


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
国家太空安全是国家安全在空间领域的表现。随着太空技术在政治、经济、军事、文化等各个领域的应用不断增加,太空已经成为国家赖以生存与发展的命脉之一,凝聚着巨大的国家利益,太空安全的重要性日益凸显[1]。而在信息化时代,太空安全与信息安全紧密地结合在一起。
2020年9月4日,美国白宫发布了首份针对太空网络空间安全的指令——《航天政策第5号令》,其为美国首个关于卫星和相关系统网络安全的综合性政策,标志着美国对太空网络安全的重视程度达到新的高度。在此背景下,美国自2020年起,连续两年举办太空信息安全大赛“黑掉卫星(Hack-A-Sat)”,在《Hack-A-Sat太空信息安全挑战赛深度解析》一书中有详细介绍,本文介绍了Hack-A-Sat黑掉卫星挑战赛的寻找恒星1(centroids)这道赛题的解题过程。
题目介绍
Here is the output from a CCD Camera from a star tracker, identify as many stars as you can! (in image reference coordinates) Note: The camera prints pixels in the following order (x,y): (0,0), (1,0), (2,0)... (0,1), (1,1), (2,1)...
Note that top left corner is (0,0).
主办方告诉参赛者在星跟踪器上有一个CCD相机,它拍摄了一些照片,要求参赛者从这些照片中找出尽可能多的恒星,使用图片坐标系表示恒星位置。需要注意的是,相机打印像素是按照 (0,0), (1,0), (2,0)... (0,1), (1,1), (2,1)...的顺序,图片最左上角的坐标是(0,0),但是每个坐标的第一个数字表示行还是列,并没有明确。
编译及测试
这个挑战题的代码位于centroids目录下,查看challenge、solver目录下的Dockerfile,发现其中用到的是python:3.7-slim,为了加快题目的编译进度,应在centroids目录下新建一个文件sources.list,内容如下:
deb https://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb-src https://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb https://mirrors.aliyun.com/debian-security/ bullseye-security main
deb-src https://mirrors.aliyun.com/debian-security/ bullseye-security main
deb https://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb-src https://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb https://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
deb-src https://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
将sources.list复制到challenge、solver目录下,修改challenge、solver目录下的Dockerfile,在所有的FROM python:3.7-slim下方添加:
ADD sources.list /etc/apt/sources.list
在所有pip命令后添加指定源:
打开终端,进入centroids所在目录,执行:
sudo make build
输入命令make test进行测试,提示错误,如图2-20所示。
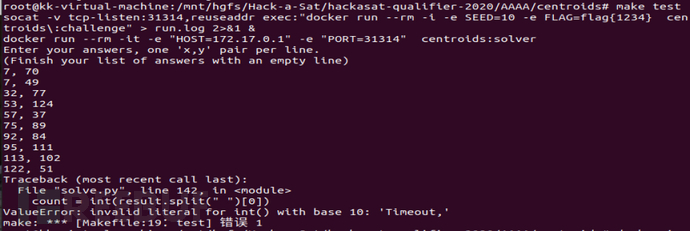
图2-20 centroids挑战题执行make test命令时的错误信息
发现提示的是ValueError错误,应该是在运行solve.py过程中,接收到“Timeout”字符,程序无法识别,所以报错退出。因为连接主办方服务器解题时,如果超出给定的时间,服务器就会发送“Timeout, Bye”字符串并断开连接,所以这是解题超时引起的问题。
查看centroids/challenge/challenge.py文件,如图2-21所示。发现如果未对TIMEOUT环境变量赋值,其默认值为10s。
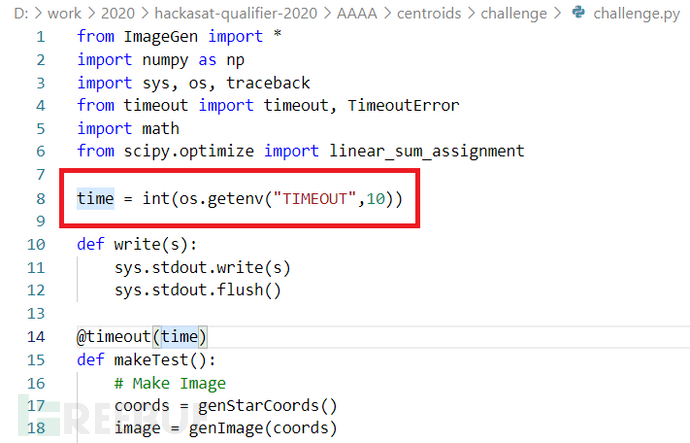
图2-21 centroids挑战题TIMEOUT默认值
查看这道题目的Makefile文件,其test部分内容如下:
test:
socat -v tcp-listen:${CHAL_PORT},reuseaddr exec:"docker run --rm -i -e SEED=$(SEED) -e FLAG=flag{1234}${CHAL_NAME}\:challenge" > run.log 2>&1 &
docker run --rm -it -e "HOST=${CHAL_HOST}" -e "PORT=${CHAL_PORT}" ${CHAL_NAME}:solver
发现在docker run命令中只给SEED和FLAG环境变量赋了值,且未对TIMEOUT环境变量赋值,所以TIMEOUT使用默认值10s。但是使用make test命令进行测试时,执行docker run命令开启容器是需要占用时间的,导致解题程序未运行完成就超时了。
解决这个问题,只需给TIMEOUT环境变量赋一个长点的时间值即可。对Makefile文件做如下修改:
test:
socat -v tcp-listen:${CHAL_PORT},reuseaddr exec:"docker run --rm -i -e SEED=$(SEED) -e FLAG=flag{1234} -e TIMEOUT=60${CHAL_NAME}\:challenge" > run.log 2>&1 &
docker run --rm -it -e "HOST=${CHAL_HOST}" -e "PORT=${CHAL_PORT}" ${CHAL_NAME}:solver
再次使用make test命令进行测试,顺利通过,测试输出结果如下:
socat -v tcp-listen:31314,reuseaddr exec:"docker run --rm -i -e SEED=10 -e FLAG=flag{1234} centroids\:challenge" > run.log 2>&1 &
docker run --rm -it -e "HOST=172.17.0.1" -e "PORT=31314" centroids:solver
Enter your answers, one 'x,y' pair per line.
(Finish your list of answers with an empty line)
7, 70
7, 49
32, 77
53, 124
57, 37
75, 89
92, 84
95, 111
113, 102
122, 51
Count Left: 4
Enter your answers, one 'x,y' pair per line.
(Finish your list of answers with an empty line)
25, 124
29, 90
34, 71
39, 51
62, 78
72, 111
100, 58
113, 122
114, 87
122, 104
Count Left: 3
Enter your answers, one 'x,y' pair per line.
(Finish your list of answers with an empty line)
12, 27
19, 100
45, 63
48, 40
59, 86
63, 64
63, 119
89, 115
99, 5
123, 32
Count Left: 2
Enter your answers, one 'x,y' pair per line.
(Finish your list of answers with an empty line)
7, 87
25, 11
36, 53
36, 120
64, 80
75, 23
78, 115
86, 93
99, 8
116, 40
Count Left: 1
Enter your answers, one 'x,y' pair per line.
(Finish your list of answers with an empty line)
7, 34
8, 121
33, 111
51, 121
60, 12
69, 117
75, 82
95, 39
108, 60
112, 105
Count Left: 0
Done
flag{1234}
由测试结果可以看出,本挑战题会给出5组照片数据,参赛者需要找出照片中恒星的坐标才能得到flag。
为了显示照片数据,进行如下测试:
(1)打开一个终端,输入命令:
sudo socat -v tcp-listen:31314,reuseaddr exec:"docker run --rm -i -e SEED=10 -e FLAG=flag{1234} centroids\:challenge" > run.log
(2)打开另一个终端,输入命令:
nc 127.0.0.1 31314
(3)在第二个终端中会输出一长串照片数据,形式如下(摘录了部分):
1,3,3,5,7,3,5,5,2,7,4,6,5,4,7,0,0,5,8,5,6,2,9,2,6,3,2,8,1,7,4,9,5,5,8,6,3,0,1,7,8,6,5,9,7,4,7,6,0,8,7,3,5,2,9,5,1,9,8,3,6,9,5,6,4,9,9,0,4,3,1,2,7,4,3,9,6,2,7,9,7,4,7,5,5,9,9,5,2,4,4,3,6,0,1,9,9,3,9,7,9,3,8,6,8,0,3,4,8,2,0,3,9,1,7,9,2,1,3,2,2,4,5,0,8,1,7,0
7,3,2,7,0,4,9,9,4,8,6,2,3,9,8,9,2,1,1,4,2,9,4,7,9,4,0,0,4,6,1,2,7,7,9,7,8,5,6,7,1,3,3,3,1,4,7,9,0,8,7,4,2,4,3,8,2,0,5,1,2,6,8,8,8,7,8,3,6,1,8,9,2,0,7,9,8,0,4,3,4,1,7,6,6,9,7,3,8,9,1,5,7,3,3,7,5,6,2,6,4,6,2,1,8,1,1,4,4,9,4,3,3,2,7,0,6,0,2,0,7,2,6,4,9,1,4,0
......
7,0,0,6,3,8,9,5,2,1,0,6,2,8,8,1,9,8,3,4,8,0,0,6,4,7,8,9,7,9,1,9,6,8,5,4,9,7,7,2,3,9,7,4,0,8,7,0,5,4,4,9,2,9,8,6,3,6,9,6,0,1,2,3,9,3,0,0,9,1,3,7,6,6,5,0,4,3,3,9,6,2,9,1,7,5,2,8,1,8,5,1,1,5,5,2,0,2,2,6,7,0,8,3,0,3,4,0,6,3,2,6,2,7,0,7,4,0,5,2,9,4,1,6,4,8,1,1
9,8,7,4,9,2,4,1,6,6,1,7,1,3,5,7,0,5,6,4,7,4,4,4,6,7,7,5,7,6,7,9,2,6,9,0,7,9,6,9,3,4,7,7,8,7,3,1,8,7,0,2,9,7,8,9,6,6,6,9,1,9,3,5,0,8,8,1,4,4,4,4,2,4,8,0,5,1,2,2,5,0,7,0,4,8,2,7,4,7,9,0,9,7,5,0,4,8,1,0,2,8,4,3,0,2,3,4,4,8,5,0,5,5,9,8,7,7,8,0,2,2,2,3,0,2,5,3
Enter your answers, one 'x,y' pair per line.
(Finish your list of answers with an empty line)
给出的照片数据共有128行,每行数据有128个用逗号分隔开的数字。在数据的最后要求输入“x, y”形式的坐标信息。从给出的数据分析,这应该是大小为128×128的照片信息,每个像素最大值是255,所以应该是8bit灰度照片。
此外,解答本挑战题默认有10s的时间限制,超过10s还没有给出坐标信息,就会提示超时,并断开连接。但是再次连接,可以发现获取的照片数据还是与上次一样,这应该是题目设计上的一个缺陷。
相关背景知识
1.聚类算法简介
1)什么是聚类
聚类(Clustering)是指按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大,即聚类后同一类的数据尽可能聚集到一起,不同类的数据尽量分离。
2)聚类和分类的区别
聚类:把相似的数据划分到一起,具体划分时并不关心这一类的标签,目标就是把相似的数据聚合到一起。聚类是一种无监督学习(Unsupervised Learning)方法。
分类(Classification):把不同的数据划分开,其过程是先通过训练数据集获得一个分类器,再通过分类器预测未知数据。分类是一种监督学习(Supervised Learning)方法。
监督学习和无监督学习都是机器学习中的概念,两者区别如下:
- 监督学习必须要有训练数据集与测试样本。在训练数据集中找规律,而对测试样本使用这种规律。而无监督学习没有训练数据集,只有一组数据,在该组数据集内寻找规律。
- 监督学习就是识别事物,识别的结果表现在给待识别数据加上了标签。因此,训练数据集必须由带标签的样本组成。而无监督学习只有要分析的数据集本身,预先没有什么标签。若发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不以与某种预先分类标签对上号为目的。
3)数据对象间的相似度度量
对于数值型数据,可以使用表2-2中的相似度度量方法。


5)数据聚类的算法
数据聚类的算法主要可以分为划分式聚类算法(Partition-based Methods)、基于密度的聚类算法(Density-based Methods)、层次化聚类算法(Hierarchical Methods)、基于网格的聚类算法(Grid-based Methods)、基于模型的聚类算法(Model-based Methods)等。本书只对用到的层次聚类算法进行介绍。
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构,数据集的划分即可采用“自底向上”的聚合策略,也可采用“自顶而下”的分拆策略。将数据集划分为一层一层的簇,后面一层生成的簇基于前面一层的结果。层次聚类算法一般分为两类:
- 聚合(Agglomerative)层次聚类:又称自底向上的层次聚类,每个对象最开始都是一个簇,每次按一定的准则将最相近的两个簇合并生成一个新的簇,如此往复,直至最终所有的对象都属于一个簇。本节主要关注此类算法。
- 分拆(Divisive)层次聚类:又称自顶向下的层次聚类,最开始所有的对象均属于一个簇,每次按一定的准则将某个簇划分为多个簇,如此往复,直至每个对象均是一个簇。
聚合层次聚类的算法流程:
① 计算数据集的相似矩阵;
② 假设每个样本点为一个簇类;
③ 循环:合并相似度最高的两个簇类,更新相似矩阵;
④ 当簇类个数为1时,循环终止。
为方便读者更好地理解,我们以6个样本点的数据集为例对聚合层次聚类算法进行图示说明(见图2-22)。
第一步:假设每个样本点都为一个簇类,计算每个簇类间的相似度,得到相似矩阵。
第二步:若B和C的相似度最高,合并簇类B和C为一个簇类。现在共有5个簇类,分别为A、BC、D、E、F。
第三步:更新簇类间的相似矩阵,相似矩阵的大小为5行5列;若簇类BC和D的相似度最高,则合并簇类BC和D为一个簇类。现在共有4个簇类,分别为A、BCD、E、F。
第四步:更新簇类间的相似矩阵,相似矩阵的大小为4行4列;若簇类E和F的相似度最高,合并簇类E和F为一个簇类。现在还有3个簇类,分别为A,BCD,EF。
第五步:重复第四步,若簇类BCD和EF的相似度最高,则合并这两个簇类;现在共有2个簇类,分别为A、BCDEF。
第六步:最后合并簇类A和BCDEF为一个簇类,聚合层次聚类算法结束。
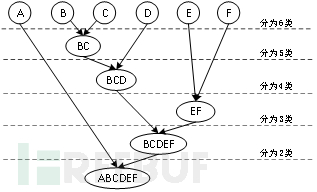
图2-22 聚合层次聚类算法示意图
2.层次聚类算法的Python实现
Python的第三方库SciPy包中提供了很多聚类算法,也包含了层次聚类算法,其包路径为scipy.cluster.hierarchy,下面介绍SciPy包中经常用到的几个函数。
(1)linkage函数。
linkage函数的功能是对n×m数据矩阵X的n个m维数据对象执行聚合层次聚类算法,返回一个(n-1)×4的层次树矩阵,该矩阵表示层次聚类树的生成过程,每一行代表一次合并簇的操作。层次树矩阵各列数据的含义如表2-3所示。簇的编号是从0开始的,n个数据对象的簇编号分别为0~n-1,之后每次合并簇后形成一个新簇,新簇的编号从n开始逐次加1。
表2-3 层次树矩阵各列数据的含义
列 序 号 | 含 义 |
1 | 本次需要合并的两个簇中第一个簇的编号 |
2 | 本次需要合并的两个簇中第二个簇的编号 |
3 | 本次合并的两个簇之间的距离值(并簇距离) |
4 | 两个簇合并形成的新簇所包含数据对象的个数 |
linkage函数的调用格式如下:
scipy.cluster.hierarchy.linkage(X, method='single', metric='euclidean')
(2)dendrogram函数。
dendrogram函数的功能是绘制聚合层次聚类的树形图,其调用格式如下:
scipy.cluster.hierarchy.dendrogram(Z,labels=None)
Z参数表示一个层次树矩阵,通常为linkage函数返回值;labels参数需要一个数组,用来表示在树图中的叶子节点上显示的标签,默认值为None。
(3)cut-tree函数。
cut-tree函数的功能是对聚合层次聚类算法生成的层次树进行切割,切割的依据既可以是切割点处所要保留的聚类数,也可以是切割高度,其实就是指定在层次树的哪一层进行切割。树切割后会产生剖面,同理对层次树进行切割会生成一些平面簇。cut-tree函数的返回值是一个包含n个元素的列向量,每个元素的值指出了其对应数据对象所属平面簇的序号(从0开始编号)。cut-tree函数的调用格式如下:
scipy.cluster.hierarchy.cut_tree(Z,n_clusters=None,height=None)
Z参数表示一个层次树矩阵,通常为linkage函数返回值;n_clusters参数表示切割点处所要保留的聚类数,height参数表示设定的切割高度,一般情况下这两个参数设置一个即可。
(4)inconsistent函数。
inconsistent函数的功能是计算层次树矩阵Z中每次合并簇得到的链接的不一致系数。inconsistent函数的调用格式如下:
scipy.cluster.hierarchy.inconsistent(Z, d=2)
参数d为正整数,表示计算涉及的链接的层数,可以理解为计算深度。默认情况下,计算深度为2。inconsistent函数的返回值也是一个(n-1)×4的矩阵Y,该矩阵各列数据代表的含义如表2-4所示。

(5)fcluster函数。
fcluster函数在linkage函数输出的层次树矩阵Z的基础上生成聚类,并返回聚类结果。返回值是一个长度为n的一维数组T,T[i]表示聚类后第i个数据对象所属簇的序号(从1开始编号)。fcluster函数的调用格式如下:
scipy.cluster.hierarchy.fcluster(Z, t, criterion='inconsistent', depth=2)
criterion参数规定了聚类使用的标准,其参数值的可选项有inconsistent(默认值)、distance等。t参数表示一个标量,用于设定聚类的阈值。当criterion参数的值为inconsistent时,fcluster函数会调用inconsistent函数进行不一致系数计算(depth参数指出进行不一致性计算时的最大深度,默认值为2),如果层次树中的一个节点和它的所有子节点的不一致系数小于或等于t,则该节点及其所有子节点被聚为一簇;当criterion参数的值为distance时,用距离值作为聚类标准,把并簇距离小于t的节点及其所有子节点聚为一簇。
(6)fclusterdata函数。
fclusterdata函数的功能是将n×m数据矩阵X中的n个m维数据对象按criterion、metric、method等参数的设置要求进行聚合层次聚类,返回一个长度为n的一维数组T,T[i]表示聚类后第i个数据对象所属簇的序号(从1开始编号)。由此可看出,fclusterdata函数的功能是linkage函数和fcluster函数的功能之和,实际上fclusterdata函数就是在其内部调用了linkage函数和fcluster函数。
scipy.cluster.hierarchy.fclusterdata(X,t,criterion='inconsistent',metric='euclidean', depth=2, method='single')
metric参数、method参数的含义与linkage函数中的同名参数一致,criterion参数、depth参数的含义与fcluster函数中的同名参数一致,可参考前面的介绍。
下面以一个例子对上述函数的用法进行说明。首先在Excel中用随机函数RAND()生成一个随机数据列表,取名为test.xlsx,其内容如图2-23所示。
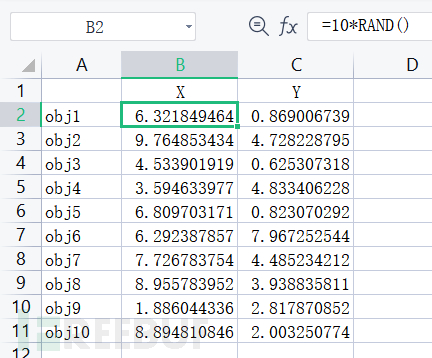
图2-23 test.xlsx文件内容
编写Python代码如下:
import pandas as pd
import scipy.cluster.hierarchy as sch
from matplotlib import pyplot as plt
# 自定义绘制散点图的函数,可以指定不同类的散点用不同的形状表示
def mscatter(x,y,markers=None,**kw):
import matplotlib.markers as mmarkers
plt.figure() # 新建一张图进行绘制
sc=ax.scatter(x,y,**kw)
if (markers is not None) and (len(markers)==len(x)):
paths=[]
for marker in markers:
if isinstance(marker,mmarkers.MarkerStyle):
marker_obj=marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path=marker_obj.get_path().transformed(marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
# pandas是Python语言中专门进行数据结构化存储和数据分析的工具包,很多其他包都以pandas的结构化
# 数据作为其函数的输入,因此数据处理的第一步大多使用pandas进行数据结构化存储,read_excel函数是
# pandas中读取excel文件的函数,index_col=0指定excel数据中第一列是类别名称
df = pd.read_excel("test.xlsx", index_col=0)
Z = sch.linkage(df, method='average')
print("--------linkage函数生成的层次树矩阵如下:---------")
print(Z)
R=sch.inconsistent(Z)
print('-------inconsistent(Z)输出的不一致性矩阵如下:-------')
print(R)
R=sch.inconsistent(Z,d=3)
print('-----inconsistent(Z,d=3)输出的不一致性矩阵如下:-----')
print(R)
R=sch.inconsistent(Z,d=4)
print('-----inconsistent(Z,d=4)输出的不一致性矩阵如下:-----')
print(R)
sch.dendrogram(Z, labels=df.index) # 绘制树形图,结果如图2-24所示
ctree=sch.cut_tree(Z,height=3.5)
print('---------cut_tree(Z,height=3.5)的返回结果为:------')
print(ctree)
m={0:'o',1:'v',2:'s',3:'x',4:'*',5:'D',6:'d',7:'p',8:'+',9:'h'} # 定义10类散点形状
# 由cut_tree结果指定每个点用什么形状表示
cm = list(map(lambda x:m[x],ctree.reshape(10).tolist()))
#绘制散点图,结果如图2-25所示
scatter = mscatter(df.values[:,0],df.values[:,1],markers=cm,c=ctree)
for i in range(df.values[:,0].size):
plt.text(df.values[i,0],df.values[i,1]-0.1,df.index[i],verticalalignment='top',\
horizontalalignment='center') # 在每个点旁标注数据名称
plt.show() # 显示出树形图和散点图
clust=sch.fclusterdata(df.values,0)
print('-------fclusterdata(df.values,0)的返回结果为:------')
print(clust)
clust=sch.fclusterdata(df.values,1)
print('-------fclusterdata(df.values,0.8)的返回结果为:----')
print(clust)
clust=sch.fclusterdata(df.values,3.5,criterion='distance',method='average')
print("fclusterdata(df.values,3.5,criterion='distance',method='average')的返回结果为:")
print(clust)
代码运行后,程序输出如下:
--------linkage函数生成的层次树矩阵如下:---------
[[ 0. 4. 0.49001163 2. ]
[ 1. 7. 1.13036928 2. ]
[ 6. 11. 1.69874621 3. ]
[ 2. 10. 2.04442855 3. ]
[ 9. 12. 2.51337867 4. ]
[ 3. 8. 2.64228337 2. ]
[13. 14. 4.37637006 7. ]
[ 5. 15. 5.45619629 3. ]
[16. 17. 5.69891506 10. ]]
-------inconsistent(Z)输出的不一致性矩阵如下:-------
[[0.49001163 0. 1. 0. ]
[1.13036928 0. 1. 0. ]
[1.41455774 0.40190318 2. 0.70710678]
[1.26722009 1.09913874 2. 0.70710678]
[2.10606244 0.57603214 2. 0.70710678]
[2.64228337 0. 1. 0. ]
[2.97805909 1.23346412 3. 1.13364544]
[4.04923983 1.98973691 2. 0.70710678]
[5.17716047 0.70404336 3. 0.74108303]]
-----inconsistent(Z,d=3)输出的不一致性矩阵如下:-----
[[0.49001163 0. 1. 0. ]
[1.13036928 0. 1. 0. ]
[1.41455774 0.40190318 2. 0.70710678]
[1.26722009 1.09913874 2. 0.70710678]
[1.78083138 0.69514907 3. 1.05379885]
[2.64228337 0. 1. 0. ]
[2.22458702 1.41697639 5. 1.51857368]
[4.04923983 1.98973691 2. 0.70710678]
[3.78859533 1.59737409 6. 1.19591255]]
-----inconsistent(Z,d=4)输出的不一致性矩阵如下:-----
[[0.49001163 0. 1. 0. ]
[1.13036928 0. 1. 0. ]
[1.41455774 0.40190318 2. 0.70710678]
[1.26722009 1.09913874 2. 0.70710678]
[1.78083138 0.69514907 3. 1.05379885]
[2.64228337 0. 1. 0. ]
[2.0422174 1.3438042 6. 1.73697378]
[4.04923983 1.98973691 2. 0.70710678]
[3.11504123 1.86611678 8. 1.38462601]]
---------cut_tree(Z,height=3.5)的返回结果为:------
[[0]
[1]
[0]
[2]
[0]
[3]
[1]
[1]
[2]
[1]]
---fclusterdata(df.values,0,method='average')的返回结果为:---
[1 3 2 6 1 7 4 3 6 5]
---fclusterdata(df.values,0.8,method='average')的返回结果为:---
[1 2 1 3 1 3 2 2 3 2]
-------fclusterdata(df.values,3.5,criterion='distance',method='average')的返回结果为:------
[1 2 1 3 1 4 2 2 3 2]
由cut_tree(Z,height=3.5)的返回结果可以看出,按height=3.5进行cut_tree操作后,得到的簇有4个,序号分别为0~3,每个数据对象对应的簇序号在cut_tree函数返回的列向量中标注了出来,在如图2-25所示的散点图中也用数据点的不同颜色和形状表示出了每个点分属的簇。dendrogram函数绘制的树形图如图2-24所示,树形图记录了簇聚合的顺序,从树形图中也可以看出在树的不同位置剪切可得到不同的聚类数目,当剪切高度为3.5时,正好分为4个簇。从程序输出还可看出,这个聚类结果也可由fclusterdata函数得到,使用distance作为聚类标准,将阈值t设为3.5即可。
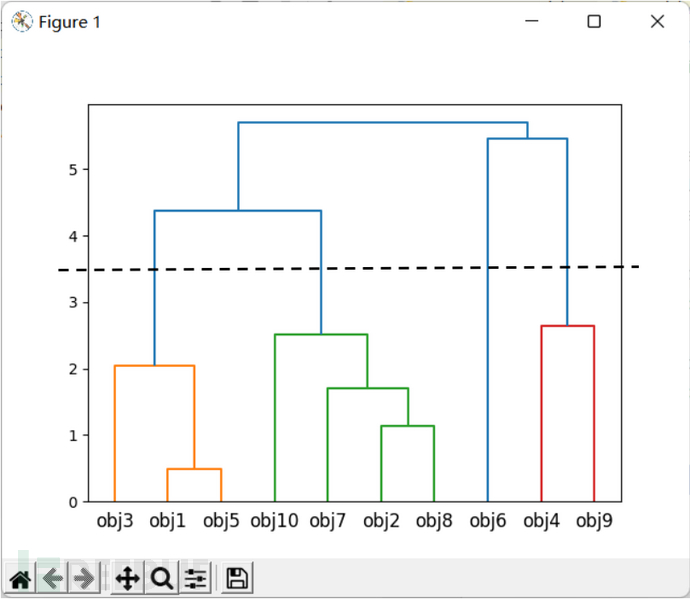
图2-24 dendrogram函数绘制的树形图
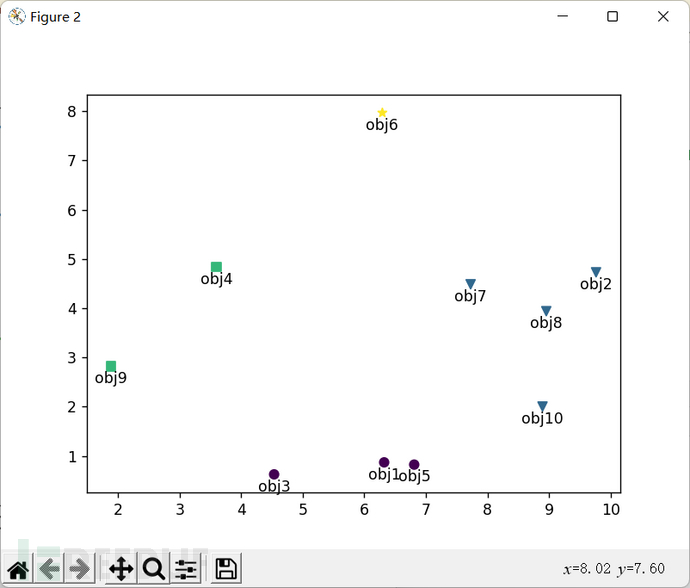
图2-25 按height=3.5进行cut_tree操作后得到的数据对象散点图
由inconsistent函数的输出可以看出,当计算深度d不同时,得到的不一致系数也不同,一般而言采用默认深度d=2即可。不一致系数可用来确定最终聚类的个数。在聚类过程中,若某次聚类所对应的不一致系数较上一次有大幅增加,说明本次聚类的效果不好,而上一次聚类效果较好。在使得聚类个数尽量少的前提下,可参照不一致系数的变化,确定最终的聚类个数。
由fclusterdata函数的输出可以看出,在其采用inconsistent标准时,聚类得到的簇的数目随着t的变大而减小。当t=0时,若层次树中的一个节点和它的所有子节点的不一致系数小于或等于0,则该节点及其所有子节点被聚为一簇,如图2-26所示,10个对象分为了7个簇。同理,当t=0.8时,得到的聚类结果如图2-27所示,10个对象分为了3个簇。要得到想要的聚类结果,需要结合计算出得不一致系数根据需要调整t的参数值。
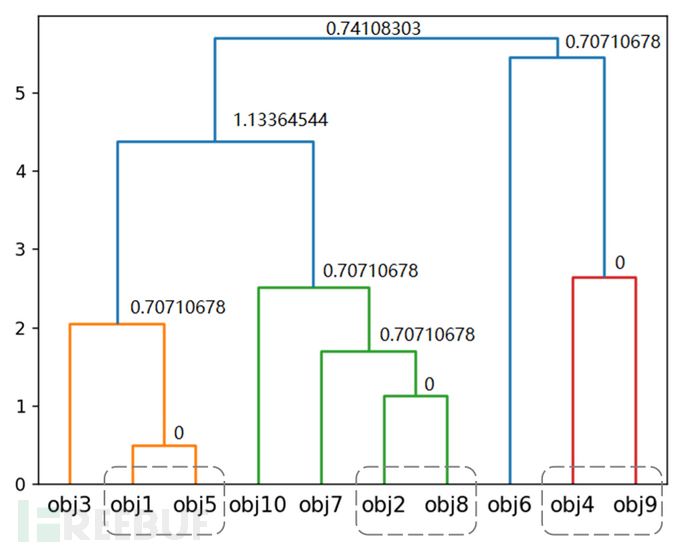
图2-26 按inconsistent标准t=0进行聚类的结果
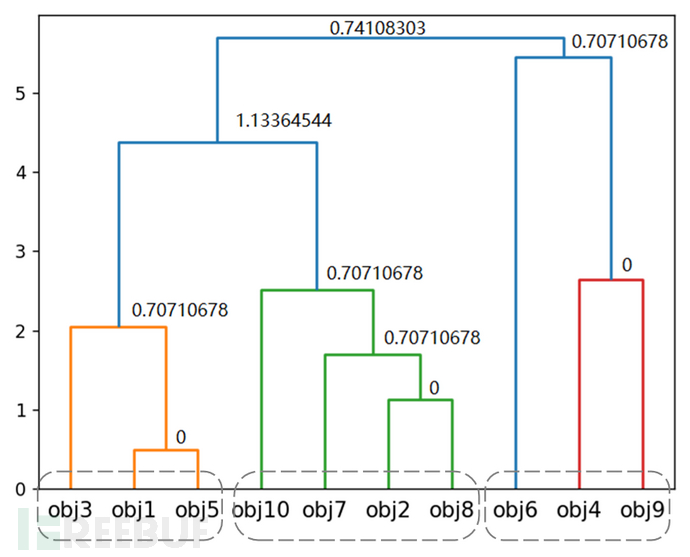
图2-27 按inconsistent标准t=0.8进行聚类的结果
题目解析
1.解法一
这是一种比较直观的解法。直接将给出的照片数据转换为一个128像素×128像素的PNG文件,然后在画图软件中打开这个PNG文件,找出表示恒星的亮点的坐标即可。这种解法的缺点是人工找点,速度慢、效率低,因为有5组照片数据要处理,所以需要反复连接服务器提交上一组答案再获取下一组数据,循环操作多次才能完成解题。具体解题过程如下:
(1)编写Python代码将照片数据转换为PNG图片文件。代码如下:
#!/usr/bin/env python3
from PIL import Image
data1 = [
[1,3,3,5,7,3,5,5,2,7,4,6,5,4,7,0,0,5,8,5,6,2,9,2,6,3,2,8,1,7,4,9,5,5,8,6,3,0,1,7,8,6,5,9,7,4,7,6,0,8,7,3,5,2,9,5,1,9,8,3,6,9,5,6,4,9,9,0,4,3,1,2,7,4,3,9,6,2,7,9,7,4,7,5,5,9,9,5,2,4,4,3,6,0,1,9,9,3,9,7,9,3,8,6,8,0,3,4,8,2,0,3,9,1,7,9,2,1,3,2,2,4,5,0,8,1,7,0],
[7,3,2,7,0,4,9,9,4,8,6,2,3,9,8,9,2,1,1,4,2,9,4,7,9,4,0,0,4,6,1,2,7,7,9,7,8,5,6,7,1,3,3,3,1,4,7,9,0,8,7,4,2,4,3,8,2,0,5,1,2,6,8,8,8,7,8,3,6,1,8,9,2,0,7,9,8,0,4,3,4,1,7,6,6,9,7,3,8,9,1,5,7,3,3,7,5,6,2,6,4,6,2,1,8,1,1,4,4,9,4,3,3,2,7,0,6,0,2,0,7,2,6,4,9,1,4,0],
......
[7,0,0,6,3,8,9,5,2,1,0,6,2,8,8,1,9,8,3,4,8,0,0,6,4,7,8,9,7,9,1,9,6,8,5,4,9,7,7,2,3,9,7,4,0,8,7,0,5,4,4,9,2,9,8,6,3,6,9,6,0,1,2,3,9,3,0,0,9,1,3,7,6,6,5,0,4,3,3,9,6,2,9,1,7,5,2,8,1,8,5,1,1,5,5,2,0,2,2,6,7,0,8,3,0,3,4,0,6,3,2,6,2,7,0,7,4,0,5,2,9,4,1,6,4,8,1,1],
[9,8,7,4,9,2,4,1,6,6,1,7,1,3,5,7,0,5,6,4,7,4,4,4,6,7,7,5,7,6,7,9,2,6,9,0,7,9,6,9,3,4,7,7,8,7,3,1,8,7,0,2,9,7,8,9,6,6,6,9,1,9,3,5,0,8,8,1,4,4,4,4,2,4,8,0,5,1,2,2,5,0,7,0,4,8,2,7,4,7,9,0,9,7,5,0,4,8,1,0,2,8,4,3,0,2,3,4,4,8,5,0,5,5,9,8,7,7,8,0,2,2,2,3,0,2,5,3],
]
#将照片数据转化为二进制字节数据
flattened1 = bytes([pixel for row in data1 for pixel in row])
image1 = Image.frombytes('L', (128, 128), flattened1) #二进制字节数据转化为Image对象
image1.save('stars1.png', 'PNG') #保存为PNG文件
得到如图2-28所示的图片(需要说明的是,由于不知道给出的数据到底是按照一行行给的,还是一列列给的,这里先假设是按照一行行给的得到的图片,如果是一列列给的,那么图片将做一个翻转)。

图2-28 centroids挑战题中由提供数据恢复的图片
(2)使用Windows的画图软件打开图片文件,如图2-29所示,左上角正是(0,0)坐标。
(3)将光标放到亮度最大的点,会在左下方显示对应的坐标(49,7),如图2-30所示,因为亮度最大的点在这附近不止一个,经过测试,选择(48,7)也可以。
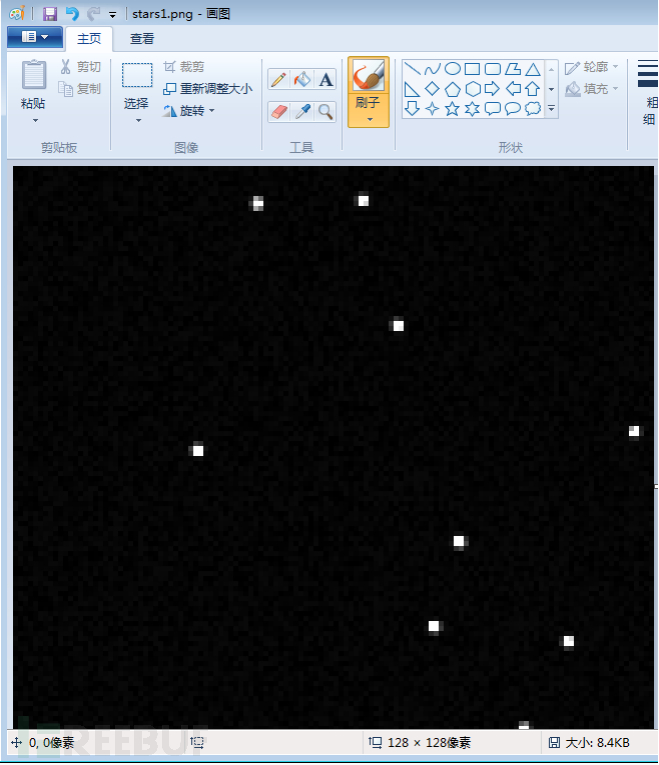
图2-29 画图软件中打开的centroids挑战题数据恢复的图片
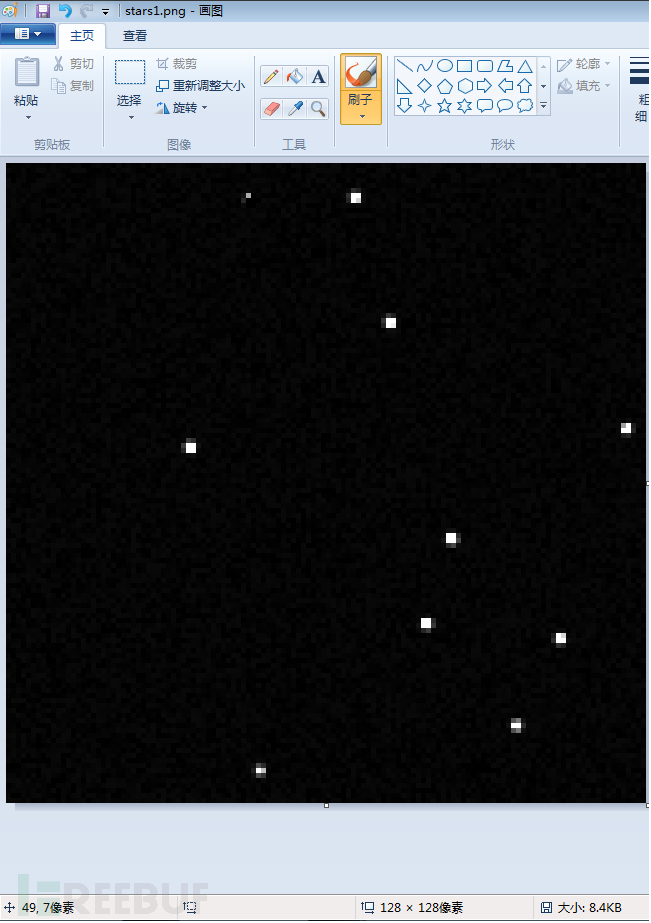
图2-30 画图软件中显示像素点的坐标
(4)将图片中所有亮点坐标找到,可以得到如下一组数据:
69,6
48,7
77,32
124,53
37,57
89,75
84,92
111,95
102,113
51,122
(5)将以上数据作为答案输出给服务器,如图2-31所示,会提示失败。
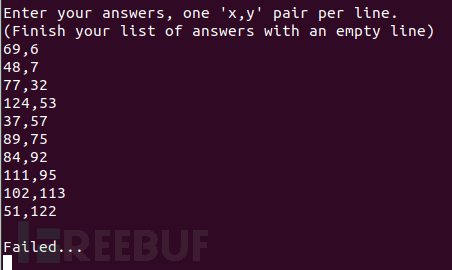
图2-31 centroids挑战题中答案输入错误后的显示
将上述坐标值交换顺序,也就是:
6, 69
7, 48
32, 77
53, 124
57, 37
75, 89
92, 84
95, 111
113, 102
122, 51
再次输出给服务器,这次顺利通过,并提示:
4 Left...
然后又会给出一组数据,重复上面的解答过程,5轮过后,即可得到flag值。
2.解法二
解法二的思路是:利用所给数据生成图片,然后取出图片中灰度值大于200的点,进行聚类运算,聚类后,再计算每类坐标的均值,4舍5入后得到最终结果。
关键代码如下,详细解释可见代码的注释。
import pwn
import numpy as np
import scipy.cluster.hierarchy as sch
from matplotlib import pyplot as plt
import itertools
# 连接服务器
rem =pwn.remote("172.17.0.1",31314, timeout=5)
for i in range(5):
# 获取照片数据
buf = rem.recvuntil(b"Enter")
buf = buf.decode()
# 将数据整理为一个二维数组
a=np.array([[int(x) for x in l.split(",")] \
for l in buf[:buf.find("Enter")].splitlines() if l])
# 使用获得的数据,进行图像绘制
plt.rcParams['figure.figsize'] = [10, 10]
plt.imshow(a) # 第一轮计算中由照片数据绘制出的图片如图2-32所示
# 显示灰度值大于200的点
plt.imshow(a > 200) # 第一轮计算中进行灰度处理后的图片如图2-33所示
# 找出灰度值大于200的点的坐标
pts=np.argwhere(a > 200)
'''第一轮计算中pts值如下:
array([[ 6, 69],[ 6, 70],[ 7, 48],[ 7, 49],[ 7, 69],[ 7, 70],
[ 31, 76],[ 31, 77],[ 32, 76],[ 32, 77],[ 52, 124],[ 53, 123],
[ 53, 124],[ 56, 36],[ 56, 37],[ 57, 36],[ 57, 37],[ 74, 88],
[ 74, 89],[ 75, 88],[ 75, 89],[ 91, 83],[ 91, 84],[ 92, 83],
[ 92, 84],[ 94, 110],[ 94, 111],[ 95, 110],[ 95, 111],[112, 101],
[112, 102],[121, 50]], dtype=int64)
'''
# fclusterdata函数用于对上面的点进行聚类
clust=sch.fclusterdata(pts,0)
'''第一轮计算中得到10类,clust值如下:
array([ 3, 3, 4, 4, 3, 3, 2, 2, 2, 2, 5, 5, 5, 1, 1, 1, 1,
6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8, 9, 9, 10], dtype=int32))
上面数字一致的表示对应的原始像素点是一类
'''
# 计算每类坐标的均值
res=[np.mean(np.array(list(itertools.compress(pts, clust==i))),axis=0) \
for i in range(1,max(clust)+1)]
'''第一轮计算中得到的10个坐标均的值res如下:
[array([56.5, 36.5]),
array([31.5, 76.5]),
array([6.5, 69.5]),
array([7. , 48.5]),
array([52.66666667, 123.66666667]),
array([74.5, 88.5]),
array([91.5, 83.5]),
array([94.5, 110.5]),
array([112. , 101.5]),
array([121. , 50.])]
'''
plt.scatter(np.array(res)[:,1],np.array(res)[:,0])
# 第一轮计算中,聚类后得到的散点图如图2-34所示
plt.imshow(a)
# 接收剩余字符,即:b" your answers, one 'x,y' pair per line.\n
# (Finish your list of answers with an empty line)\n"
rem.recv(400)
# 对计算出的坐标的均值进行4舍5入,得到最终的坐标,输出到屏幕,并发送到服务器
answer="\n".join("{0},{1}".format(*list(np.round(r).astype(int))) for r in res)
print(answer)
rem.send(answer.encode())
rem.send("\n\n".encode())
# 输出接收到的提示信息
print(rem.recv().decode())
程序运行后,输出结果如下:
[+] Opening connection to 172.17.0.1 on port 31314: Done
56,36
32,76
6,70
7,48
53,124
74,88
92,84
94,110
112,102
121,50
4 Left...
100,58
113,122
114,87
122,104
72,110
24,123
62,78
38,50
28,90
33,70
3 Left...
98,4
123,31
18,100
11,26
59,86
48,40
45,63
62,63
62,118
89,114
2 Left...
115,39
74,22
99,7
6,87
24,11
36,119
36,52
63,80
78,115
86,92
1 Left...
7,34
60,12
112,105
94,38
107,60
74,82
8,120
33,110
68,117
51,120
0 Left...
flag{1234}
[*] Closed connection to 172.17.0.1 port 31314
将上面程序输出的坐标值与2.3.2节程序测试输出的坐标值进行对比,可以发现坐标值的个数相同但每个具体坐标值并不都相同,存在±1的偏差,这说明不同的解法得到的结果会有细微差别,但这种差别在题目容许误差范围内都算正确。
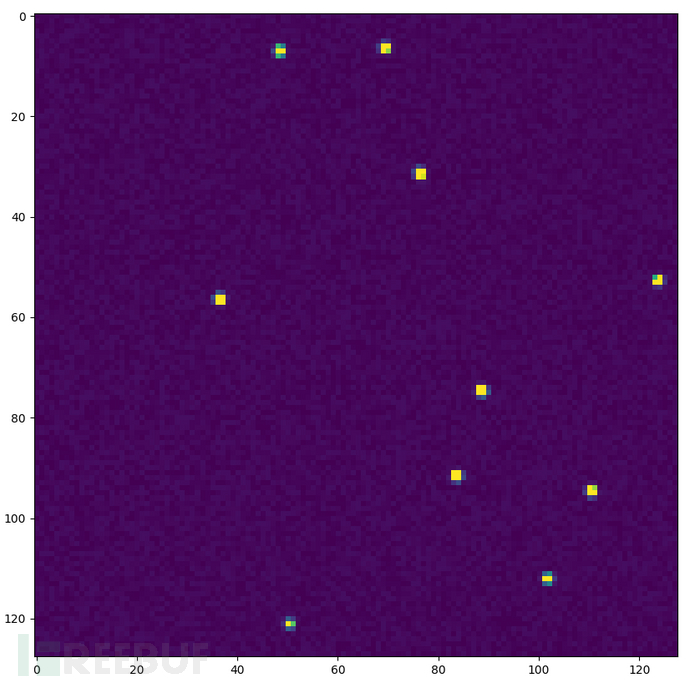
图2-32 centroids挑战题解法二中使用获得的照片数据绘制出的图片
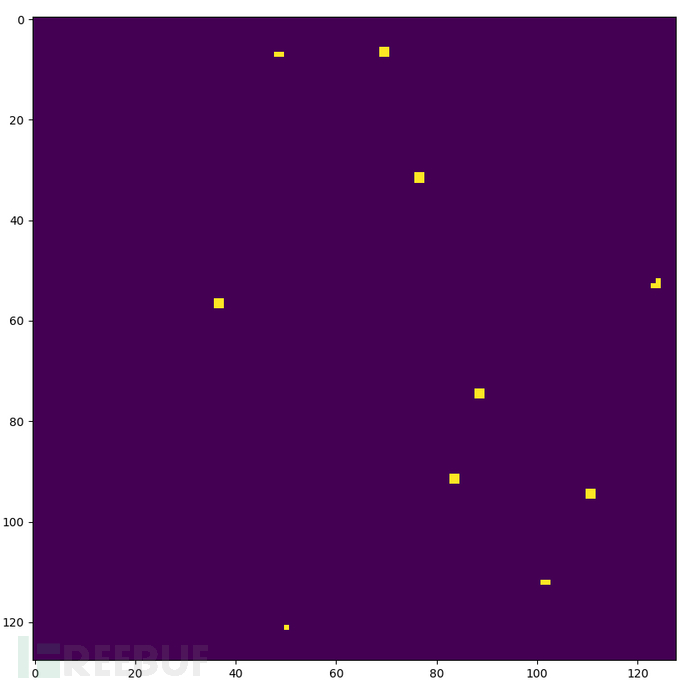
图2-33 centroids挑战题解法二图片中灰度值大于200的点的图片
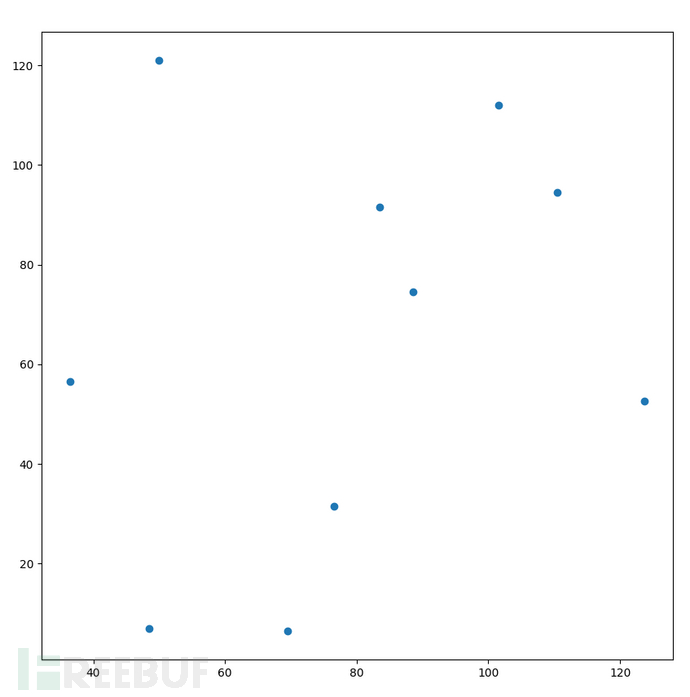
图2-34 centroids挑战题解法二聚类后得到的散点图
- 0 文章数
- 0 关注者