数据治理还是数据合规,其动作对象都是数据资产。现今随着数据量日益增长,对所有数据采取均等的管理策略既不现实也非必要,因此我们迫切需要实施一套精准的数据识别机制,以便准确地界定数据所属的业务范畴(分类)和确定其敏感性等级(分类)。结构化数据资产分类分级业界讨论较多,这里不再多做讨论,本文将专注阐述非结构化数据资产分类分级。
非结构化数据识别相对结构化数据识别更具有挑战性这个是普遍的共识,其难点和挑战具体体现在:
非结构化数据形式和内容无明确的规范,识别标准如何确定?识别水位如何评估?
非结构化数据多源异构,处理链路复杂,如何确保数据在整个识别过程中实现无缝的输入和输出?
非结构化数据规模庞大且多元化,如何设计一套全面的策略框架,以适应其多样性和复杂性,保证在海量数据处理场景下稳定高效的运行?
非结构化数据在成功识别并汇聚形成庞大的资产库之后,我们应如何策划技术选型,以确保这一资产库的全面性、准确性和高效性得到充分保障?
2 识别系统流程
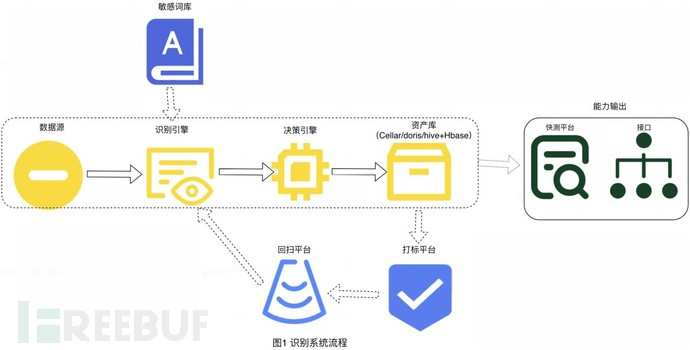
非结构数据识别整个流程比较复杂,在正式阐述识别建设之前,我们先简要介绍下识别流程各个环节所有做的事情,便于后文阅读的理解:
数据源:承接各类数据源的接入;
识别引擎:用于数据的接入、下载、解压、解析等环节,图片识别还包括OCR环节等,可以理解为做策略之前的准备工作;
决策引擎:构建策略的地方,基于识别引擎给到的文本信息/图片信息,进行策略建设,最终输出识别结果;
资产库:资产库存储识别沉淀的属性数据(Cellar/doris/hive)与解析的文本数据(hbase),资产库具备两个作用,一个是相同文件多次送审,可从资产库直接获取之前的识别结果,不用再重复识别,提高识别效率,另一个是存储识别结果作为总出口赋能下游;
能力输出:提供两种可获得实时识别能力的方式,快测提供界面化实时查询能力、API接口提供接口调取能力;
敏感词库:承载关注的敏感指标、pii信息、敏感关键字等,用于决策平台构建因子信息;
打标平台:从识别结果中抽样数据并在其上面进行打标最终得到准召指标的地方;
回扫平台:存量资产识别信息的更新,筛选资产库需重新进行识别的数据,进行再次送审,更新资产识别信息;
3 识别建设
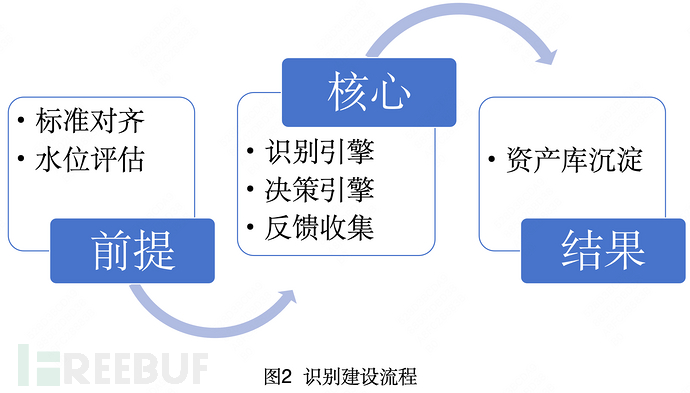
识别建设项目被细分为三个主要阶段六个关键环节。首先,在建设准备阶段,我们确立了一致的标准基准,进而评估当前的识别水位。其次,核心建设阶段,数据源的接入经过一系列转化形成基础文字素材(识别引擎),在决策引擎构建策略完成密级判断,将识别结果沉淀为资产库。最后,通过多渠道收集识别情况反馈信息,推动策略的持续优化。
3.1 标准对齐
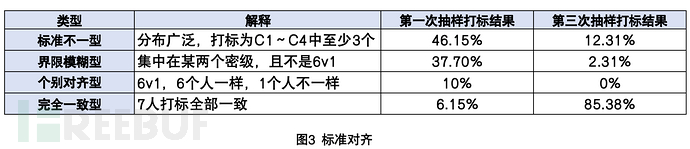
一般数据密级定级标准、判定依据更多是从数据泄露后对数据主体影响的角度来说明这个定义,如某类数据泄漏对公司带来多大损失,这样带来的问题是无法抽象量化进行自动化分类分级,且对于同一个文件,不同于的人经常会有不同的密级理解。所以识别建设的首要前提就是对齐密级标准,建立有共识的SOP,我们采取的是抽样打标对齐认知的方式来解决这个问题。
抽样1000个文件(排除掉明显的白文件,比如报销单、证件、书籍等),项目组成员独立打标,最终统计出打标不一致的文件进行共同讨论,对齐认知,这样总共来了三轮,基本实现了大家对文件密级有了较为落地的感知,同时落地了初版sop,此处涉及敏感信息,不多做展开。
3.2 水位评估
在识别领域,一个长期存在且非常棘手的问题是难以量化当前进展的具体成效,即缺乏明确的指标来衡量当前的进展状态。这就导致了一个显著的挑战:尽管投入了大量的人力资源,却难以感
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者